本文最初发表于微信官方账号《数据科学家发展记录》(微信ID: louwill12),作者卢伟经作者授权转载,禁止再次转载。
随着大数据时代的到来和对数据市场价值的认可,数据分析师、高级数据挖掘工程师甚至金字塔中的顶尖数据科学家成功吸引了无数像作者这样热血青年,成为21世纪最性感的职业。阿里“开启AI时代”的口号,足以让我们兴奋的将自己奉献给高高在上的数据科学行业。除了计算机、数学、统计学的童鞋,其他行业想转行做数据分析的人绝不是少数。但是什么是数据分析,想成为数据行业从业者需要具备哪些素质?这恐怕是大家真正需要关注的焦点。作者花了一些时间,从数据采集到清理分析,从可视化到深度数据挖掘,一套完整的数据分析和处理流程,向你展示了中国数据行业的招聘信息是什么。
一个
数据采集和清理
爬虫界似乎有这样一个传闻,每一个高级爬虫都会带走拉戈。com作为练习爬虫的对象,从而锻炼爬虫技术,了解招聘信息。拉戈和谐的结构化界面。com为大家抓取数据提供了天然的便利,受到爬虫的青睐。Lagou.com招聘信息界面如下:

在本文中,作者搜索了拉戈的相关数据工作。以“数据分析”、“数据挖掘”、“数据操作”和“数据产品管理器”为关键词,利用R语言的Rvest包和Selectorgadget插件构建了一个爬虫框架。根据职务名称(job_name)、公司名称(job_company)、城市(job_city)、工资(job_salary)、教育要求(job_edu)、经验要求(job_exp)、职务类别(job_tag)、行业类别(job_industry)、公司融资职务_培训和职务要求(jd)是捕获和清理数据的特征属性,职务要求(JD)特征只捕获数据挖掘职务的职务描述。剔除缺失值和异常记录后,拉戈1605个数据岗的招聘信息。数据如下所示:
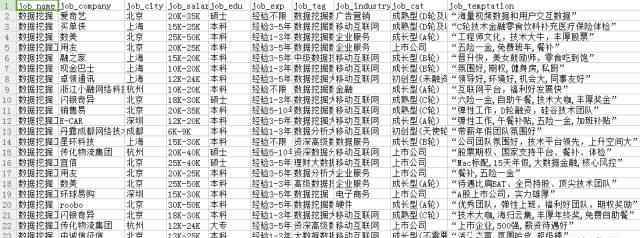
2
数据分析和可视化显示
job _薪资的字段在分析前简单处理,编写一个自定义的r函数,将其分为7个区间,0-5K,6-10k,11-15k,16-20k,21-25k,26-30k,31-100k,供后期分析。
这里的分析主要使用了两个绘图包ggplot2和plotrix。
我们先来看看数据岗位对学历的要求:
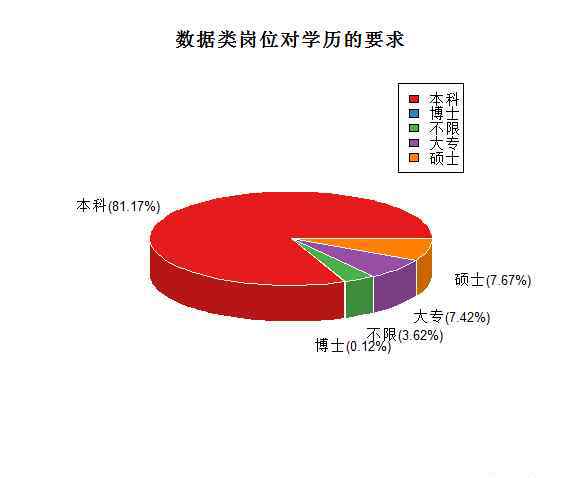
显然,对于数据类工作,本科学历要求是目前的主流,硕士和大专学历也有一定比例。有些学历不限的工作一定很看重你的行业经验,只有极少数工作需要博士学位。我们可以通过查询数据找到答案:
job_phd<。-job data[哪个(job_edu== "医生"),]
工作博士
数据职位的经验要求:
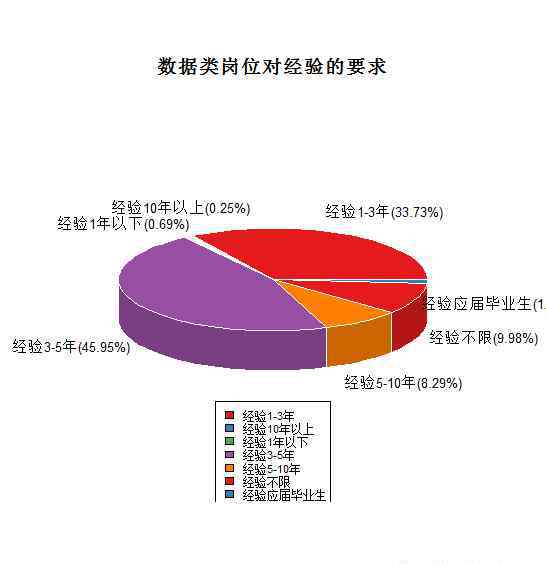
目前国内主要的数据工作是在哪些城市?
