编者按:如果你想深入学习,增强学习能力,请查看Marcos Campos在2017年9月17-20日于旧金山举行的O'Reilly人工智能大会上给出的教程《增强学习导论》。你可以在贾斯汀·弗朗西斯的GitHub上找到这篇博文中显示的代码。
那些对机器学习世界感兴趣的人已经意识到了基于强化学习的人工智能的能力。在过去的几年里,强化学习(RL)的使用在许多方面取得了突破。DeepMind将深度学习与强化学习相结合,在许多雅达利游戏中实现卓越的性能。2016年3月4:1击败围棋冠军李世石。虽然RL目前在很多游戏环境中表现不错,但它是一种全新的解决需要最优决策和效率的问题的方法,在机器智能中肯定会发挥作用。
OpenAI成立于2015年底,是一家非营利组织。其目的是“建立一个安全的人工通用智能(AGI),并确保AGI的利益尽可能广泛和均衡地分配”。除了探索关于AGI的许多问题,OpenAI对机器学习世界的一个主要贡献是开发健身房和宇宙软件平台。
Gym是为测试和开发RL算法而设计的一组环境/任务。它消除了用户创建复杂环境的需要。健身房是用Python写的,有很多环境,比如机器人模拟或者雅达利游戏。它还提供了一个在线排行榜,供人们将结果与代码进行比较。
简单来说,RL是一种计算方法。在这种方法中,代理通过采取行动最大化累积的回报来与环境交互。下面是一张简单的图,后面我会经常提到。
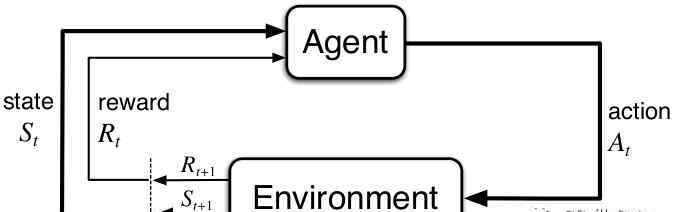
图1增强学习:简介,第二版。来自理查德·萨顿和安德鲁·巴尔托,批准使用
处于当前状态(St)的代理对环境的反应和响应采取行动(At),然后返回到新的状态(St+1)并奖励代理的行动(Rt+1)。考虑到更新的状态和奖励,代理选择下一个动作,并在循环中重复它,直到环境任务被解决或终止。
OpenAI的健身房就是基于这些基本原则。所以让我们先安装健身房,看看它与这个循环有什么关系。我们用Python和Ubuntu终端安装健身房(你也可以根据GitHub上健身房的介绍使用Mac电脑)。
sudo apt-get install-y python 3-numpy python 3-dev python 3-pip cmake zlib 1g-dev libjpeg-dev xffb libav-tools xorg-dev python-OpenGL lib boost-all-dev libsdl 2-dev swig
cd ~
git克隆https://github.com/openai/gym.git
cd健身房
sudo pip3 install -e '。[全部]'
接下来,我们可以在我们的终端上运行Python3并导入健身房。
python3
进口健身房
首先,我们需要一个环境。作为我们的第一个例子,我们将介绍一个非常基本的出租车环境。
env =健身房. make("Taxi-v2 ")
为了初始化环境,我们必须重置它。
env.reset()
您会注意到重置环境将返回一个整数。这个数字是我们的初始状态。在这种滑行环境中,所有可能的状态都由0到499的整数表示。我们可以使用以下命令来确定可能状态的总数:
env.observation_space.n
如果要可视化当前状态,请键入以下内容:
env.render()
在这种环境下,黄色方块代表出租车,(“|”)代表一面墙,蓝色字母代表搭载乘客,紫色字母代表下车乘客,出租车内有乘客时会变成绿色。当我们看到代表环境的颜色和形状时,算法不会像我们一样思考,它只会理解一个平坦的状态,在这个例子中是一个整数。
现在我们已经加载了环境并知道了当前状态,让我们来探索代理的可用操作。
env.action_space.n
该命令显示总共六个可用操作。健身房不会一直告诉你这些动作的含义,但是在这个场景中,六个可能的动作是:下(0)、上(1)、左(2)、右(3)、接乘客(4)、放下乘客(5)。
