刘畅1 贺永明1
1. 苏州大学附属第一医院心内科
长久以来,人类已经习惯了对事物的探究以及对其奥秘的揭示。医学作为人类的重大课题,前赴后继的努力使今天的医学大厦直入天际。对疾病发展趋势的把握及其危险因素的界定,使我们对抗疾病充满信心。
疾病发生发展存在太多的危险因素,对潜在危险因素的甄别和判定对疾病的预防和治疗意义重大。在医学研究,尤其是流行病学,我们更多地借助于统计学帮助我们分析研究因素对疾病的作用。而其中,对于研究变量是否与疾病相关,是否存在阈值效应,以及发病风险随研究变量的变化趋势是我们在流行病或者临床研究中的所要解决的问题。笔者根据自己对临床研究的经验和理解,对阈值的判断以及趋势检验方面的问题给出自己的见解,抛砖引玉,与大家分享学习。
阈值效应:1. 阈值效应的判断方法
在中国汉语词典中,阈值被定义为:在自动控制系统中能产生一个校正动作的最小输入值或刺激引起应激组织反应的最低值。而在生理学及医学领域,阈值更是为我们所熟知,如动作电位的阈电位以及糖尿出现的肾糖域等。阈值的设立为我们理解和把握一系列生理过程及疾病进展变化提供了有力的帮助。
在病例-对照研究中,我们确定一个研究因素后,不可避免得要考虑其他因素即混杂因素的影响,目前最常用的方法为利用Logistic回归构建拟合模型,校正混杂因素,进而量化各变量对疾病的影响。同样,在Logistic回归分析中,研究变量对疾病作用的阈值问题值得我们深思和探讨。通过阅读相关文献,笔者发现以往对于阈值的分析只限于跳跃性选取几个研究变量的节点,并以该节点为界进行二分类,进而得出相对风险比,以此判定阈值的存在与否。笔者认为这样简单依据某几个点的相对风险,并不能真正准确反映出疾病发病风险与研究变量水平之间的关系,因此得出的所谓的阈值效应,其说服力也就相对较弱,所得的结论不准确甚至是错误的。究竟应该以怎样的方式确定阈值效应呢?笔者从可兴奋细胞的动作电位得到些许启示。动作电位大家都十分熟悉,此处以心肌细胞为例(图1)。阈电位的发现是基于对膜电位水平的描记,通过直观的观察膜电位变化图形,即可发现,在膜电位连续变化的过程中,当刺激使膜电位复极达到某个值时,动作电位才会发生,小于达到该膜电位的刺激只会使膜电位产生小幅度的波动,并不会产生趋势上的变化。因而我们将该膜电位定义为阈电位,对应的刺激大小为阈刺激。也就是说,阈值是自变量达到某个节点水平后,因变量的变化趋势发生明显的本质上的改变。与此相似,笔者认为对于研究变量,尤其是连续型的研究变量,当探究其对发病率的影响的阈值效应时,也应该进行连续的多点估计,通过线性得观察随着研究变量水平的变化,疾病发病风险的变化趋势,进而确定是否存在阈值,以及阈值的确切数值。
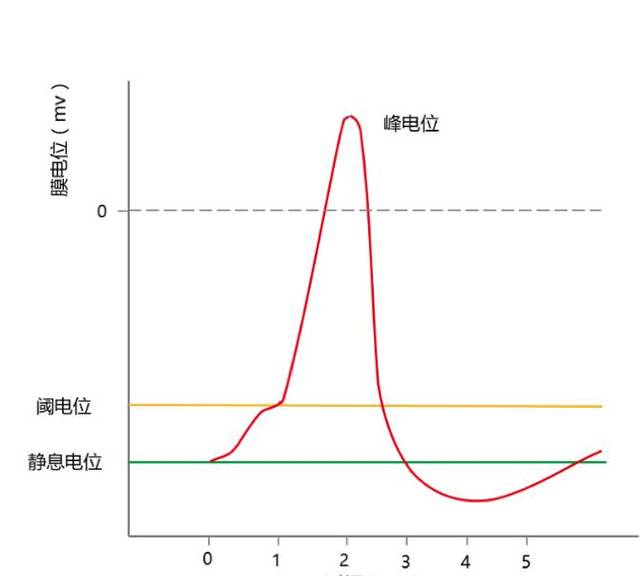
图1