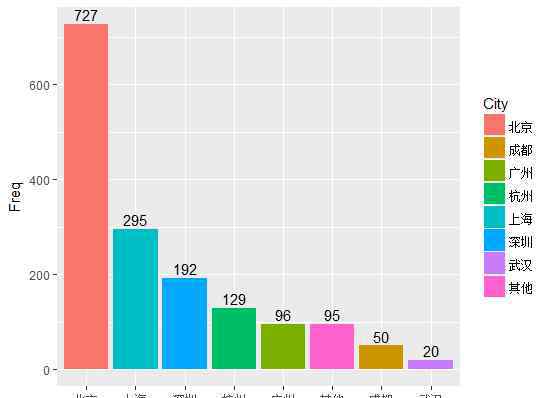
作为中国互联网行业相对发达的城市,北上广深和杭州提供的数据岗位数量占全国总量的近90%,而仅北京一个城市就提供了一半的岗位,不得不惊叹帝都对互联网人才的巨大需求。上海作为国内经济金融中心,数据人才需求排名第二。杭州由于阿里巴巴的加入领先一批互联网科技公司,对数据分析人才的需求也相当可观。广州和深圳相距不远,也有腾讯这样的互联网巨头支持,对数据人才的需求也很大。
想做数据分析,不要跑错地方。
哪些行业需要数据分析人才?
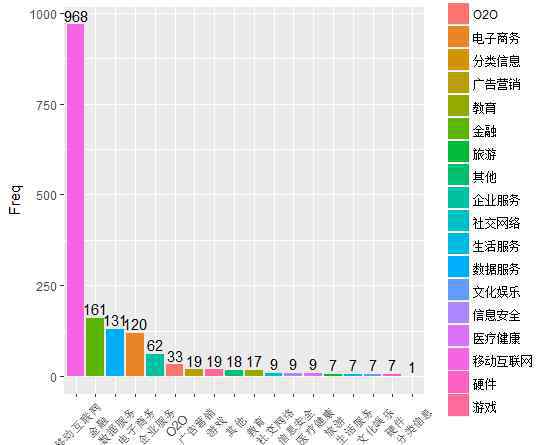
移动互联网、金融、电商行业为数据分析提供了大量的就业机会,数据行业的繁荣也相应催生了专门提供数据服务的公司,这也是需求巨大的。然而,目前传统行业对数据人才的需求并不显著。我相信随着互联网加传统行业革命的深入,会有越来越多的传统行业对数据分析有需求。
对数据分析人才有需求的企业处于怎样的发展阶段?
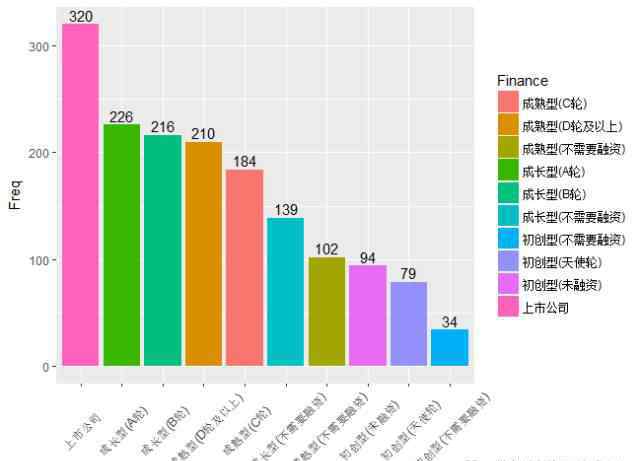
多轮融资的公司对数据帖的需求比较大,其中上市公司最多。天使轮等不需要融资的企业规模小,对数据分析和数据挖掘的需求小很多。
数据行业经验丰富是否意味着工资30K以上?