为了学习方便,我们把当前状态改写为114。
env.env.s = 114
env.render()
现在我们让出租车前进。
环境步骤(1)
env.render()
您会注意到这个env.step(1)操作将返回4个变量。
(14,-1,False,{'prob': 1.0})
我们将在后面对这些变量进行如下定义:
状态,奖励,完成,信息=环境步骤(1)
这四个变量是:新状态(St+1= 14)、奖励(Rt+1= -1)、指示环境是终止还是完成的布尔值以及附加调试信息。每一个健身房环境在行动后都会返回同样的四个变量,因为它们是增强学习问题的核心变量。
看渲染的环境。如果向左走,你希望环境回归什么?当然,你会得到和以前一样的奖励。对于每一步,环境总是给出-1的奖励,这样代理可以尝试找到最快的解决方案。如果衡量你累计的奖励总量,连续撞墙会严重惩罚你的最终奖励。环境会给你一个-10的回头率,每次上下车不正确。
所以,如何才能解决这个环境的任务呢?
解决这个环境问题的一个令人惊讶的方法是从六种可能的行动中随机选择一种。当你能成功的接一个乘客,把它放到他们想去的地方,这个环境的任务就被认为解决了。一旦实现,你将获得20点奖励,完成变量将变为真。经过多次随机行动后,你可能会幸运地完成任务。虽然概率小,但也不是不可能。评估每个代理的性能的一个核心部分是将它们与具有随机动作的代理进行比较。在健身房的环境中,可以使用env.action_space.sample()选择随机动作代理。您可以创建一个循环,让代理随机行动,直到任务得到解决。我们可以在循环中添加一个计数器,看看需要多少步骤来解决环境任务。
state = env.reset()
计数器= 0
奖励=无
同时奖励!= 20:
状态,奖励,完成,info = env . step(env . action _ space . sample())
计数器+= 1
打印(计数器)
有些人可能很幸运能在短时间内解决任务。但是平均来说,一个完全随机的策略需要2000多个步骤来解决一个任务。因此,如果我们想在未来获得最大的回报,就必须让算法记住自己的行动和回报。这种情况下,算法的内存会变成一个Q动作值表。
为了将来管理这个Q表,我们将使用一个NumPy数组列表。列表的大小是状态数(500)乘以可能动作数(6),即500×6。
将numpy导入为np
q = NP . zeros([env . observation _ space . n,env.action_space.n])
在多次尝试解决任务后,我们将更新Q值,并逐步提高我们算法的效率和性能。我们也希望跟踪每一轮的累计奖金值,我们定义为g。
G = 0
类似于大多数机器学习问题,我们仍然需要一个学习率。我会用我个人最喜欢的0.618,这也是数学的黄金分割常数π。
α= 0.618
接下来,我们可以实现最基本的Q值学习算法。
对于范围内的剧集(1,1001):
完成=假
g,奖励= 0,0
state = env.reset()
完成后!=真:
action = np.argmax(Q[state]) #1
状态2,奖励,完成,信息= env.step(动作)#2
Q[状态,动作] += alpha *(奖励+NP . max(Q[状态2])–Q[状态,动作]) #3
G +=奖励
state = state2
如果剧集% 50 == 0:
打印('第{}集总奖励:{} '。格式(剧集,G))
光是这些代码就能解决这个出租车环保任务。里面有很多代码,我来分解解释一下。
注(#1):该代理使用argmax函数为当前状态选择Q值最高的动作。argmax函数返回一个状态的最高值的索引/动作。一开始我们Q表的值都是0。但是每走一步,每个状态-动作组的Q值都会更新。
注(#2):代理采取这个动作,然后我们将未来状态保存为状态2 (St+1)。这将允许代理将以前的状态与新的状态进行比较。