例如,血清Lp(a)浓度与2型糖尿病(T2DM)关系的研究中,在WHS(Women’s Health Study)人群中,研究认为Lp(a)浓度与T2DM的发生存在反向相关关系,并在Lp(a)浓度上四分位中(<39mg/L)进一步探究阈值效应[1]。分别以10、20、30、40mg/L,作为二分类分割点,以大于等于分割点浓度组作为参照计算相对风险比,并发现所有的结果均具有统计学意义(p<0.05)。进而得出血清中Lp(a)的相对缺乏可能会增加T2DM的患病风险的结论。然而,我们在中国汉族人群中求证血清Lp(a)浓度对T2DM的阈值效应时却得出了不同的结论[2]。我们将浓度≤50mg/L的Lp(a)以1mg/L为间距进行50等分,获取50个连续的二分类分割点,并以浓度小于等于分割点组作为参照,连续得获得相应分割点的相对风险比,以类似动作电位描记的形式给出(图2。其中,对T2DM的点估计以黑色正方形表示,对CAD的点估计以黑色三角形表示)。图中我们可以看到,随着Lp(a)浓度分割点水平的变化,2型糖尿病的发病风险OR值及其95%置信区间基本上处于“1”的波动范围之内,即Lp(a)浓度水平与2型糖尿病的发病无关,整体趋势平稳变化,并无所谓的阈值效应。同时,我们也对Lp(a)对冠心病(CAD)发病风险的阈值效应进行了探究,可以看出,血清Lp(a)浓度与CAD显著相关,但随着分组分割点的变化,CAD的发病风险也未表现出明显的变化趋势,亦无阈值效应,这与以往的研究结果相一致。值得注意的是,在分割点10、20mg/L处,低浓度的Lp(a)的确表现出对2型糖尿病的风险,与WHS人群的研究吻合,但在30、40mg/L分割点处,Lp(a)浓度与T2DM的发病无关,这与WHS人群的研究相悖。仔细观察图形可发现,其实在10、20mg/L分割点及其两侧附近的其他分割点均近乎或者完全未反应出Lp(a)与T2DM相关,我们认为10、20mg/L分割点处所表现出来的效应是由于组中事件数过少而出现的随机结果。WHS人群研究中未进行连续的阈值估计,在不知道连续趋势的情况下,其所得结论值得商榷。足以看出单纯以特定的点去估计总体趋势的片面和不足,甚至会对研究结论造成误导。我们应该从整体的、连续的变化趋势去判定阈值,准确找出趋势变化的拐点,单纯依据个别分割点的估计,是不准确、不可取的。
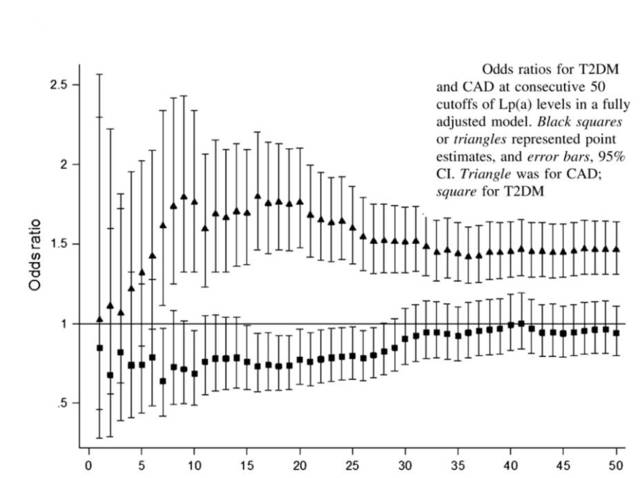
图2
2. 阈值效应的求证演示
接下来,笔者具体讲解阈值效应的求证过程:笔者所用软件为STATA13.0。演示数据来为《Lipoprotein (a) is not significantly associatedwith type 2 diabetes mellitus: cross-sectional study of 1604 cases and 7983controls》研究的CCSSSCC数据集。
正如研究中所描述的,为探究血清Lp(a)浓度在T2DM发病风险中的阈值效应,我们将浓度≤50mg/L的Lp(a)以1mg/L为间距进行50等分,获取50个连续的二分类分割点,即依据每个分割点将总体人群分为两组,Lp(a)浓度小于等于分割点组和Lp(a)浓度大于分割点组。此过程我们可以通过以下
命令:
gen dilpa1=0
replace dilpa1=1 if lpadl>1
结果:

其中我们定义变量dilpa1为以Lp(a)浓度1mg/L为分割点得到的二分类变量。变量lpadl为以mg/L为单位的Lp(a)浓度。可见,Lp(a)浓度大于1mg/L的样本量为9179。
进一步,我们要对所产生的变量dilpa1是否符合我们的要求进行验证:
命令:
tabstat lpadl,stats(n min max ) by(dilpa1)
结果:
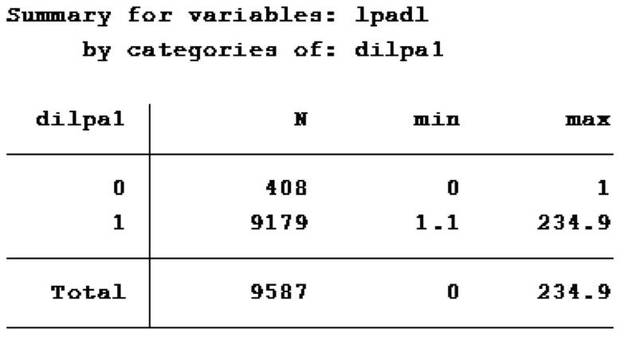
如结果所示,dilpa1=0组的lpadl最大值为1,dilpa1=1组的lpadl最小值为1.1,变量dilpa1确系以1为分割点得到的二分类变量。通过以上方式,我们可以继续连续得到分别以Lp(a)浓度为2、3、4、……、50mg/L为分割点的共50个二分类变量。
接下来,将以上获得的二分类变量依次代入本研究中的全因素校正的Logistic回归模型中。此处以变量dilpa1为例,演示在总体人群中,以dilpa1=0为参照,dilpa1=1组对T2DM发病的OR值及其95%置信区间。
命令:
logistic DM_CAD i.dilpa1age nsex i.ndrinking i.nsmoking group01 nhypertension nischemicbd nbleedingbdnbmi ntg hdlc ldlc year nalb ncr
结果:
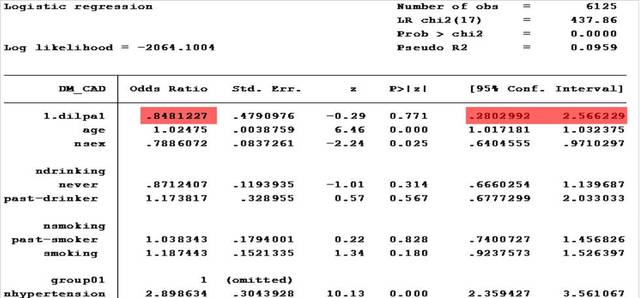
如结果所示,我们可以得到以Lp(a)浓度1mg/L为分割点时,相对小于等于1mg/L组,浓度大于1mg/L组的OR值及其95%置信区间。其中,变量DM_CAD=0代表既无糖尿病也无冠心病组;DM_CAD=1代表单纯患糖尿病组。
通过依次代入连续的不同分割点的二分类变量,我们最终可获得50个对应的OR值及其95%置信区间。笔者将其整理为STATA数据,此处以“list”命令将其列出。
命令:
list
结果:
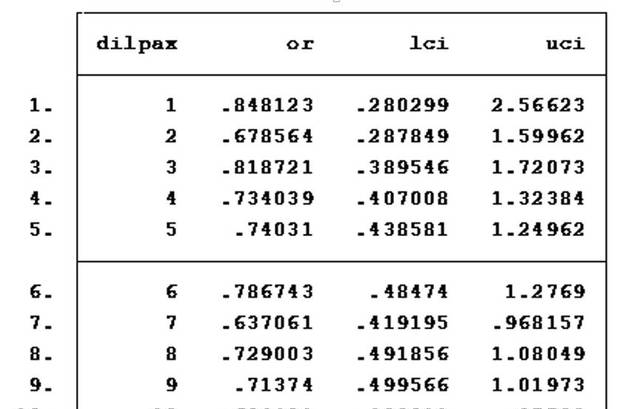
最后,我们将不同Lp(a)浓度分割点在T2DM的发病中的OR值及其95%置信区间,以类似动作电位描记的形式,以图形给出其整体变化趋势。
命令:
graph twoway rcap uci lcidilpax ,lcolor(green) || scatter or dilpax, mcolor(red) msymbol(square) msize(1) yline(1,lcolor(black))
结果:
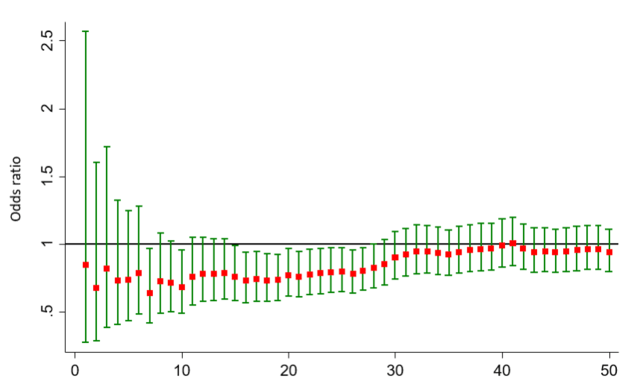
由图形可以直观地看出,随着不同Lp(a)浓度节点的变化,T2DM发病风险并无明显的趋势变化,即无阈值效应存在。
正如研究中所描述的,为探究血清Lp(a)浓度在T2DM发病风险中的阈值效应,我们将浓度≤50mg/L的Lp(a)以1mg/L为间距进行50等分,获取50个连续的二分类分割点,即依据每个分割点将总体人群分为两组,Lp(a)浓度小于等于分割点组和Lp(a)浓度大于分割点组。此过程我们可以通过以下
命令:
gen dilpa1=0
replace dilpa1=1 if lpadl>1
结果:

其中我们定义变量dilpa1为以Lp(a)浓度1mg/L为分割点得到的二分类变量。变量lpadl为以mg/L为单位的Lp(a)浓度。可见,Lp(a)浓度大于1mg/L的样本量为9179。
进一步,我们要对所产生的变量dilpa1是否符合我们的要求进行验证:
命令:
tabstat lpadl,stats(n min max ) by(dilpa1)
结果:
如结果所示,dilpa1=0组的lpadl最大值为1,dilpa1=1组的lpadl最小值为1.1,变量dilpa1确系以1为分割点得到的二分类变量。通过以上方式,我们可以继续连续得到分别以Lp(a)浓度为2、3、4、……、50mg/L为分割点的共50个二分类变量。
接下来,将以上获得的二分类变量依次代入本研究中的全因素校正的Logistic回归模型中。此处以变量dilpa1为例,演示在总体人群中,以dilpa1=0为参照,dilpa1=1组对T2DM发病的OR值及其95%置信区间。
命令:
logistic DM_CAD i.dilpa1age nsex i.ndrinking i.nsmoking group01 nhypertension nischemicbd nbleedingbdnbmi ntg hdlc ldlc year nalb ncr
结果:
如结果所示,我们可以得到以Lp(a)浓度1mg/L为分割点时,相对小于等于1mg/L组,浓度大于1mg/L组的OR值及其95%置信区间。其中,变量DM_CAD=0代表既无糖尿病也无冠心病组;DM_CAD=1代表单纯患糖尿病组。
通过依次代入连续的不同分割点的二分类变量,我们最终可获得50个对应的OR值及其95%置信区间。笔者将其整理为STATA数据,此处以“list”命令将其列出。
命令:
list
结果:
最后,我们将不同Lp(a)浓度分割点在T2DM的发病中的OR值及其95%置信区间,以类似动作电位描记的形式,以图形给出其整体变化趋势。
命令:
graph twoway rcap uci lcidilpax ,lcolor(green) || scatter or dilpax, mcolor(red) msymbol(square) msize(1) yline(1,lcolor(black))
结果:
由图形可以直观地看出,随着不同Lp(a)浓度节点的变化,T2DM发病风险并无明显的趋势变化,即无阈值效应存在。
趋势检验是对医学研究中反应等级或剂量反应关系资料进行假设检验的一种方法,属于卡方检验的范畴。它主要用来检验危险因素在病例-对照研究中两组等级资料构成之间的差别是否具有显著性,以及两组变量间有无相关关系等,从而确定其可能存在等级关系的趋势,为进一步分析剂量反应关系提供依据[3]。趋势检验法是美国Breslow教授于1980年首先提出来的[4],并主要用于流行病学研究中危险因素暴露水平与发病趋势的检验。
同样地,在病例对照研究的Logistic回归分析中,等级变量通常以哑变量的形式进入模型进行拟合估计,默认的情况下,以变量的最低等级水平作为参照,从而得出其他不同等级水平相对于该水平的相对风险比。在判断随着变量等级的变化,发病风险是否也具有趋势性改变(趋势检验)时,我们可直接将等级变量直接以连续变量的形式进行计算,以此得出的相对应的P值,即为趋势检验的结果。
此处笔者仍以上述研究中CCSSSCC数据集为例,对趋势检验的过程稍作演示。继续对连续性变量lpadl10进行分组,探讨随Lp(a)浓度分组的变化,T2DM发病相对风险的变化趋势。