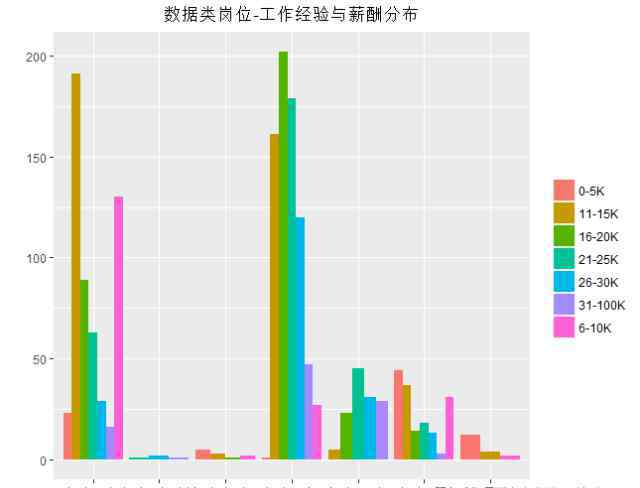
大家都愿意知道的一个事实是,数据类工作的工资通常起薪较高。高学历零经验的毕业生拿到10K工资几乎很正常,一段时间后能拿到20K到30K的人很多。就数据行业而言,1-3年经验和3-5年经验是行业热点。数据分析和数据挖掘在国内兴起时间不长,很难有资深的数据科学从业者。5-10年经验是不可能满足需求的,10年以上经验的行业更是凤毛麟角。
数据行业高学历是否意味着高薪?
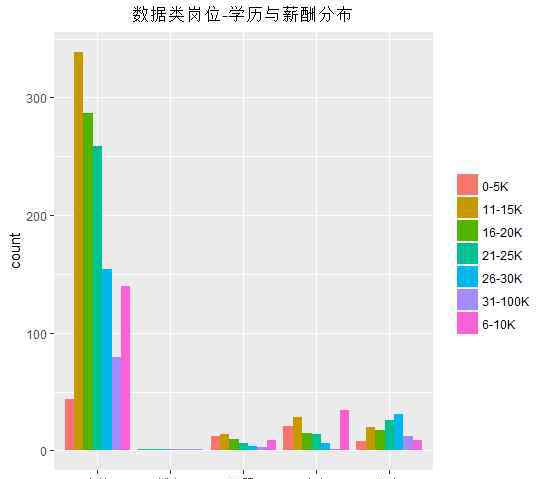
如上图,本科学历是数据行业的主流资质。对应的高学历不一定意味着超高的工资奖金。本科毕业,有一定的行业积累,拿到31-100K的工资并不少见。
不同行业提供的工资分配有什么区别?
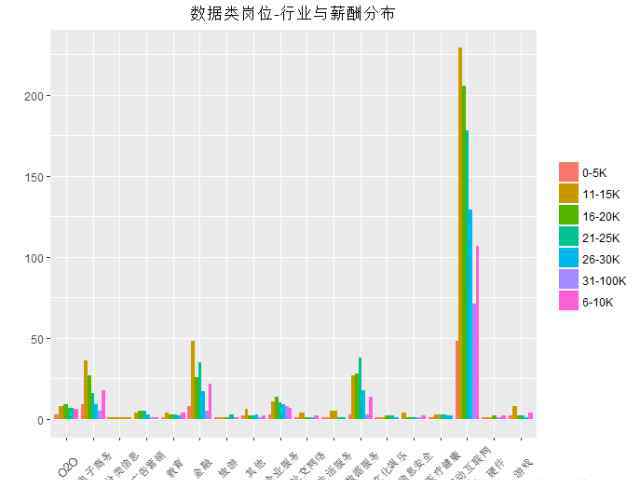
如前所述,移动互联网、金融、电子商务、数据服务行业对数据类工作的需求较高,行业和薪酬分布图再次显示了这种情况。
企业在不同融资阶段给出的薪酬分配有什么不同?