注(#3):使用奖励更新状态-动作组的Q值(St,At)和状态2的最大Q值(St+1)。此更新使用动作值公式(基于贝尔曼方程),并允许以递归方式(基于未来值)更新状态-动作组。循环更新的公式如图2所示。
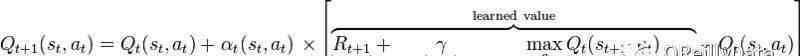
图2 Q值的递归更新。来源:Gregz448,CC0,基于维基共享授权
更新完成后,我们更新整体奖励值g,并将状态(St)更新为之前的状态2(St+1)。这样就可以重新开始循环,决定下一步的行动。
经过多轮后,算法最终会收敛,这样每个状态的最优动作就可以由Q表来确定,以保证最大的奖励值。到这个时候,我们认为环境任务已经解决了。
现在,我们已经解决了一个非常简单的环境任务。那我们来试试更复杂的雅达利游戏环境——Pacman(小黄人吃豆)
env = gym.make("MsPacman-v0 ")
state = env.reset()
您会注意到env.reset()返回了一个非常大的数字列表。更具体地说,您可以键入state.shape来显示这个状态是210x160x3的张量。它代表雅达利游戏中由长度、宽度和三个RGB颜色通道组成的像素。像以前一样,你可以想象这个环境。
env.render()
和以前一样,我们可以看看所有可能的行动:
env.action_space.n
我们有九个可能的动作:整数0-8。需要注意的是,代理并不知道每个动作意味着什么。它的工作是学习哪种行为将优化奖励。但是对于我们的理解,我们可以:
env . env . get _ action _ means()
结果显示代理可以选择9个动作:不做,8个可以在游戏手柄上做的动作。
使用我们之前的策略,让我们首先看看随机代理的性能。
state = env.reset()
奖励,信息,完成=无,无,无
完成后!=真:
状态,奖励,完成,info = env . step(env . action _ space . sample())
env.render()
完全随机的策略最多能打几百分,永远过不了第一关。
继续,现在基本的Q表算法不能用了。因为有33,600个像素点,所以每个点都有3个介于0和255之间的随机整数RGB值。很容易看出事情变得极其复杂。深度学习可以用来解决这个问题。利用卷积神经网络或DQN,机器学习库可以将复杂的高维像素矩阵转化为抽象表达式,并将该表达式转化为优化动作。
综上所述,你现在已经有了一些基础知识,知道如何使用健身房做一些基于别人(甚至是你自己)算法的实验。如果你想得到这篇博文中用到的代码,并去做或者编辑,可以在我的GitHub上找到。
随着解决环境问题的新方法和更好方法的出现,RL领域正在迅速扩大。到目前为止,A3C方法是最流行的方法之一。强化学习很可能会在未来的人工智能中发挥更重要的作用,并将继续产生非常有趣的结果。
这篇文章最初以英文出现:“强化学习和OpenAI健身房介绍”。

贾斯汀·弗朗西斯
贾斯汀住在加拿大西海岸的一个小农场里。这个农场侧重于公园人的道德和设计的农学。在此之前,他是一家非营利社区合作社自行车店的创始人和教育家。在过去的两年里,他住在一艘帆船上,全职探索和体验加拿大的乔治亚海峡。但现在他的主要精力放在了学习机器学习上。
在纽约和旧金山成功售罄门票后,由O'Reilly主持的人工智能大会将于2018年4月10-13日来到北京。目前,主讲人正在征集:https://ai.oreilly.com.cn/ai-cn.
话题收集截止日期:11月7日

1.《gym 增强学习和OpeAI Gym的介绍:基础增强学习问题的演示》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《gym 增强学习和OpeAI Gym的介绍:基础增强学习问题的演示》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/881166.html