首先,如该研究中所描述,我们需要对既无糖尿病也无冠心病组(DM_CAD=0)的Lp(a)浓度进行十分位处理,可以通过以下命令获得具体的Lp(a)分割点浓度值。
命令:pctilep_lpadl=lpadl10 if DM_CAD==0,nq(10)
结果:
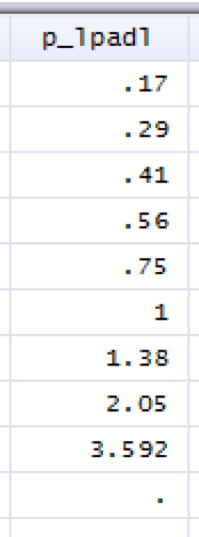
如结果所示,通过对DM_CAD=0组的变量lpadl10进行十分位处理,我们获得返回值变量p_lpadl,即具体的分割点数值。此处变量lpadl0代表以单位mg/dl表示的Lp(a)浓度。
接下来,我们通过以上获得的分割点数值将总体人群分为10组。
命令:
rename p_lpadl class
xtile catelpa10=lpadl10,cutpoints(class)
通过以上命令,我们可以得到一个十分类等级变量catelpa10,即以DM_CAD=0组的Lp(a)浓度水平,将总体人群分为10组。
同样,我们需对获得的该十分类等级变量catelpa10进行验证。
命令:
tabstat lpadl10,stats(n min max) by(catelpa10)
结果:
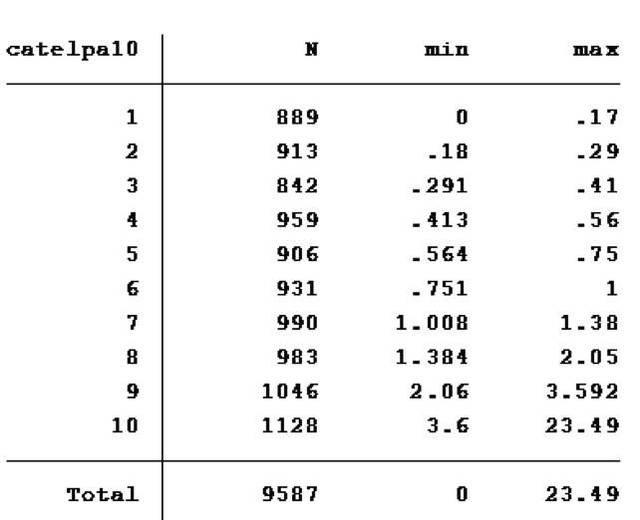
由结果可以看出,变量catelpa10各组中的最大值均与上述分割点相一致,变量符合要求。
将变量catelpa10以哑变量的形式代入全因素校正的Logistic回归模型中,得出在总体人群中以LP(a)浓度最低组为参照,其他Lp(a)浓度分组对T2DM发病的OR值及其95%置信区间。
命令:
logistic DM_CAD i.catelpa10 age nsex i.ndrinking i.nsmoking group01nhypertension nischemicbd nbleedingbd nbmi ntg hdlc ldlc year nalb ncr
结果:

图中红色标注部分即为以LP(a)浓度最低组为参照,其他Lp(a)浓度分组对T2DM发病的OR值及其95%置信区间。笔者对以上结果进行整理,此处以图形的方式给出,具体如下:
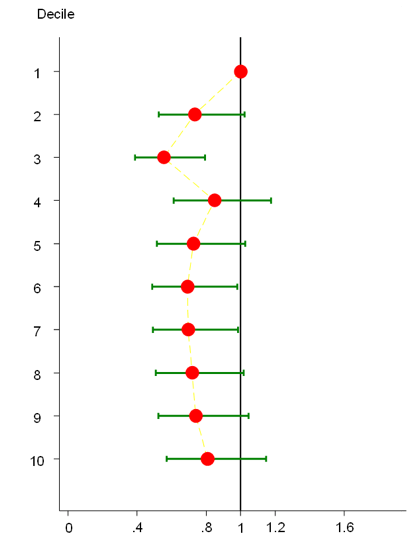
单纯从图形即可直观地看出,经全因素校正后,在总体人群中随着Lp(a)浓度的递增,T2DM的发病风险呈稳定波动,并无明显的变化趋势。
最后将变量catelpa10以连续变量的形式代入全因素校正的Logistic回归模型,在总体人群中,计算出的相应P值即为随着Lp(a)浓度分组的变化,T2DM发病风险的趋势检验结果。
命令:
logistic DM_CAD catelpa10 age nsex i.ndrinking i.nsmoking group01 nhypertension nischemicbd nbleedingbd nbmi ntg hdlc ldlc year nalb ncr
结果:
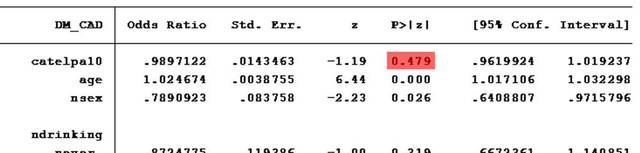
图中红色标注部分即为趋势检验结果的P值。P=0.479,无统计学意义。