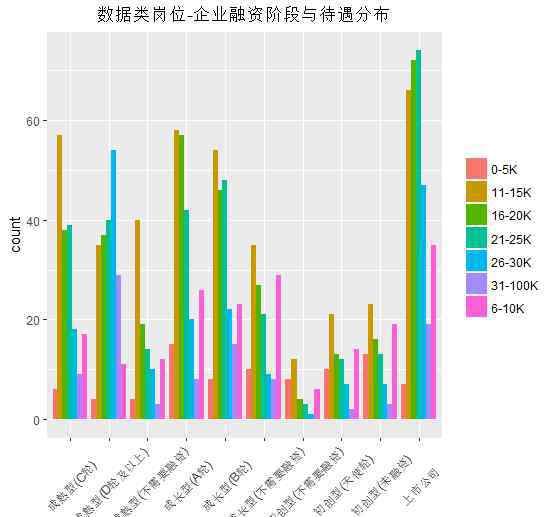
初创企业(天使轮)、初创企业(无资金)、初创企业(无融资)在发展初期和小规模状态下支付给数据人才的工资明显低于其他融资阶段企业支付的工资。成熟(D轮及以上)和上市公司明显财大气粗,敢花钱买数据人才。
三
挖掘工作优势和数据技能要求
本文将job _ training和job_JD分别提取并读入r语言,然后用jiebaR包统计词频,再用wordcloud2绘制词云图,向你展示数据行业的企业能给求职者带来什么样的福利和软件技能。
数据帖子福利关键词云图:

团队,五险一金,开发空,弹性工作时间,选项等。已经成为企业招聘数据人才的高频诱惑词。
数据科学行业岗位技能要求的词云展示;

剔除数据挖掘、数据分析等高频干扰词后的词云图像;

把上图翻译成熟悉的条形图,技能要求一目了然。因此,当我们谈论数据挖掘时,我们谈论以下内容。
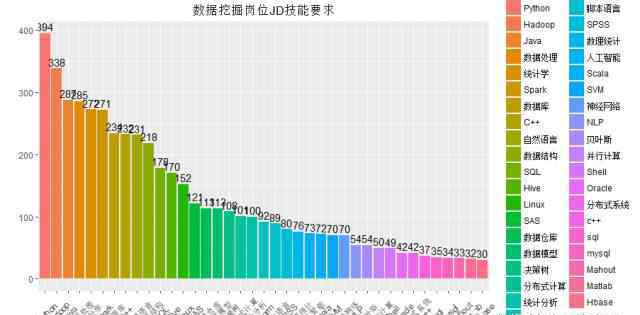
Python、R、Hadoop、Java、Spark、C++、SQL、Linux、Hive等数据科学工具和编程语言是企业对数据人才的一致要求。统计分析、数据结构、决策树等一些理论概念和算法也在企业对数据人才的要求之中。想从事数据挖掘工作,可以慎重!好好学习理论,认真实践技术,高薪不再遥远!(图中没有r的频率,因为作者很难用其他工具分词,所以这里没有r。其实JD中r的出现频率是370倍,仅次于Python,所以r和Python是数据科学从业者的两把剑,希望大家好好打磨。)
全过程实现代码-
#加载所需的包
库(xml2)
库(rvest)
库(ggplot2)
库(stringr)
库(dplyr)
库(plotrix)
库(RColorBrewer)
库(jiebaR)
库(wordcloud2)
#设置已爬网页面的数量并创建数据框
i<。-1:30
job_inf<。-data.frame()
#用于循环来抓取批处理数据
for (i in 1:30){
web<。-read _ html(str _ c(" https://www . lagou . com/zhaopin/shujuwajue/",I),encoding="UTF-8 ")
job _ name & lt-web% >;%html_nodes("h2")% >%html_text()
job _ name[16]& lt;-北美
job _ name & lt-job_name[!is.na(job_name)]
职务_公司<。-web% >;%html_nodes(" .company_name a")%>。%html_text()
job_city<。-web% >;%html_nodes("em")%>。%html_text()
job _ city[16]& lt;-北美
job _ city[17]& lt;-北美
job_city<。-job_city[!is.na(job_city)]
job_inf1<。-web% >;%html_nodes(" .p_bot。li_b_l")% >%html_text()
job _ tag & lt-web% >;%html_nodes(" .list_item_bot。li_b_l")% >%html_text()
job_inf2<。-web% >;%html_nodes(" .行业")% >;%html_text()
工作诱惑<。-web% >;%html_nodes(" .li_b_r")% >%html_text()
#创建一个数据框来存储上述信息
工作<。-data.frame(job_name,job_company,job_city,job_inf1,job_tag,job_inf2,job _诱惑)
job_inf<。-rbind(job_inf,job)
}
#将数据写入csv文档
write.csv(job_inf,file = " D:/Rdata/dataset/job _ INF . CSV ")
#读取数据
jobdata<。-read . CSV(" C:/Users/Administrator/Desktop/job _ data . CSV ")
主管(jobdata)
附加(jobdata)
#处理职务_薪资字段
job _薪资<。-as.factor(职务_工资)
属性(职务_工资)
阈值<。-列表(
c("1K-2K "、" 2K-3K "、" 2K-4K "、" 3K-4K "、" 3K-5K "、" 3K-6K ",
“4K-6K”、“4K-7K”、“4K-5K”),
c("4K-8K "、" 5K-6K "、" 5K-7K "、" 5K-8K "、" 5K-9K "、" 5K-10K "、" 6K-10K "、" 6K-12K ",
“6K-8K”、“6K-9K”、“7K-10K”、“7K-12K”、“7K-13K”、“7K-14K”、“7K-8K”、“7K-9K”,
“8K-10K”、“8K-12K”、“8K-13K”),
c("8K-14K "、" 8K-15K "、" 8K-16K "、" 9K-13K "、" 9K-15K "、" 9K-16K ",
“9K-18K”、“10K-12K”、“10K-14K”、“10K-15K”、“10K-16K”、“10K-17K”、“10K-18K”,