首先,如该研究中所描述,我们需要对既无糖尿病也无冠心病组(DM_CAD=0)的Lp(a)浓度进行十分位处理,可以通过以下命令获得具体的Lp(a)分割点浓度值。
命令:pctilep_lpadl=lpadl10 if DM_CAD==0,nq(10)
结果:
如结果所示,通过对DM_CAD=0组的变量lpadl10进行十分位处理,我们获得返回值变量p_lpadl,即具体的分割点数值。此处变量lpadl0代表以单位mg/dl表示的Lp(a)浓度。
接下来,我们通过以上获得的分割点数值将总体人群分为10组。
命令:
rename p_lpadl class
xtile catelpa10=lpadl10,cutpoints(class)
通过以上命令,我们可以得到一个十分类等级变量catelpa10,即以DM_CAD=0组的Lp(a)浓度水平,将总体人群分为10组。
同样,我们需对获得的该十分类等级变量catelpa10进行验证。
命令:
tabstat lpadl10,stats(n min max) by(catelpa10)
结果:
由结果可以看出,变量catelpa10各组中的最大值均与上述分割点相一致,变量符合要求。
将变量catelpa10以哑变量的形式代入全因素校正的Logistic回归模型中,得出在总体人群中以LP(a)浓度最低组为参照,其他Lp(a)浓度分组对T2DM发病的OR值及其95%置信区间。
命令:
logistic DM_CAD i.catelpa10 age nsex i.ndrinking i.nsmoking group01nhypertension nischemicbd nbleedingbd nbmi ntg hdlc ldlc year nalb ncr
结果:
图中红色标注部分即为以LP(a)浓度最低组为参照,其他Lp(a)浓度分组对T2DM发病的OR值及其95%置信区间。笔者对以上结果进行整理,此处以图形的方式给出,具体如下:
单纯从图形即可直观地看出,经全因素校正后,在总体人群中随着Lp(a)浓度的递增,T2DM的发病风险呈稳定波动,并无明显的变化趋势。
最后将变量catelpa10以连续变量的形式代入全因素校正的Logistic回归模型,在总体人群中,计算出的相应P值即为随着Lp(a)浓度分组的变化,T2DM发病风险的趋势检验结果。
命令:
logistic DM_CAD catelpa10 age nsex i.ndrinking i.nsmoking group01 nhypertension nischemicbd nbleedingbd nbmi ntg hdlc ldlc year nalb ncr
结果:
图中红色标注部分即为趋势检验结果的P值。P=0.479,无统计学意义。
2. 趋势检验中的分组问题
以上即为趋势检验的实例演示,然而在实际操作中,笔者最大困惑的是连续性变量的分组位数问题,目前对于该如何对连续性变量进行分组,进而以分类变量的形式进一步进行趋势研究尚无明确的要求。文献中各个研究亦没有给出分组方案的缘由和依据。笔者认为,在保证单组样本量足够的情况下,尽可能多得分组可更直观,更准确得反映趋势变化,并得出更真实的趋势检验结果。