“10K-19K”、“10K-20K”、“11K-15K”、“12K-15K”、“12K-16K”、“12K-18K”),
c("12K-20K "、" 12K-22K "、" 12K-24K "、" 13K-18K "、" 13K-19K ",
“13K-20K”、“13K-22K”、“13K-23K”、“13K-25K”、“13K-26K”、“14K-17K”、“14K-20K”,
“14K-25K”、“14K-27K”、“14K-28K”、“15K-18K”、“15K-20K”、“15K-22K”、“15K-25K”,
“15K-26K”、“16K-20K”),
c("15K-28K "、" 15K-30K "、" 16K-24K "、" 16K-28K "、" 16K-30K "、" 16K-32K "、" 18K-22K ",
“18K-25K”、“18K-28K”、“18K-30K”、“20K-25K”、“20K-28K”、“20K-30K”),
c("17K-33K "、" 17K-34K "、" 18K-35K "、" 18K-36K ",
“19K-38K”、“20K-35K”、“20K-38K”、“20K-40K”、“25K-30K”、“25K-35K”),
c("21K-42K "、" 22K-40K "、" 23K-45K "、" 24K-35K "、" 25K-40K "、" 25K-45K "、" 25K-50K ",
“28K-35K”、“30K-35K”、“30K-40K”、“30K-45K”、“30K-50K”、“28K-55K”,
“30K-60K”、“35K-40K”、“35K-50K”、“35K-55K”、“35K-70K”,
“40K-60K”、“40K-80K”)
)
#工资分为以下七个区间
job _薪金<。-c(“0-5K”、“6-10K”、“11-15K”、“16-20K”、“21-25K”、“26-30K”、“31-100K”)
获取薪资映射<。-函数(行){
job _薪资<。-as.character(第[4]行)
结果<。-c()
for(i in 1:length(thresholds)){
结果<。-grep(job _薪金,阈值[[i]])
if(长度(结果)!= 0){
回报(工作薪水[i])
打破
}
}
回报(职务_工资)
}
#替换原始职务_工资列
jobdata$job_salary<。-应用(jobdata,1,GetSalaryMapping)
job _薪资<。-as.factor(jobdata$job_salary)
#学历的数据岗位要求
教育<。- data.frame(表格(job_edu))
教育.资格& lt- as.factor(教育$job_edu)
myLabel <。-粘贴(education.qualifications,"(",",round(education $ Freq/sum(education $ Freq)* 100,2," ")",sep = " " "
pie3D(
x =教育$Freq,标签= myLabel,
explode= 0,
半径= 0.85,
高度= 0.11,
border = "white ",col = brewer.pal(5," Set1 "),
labelcex = 0.85,
Main = "数据工作的学历要求"
)
图例(" topright ",插图= 0.02,图例= c("本科","博士","不限","大专","硕士"),
cex=0.8,fill=brewer.pal(5," Set1 "))
#经验的数据发布要求
体验<。- data.frame(table(job_exp))
经验、资格& lt- as.factor(experience$job_exp)
myLabel <。-粘贴(experience.qualifications,"(",",round(experience $ Freq/sum(experience $ Freq)* 100,2," ")",sep = " " "
pie3D(
x = experience$Freq,labels = myLabel,
explode= 0,
半径= 0.85,
高度= 0.11,
border = "white ",col = brewer.pal(5," Set1 "),
labelcex = 0.85,
Main = "数据发布的经验要求"
)
图例("底部",插图=-0.03,图例= c("经验1-3年","经验10年以上","经验不足1年",
“经验3-5年”,“经验5-10年”,“经验不限”,“经验丰富的应届毕业生”),cex = 0.66,fill = brewer.pal (5,“set1”))
#数据工作的城市分布
count.city & lt- data.frame(表格(jobdata$job_city))
姓名(count . city)& lt;- c(“城市”、“Freq”)
count.city & lt-count . city[order(count . city $ Freq,reducing = T),]
row name(count . city)& lt;-空
#从第八名开始的城市被归类为其他
tmp <。-count . city[8:dim(count . city)[1],]
count.city & lt- count.city[1:7,]
count.city & lt- rbind(count.city,data.frame(
City =“其他”,
Freq =总和(tmp$Freq)
))
count.city & lt- data.frame(count.city)
attach(count.city)
ggplot(count.city,aes(reorder(City,-Freq),Freq,fill = City))+geom _ bar(stat = " identity ")+xlab(
“City”)+geom _ text(AES(label = Freq),hjust=0.5,vjust=-0.3)
#公司融资状况分布
company.finance <。-data . frame(table(job data $ job _ cat))
名称(company.finance) <。- c(“财务”、“财务”)
company.finance <。-company . finance[order(company . finance $ Freq,reducing = T),]
attach(company.finance)
ggplot(company.finance,aes(reorder(Finance,-Freq),Freq,fill = Finance))+geom _ bar(stat = " identity ")+xlab(
“Finance”)+geom _ text(AES(label = Freq),hjust=0.5,vjust=-0.3)+theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#行业分布
附加(jobdata)
行业<。- as.factor(job_industry)
行业<。- data.frame(表格(行业))
行业<。-行业[订单(行业$Freq,递减= T),]
rownames(industry) <。-空
ggplot(industry,aes(reorder(industry,-Freq),Freq,fill = industry))+geom _ bar(stat = " identity ")+xlab(
" industry ")+geom _ text(AES(label = Freq),hjust=0.5,vjust=-0.3)+theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#工作经验和工资分配
ggplot(jobdata,aes(x = job_exp,fill = job_salary)) +
geom_bar(stat = "count ",position = "道奇")+
theme_grey() + labs(x = ",y = ")+
主题(legend.title = element_blank()) +
Ggtitle("数据职位-工作经验和工资分配")+
主题(plot . title = element _ text(hjust = 0.5))
#行业和薪酬分配
ggplot(jobdata,aes(x = job_industry,fill = job_salary)) +
geom_bar(stat = "count ",position = "道奇")+
theme_grey() + labs(x = ",y = ")+
主题(legend.title = element_blank()) +
Ggtitle("数据职位-行业和工资分配")+
主题(plot . title = element _ text(hjust = 0.5))+
主题(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#教育和工资分配
ggplot(jobdata,aes(x = job_edu,fill = job _薪金))+
geom_bar(stat = "count ",position = "道奇")+
theme_grey() + labs(x = ",y = "count") +
主题(legend.title = element_blank()) +
Ggtitle("数据职位-教育和工资分配")+
主题(plot . title = element _ text(hjust = 0.5))
#企业融资阶段及待遇分配
ggplot(jobdata,aes(x = job_cat,fill = job_salary)) +
geom_bar(stat = "count ",position = "道奇")+
theme_grey() + labs(x = ",y = "count") +
主题(legend.title = element_blank()) +
Ggtitle("数据岗-企业融资阶段及待遇分配")+
主题(plot . title = element _ text(hjust = 0.5))+
主题(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#工作福利的分析和挖掘
tp<。-扫描(" C:/Users/Administrator/Desktop/data job _ TP . txt ",sep="n ",what= ",encoding="UTF-8 ")