我们知道,对于趋势检验,要求等级变量有三组或三组以上才可以执行。在分组较少的情况下,单独一组的风险水平对整体的趋势判断占有很大的权重,尤其是最后一组。由于受组中事件数即发病率的影响,某一组也有可能会产生随机结果,如若该组在趋势检验中起到决定性作用,所得出的趋势检验结果也就是随机的。如图3中,最后一组的发病风险OR值及其置信区间(红色或者绿色)很大程度上决定了对整体趋势的定义。因此,减小单组结果在趋势检验中的影响权重至关重要。而我们所能想到的最简单的方法,就是增加分组的位数。然而,增加分组必定会导致单组中样本量的减少,其组内事件数亦会减少,这又会增加单组出现随机结果的概率。因而又似乎是矛盾的。所以笔者得出结论,即在保证单组样本量的情况下尽可能得增加分组位数。这就又涉及到另一个关键的问题,即样本是多少时才能“保证”样本量呢?笔者翻阅了大量的文献也没有找出合适的答案,可能这就是医学统计学壁垒中缺少的一砖。有这个漏洞的存在,没有依据,分组也就会显得缺乏自信。依据经验主义,笔者认为,对于单组样本量的合适与否,我们可以通过由其计算出的点估计值的95%置信区间的形态去判定。即确保各单组95%置信区间的形态合理和正常。
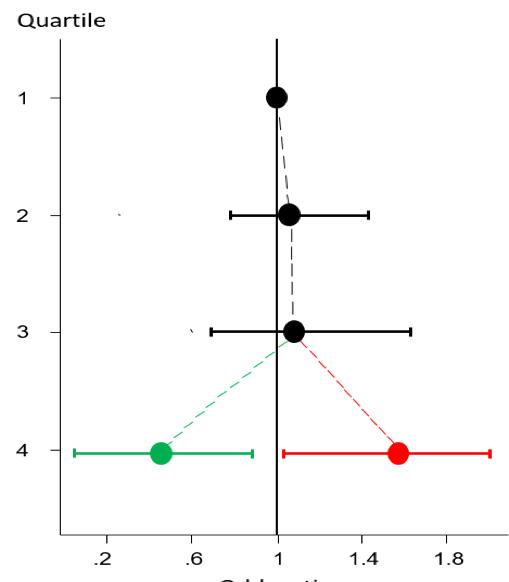
图3
例如,在中国汉族人群中血清Lp(a)和T2DM的相关性的研究中,笔者对血清Lp(a)浓度做了十分位处理(图4,其中对T2DM的点估计以黑色正方形表示,对CAD的点估计以黑色三角形表示)[2]。相对于Ding Lin等对Lp(a)进行四分位的研究[5],多位分组使我们可以获得更多的点估计,削弱单组结果对整体趋势的影响。通过图4我们可以看出,在整体人群(Total)中,尽管经十分位处理,单组中无论是对T2DM还是对CAD的点估计所得的95%置信区间均未出现形态上的异变,也就是说保障了单组中样本量的充足。但是在对性别的分层后,由于单组样本量的减少,各组对应的95%置信区间增大,由于男性人群无论在T2DM还是在CAD中,其事件数均比女性要多,其对应点估计的95%置信区间总体形态仍可接受,但在女性人群中就显得差强人意了。由此,分组时保证单组中样本量充足的重要性可见一斑亦。由图形即可直观得看出,随着血清Lp(a)浓度等级的增加,T2DM的发病风险基本上毫无变化,即无趋势可言,通过统计学计算也得出相同的结论。而CAD的发病风险总体上呈上升趋势。而Ding Lin等的研究中[5],对于血清Lp(a)浓度对T2DM的患病风险,在总体人群的全因素校正模型中,相对于第1四分位(1.00),第2,3,4四分位的相对风险比OR值及95%置信区间分别为:0.86(0.73-1.01),0.88(0.75-1.04),0.76(0.64-0.90)。我们可以看到,实际上,以上数值与我们十分位中的前四分位十分相似,由于不同分组中事件数的不同,模型估计所得的相对风险比在不同分组中本身就会存在波动,如果单纯就以上数值的趋势去估计整体的变化趋势,的确缺少说服力,有可能进行多位分组后这种趋势就会消失,就会得出与我们相一致的结果。
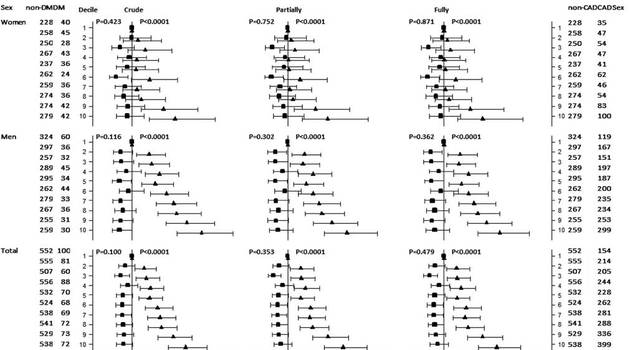
图4