tp<。-str_replace_all(tp," n ","")
头部(tp)
#分词
Mixseg<。-工人()
tp<。-分段(tp,Mixseg)
长度(tp)
tp<。-tp[nchar(tp)>;1 & ampnchar(tp)和lt。10]
tp _ word & lt-排序(表格(tp),递减=T)[1:100]
#岗位福利词云图
wordcloud2(tp_word,size = 1,shape = '五边形')
#工作描述的分析和挖掘
jd<。-扫描(" C:/Users/Administrator/Desktop/data job _ JD . txt ",sep= ",",what= ",encoding="UTF-8 ")
主管(jd)
#分词
mixseg<。-工人()
jd<。-细分市场(jd、mixseg)
长度(jd)
jd<。-jd[nchar(jd)>;2 & ampnchar(jd)和lt。8]
jd _ word & lt-排序(表格(jd),递减=T)[1:100]
#职位描述云图
wordcloud2(jd_word,size = 1,shape = '五边形')
#去掉数据挖掘和数据分析两个高频词后的词云
JD _ word[1]& lt;-北美
JD _ word[2]& lt;-北美
jd_word2<。-jd_word[!is.na(jd_word)]
wordcloud2(jd_word2,size = 1,shape = '五边形')
#生成高频单词的条形图
jd_word[c(3,4,6,7,9,18,20,21,26,29,31,32,33,35,37,39,42,43,44,49,55,56,
57,59,60,61,62,63,64,66,67,68,69,70,72,74,75,76,77,80,83,84,86,88,89,90,91,
92,94,95,96,97,98,99,100]& lt;-北美
jd_word3<。-jd_word[!is.na(jd_word)]
jd_word3<。-as.data.frame(jd_word3)
ggplot(jd_word3,aes(x =jd_word3$jd,y = jd_word3$Freq,fill = jd)) +
geom_bar(stat = "identity") +
labs(x = ",y = ")+
主题(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))+
geom_text(aes(label=Freq),hjust=0.5,vjust=-0.3) +
Ggtitle ("JD数据挖掘帖子高频词")+
主题(plot . title = element _ text(hjust = 0.5))
#进行关联分析
#企业对不同工作资历应聘者的要求
workyear.empty & lt-dplyr:: filter(职务数据,job _ exp = = "经验无限")
工作年。大一& lt-dplyr:: filter(工作数据,工作年份= = "有经验的应届毕业生")
workyear.oneyear <。-dplyr:: filter(工作数据,工作年= = "经验不足1年")
工作年。三年<。-dplyr:: filter(工作数据,工作年= = "经验1-3年")
工作年。五年<。-dplyr:: filter(工作数据,工作年= = " 3-5年经验")
workyear.tenyear <。-dplyr:: filter(工作数据,工作年= = "经验5-10年")
work year . over enyear & lt。-dplyr:: filter(工作数据,工作年= = " 10年以上经验")
参考文献:
1数据分析师职业发展白皮书(2015年版)
2 https://github.com/edvardHua/JobRequirementAnalysis.
工作
哦
简单的
介于
卢伟,个人微信官方号:数据科学家记录(微信ID: louwill12)。数据科学从业者的研究日记。数据挖掘与机器学习,R与Python,理论与实践并行。
结束
请发送电子邮件到holly0801@163.com提交和反馈。微信官方账号转载大数据文章请向原作者申请授权,否则任何版权纠纷都与大数据无关。
大数据
为您提供与大数据相关的最新技术和信息。
最近的精彩文章(直接点击查看):
161224
161222
161216
161213
161208
161206
161205
161129
161126
161122
161119
161114
161112
161108
161107
161105
161028
161025
161023
161016
161014
161009
161001
更多精彩文章,请在公众号后台点击“历史文章”查看,谢谢。1.《30k是多少钱 用数据分析告诉你数据分析师能挣多少钱》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《30k是多少钱 用数据分析告诉你数据分析师能挣多少钱》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1177163.html