由此,笔者重申自己的观点,对于趋势检验,在保证单组样本量的前提下,我们需要尽可能得增加分组位数,这样才可使趋势检验的结果更加显著和准确。至于对样本量的具体要求,还需要进一步的统计学求证探讨。同时,这也对我们研究的总体样本量提出了相应的要求,大数据时代的到来也需要我们以更新更好的姿态去迎接。
以上就是笔者在临床病例-对照研究中的些许体会和见解,在此与大家分享。面对数据分析,相信每个人都曾有过困惑和无奈,通过不断地发现问题和解决问题,我们相濡以沫共同成长,希望我所经历的对你有所帮助。
参考文献:
[1]Mora S,Kamstrup PR, Rifai N, et al. Lipoprotein(a) and risk of type 2 diabetes. ClinChem, 2010, 56(8): 1252-1260.10.1373/clinchem.2010.146779
[2]Liu C,Xu MX, He YM, et al. Lipoprotein (a) is not significantly associated with type2 diabetes mellitus: cross-sectional study of 1604 cases and 7983 controls.Acta Diabetol, 2017.10.1007/s00592-017-0965-2
[3]杨树勤. 卫生统计学第3版. 人民卫生出版社, 1993,76:
[4]BreslowNE, Day NE. Statistical methods in cancer research. Volume I - The analysis ofcase-control studies. IARC Sci Publ, 1980, (32): 5-338
[5]Ding L,Song A, Dai M, et al. Serum lipoprotein (a) concentrations are inverselyassociated with T2D, prediabetes, and insulin resistance in a middle-aged andelderly Chinese population. J Lipid Res, 2015, 56(4):920-926.10.1194/jlr.P049015
推荐图书
超人气专家加盟作者团队,覆盖“统计学趣谈”“统计软件实战”“大数据与科研”“数据纵横” 四大专题,畅销书《傻瓜统计学》姊妹篇《聪明统计学》正式面世。

如果您长期关注某一个医学领域,对医学相关事件、临床研究等有独到的观点,并愿意在较长的一段时间内,与AME共同成长,供给我们“营养”,就给我们发email吧。
微信号文章投稿联系方式:
E-mail:weixin@amegroups.com
来稿请注明“微信号文章投稿”,并请提供作者单位、联系电话等信息。
1.《CASE-CONTROL研究中阈值效应及趋势检验》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《CASE-CONTROL研究中阈值效应及趋势检验》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/8922.html