在电子竞技大数据时代,数据对于比赛的观赏性和专业性起着至关重要的作用。同样,也对电子竞技数据的丰富性和实时性提出了越来越高的要求。

电子竞技数据的丰富性从受众角度可以分为赛事、球队、选手数据;从游戏角度看,维度可以由英雄、战斗、道具、技能组成;电竞数据的实时表现包括比赛前两队的历史交战记录、比赛中的实时比分、胜率预测、赛后比赛分析、英雄对比等。
因此,多维数据支持、从TB到PB的海量数据存储和实时分析都对底层系统的架构设计提出了更高的要求,也带来了更严峻的挑战。
本文将介绍电子竞技数据平台FunData架构演进中的设计思路和相关技术,包括大数据流处理方案、结构化存储到非结构化存储方案和数据API服务设计。在其1.0测试版中,FunData为MOBA顶级游戏DOTA2提供了相关的数据接口。
1.0架构
在项目开发初期,根据MVP理论,我们迅速推出了FunData系统的第一版。系统主要有两个模块:主模块和从模块。

图1 1.0ETL架构图
主模块的功能如下:
定时调用Steam接口获取比赛ID与基础信息;通过In-Memory的消息队列分发比赛分析任务到Slave节点;记录比赛分析进度,并探测各Slave节点状态。从模块具有以下功能:
监听队列消息并获取任务,任务主要为录像分析,录像分析参考GitHub项目Clarity(https://github.com/skadistats/clarity)与Manta(https://github.com/dotabuff/manta);分析数据入库。系统初始运行比较稳定,可以快速拉取各个维度的数据。然而,随着数据量的增加,数据和系统的可维护性日益突出:
新增数据字段需要重新构建DB索引,数据表行数过亿构建时间太长且造成长时间锁表;系统耦合度高,不易于维护,Master节点的更新重启后,Slave无重连机制需要全部重启;同时In-Memory消息队列有丢消息的风险;系统可扩展性低,Slave节点扩容时需要频繁的制作虚拟机镜像,配置无统一管理,维护成本高;DB为主从模式且存储空间有限,导致数据API层需要定制逻辑来分库读取数据做聚合分析;节点粒度大,Slave可能承载的多个分析任务,故障时影响面大。在开始2.0架构设计和转换之前,我们尝试使用冷存储方法通过迁移数据来降低系统压力。由于数据表中的数据量很大,并发迁移多个数据任务需要花费大量时间,数据清理的过程也会触发索引重建,因此在线解决方案并不能从根本上解决问题。

图2冷藏方案
2.0架构
借鉴1.0系统的经验,在2.0架构设计中,我们从可维护性、可扩展性、稳定性三个方面考虑新的数据系统架构应该具备的基本特征:
数据处理任务粒度细化,且支持高并发处理(全球一天DOTA2比赛的场次在120万场,录像分析相对耗时,串行处理会导致任务堆积严重);数据分布式存储;系统解耦,各节点可优雅重启与更新。
图3 2.0ETL总体架构图
2.0系统选择Google云平台搭建整个数据ETL系统,使用PubSub作为消息总线,任务细分为多个Topic进行监控,由不同的Worker进行处理。这一方面降低了不同任务的耦合度,防止了一个任务的异常处理导致其他任务的中断;另一方面,任务基于消息总线传输,因此不同的数据任务具有更好的可扩展性,在性能不足时可以快速向外扩展。
任务粒度细化
从任务粒度的角度,数据处理分为基础数据处理和高阶数据处理两部分。基本数据,也就是比赛的详细信息和视频分析数据由主管采集Steam数据触发,由工作人员清理,存储在Google Bigtable中;;高阶数据,即多维统计数据,在视频分析后触发,通过GCP的数据流和自建分析节点进行聚合,最后存储在MongoDB和Google Bigtable中。
根据Leauge-ETL的详细架构,将原Slave节点分为四个子模块,分别是联赛数据分析模块、联赛视频分析模块、分析/挖掘数据DB代理模块和联赛分析监控模块。
联赛数据分析模块负责录像文件的拉取(Salt、Meta文件与Replay文件的获取)与比赛基本数据分析;联赛录像分析模块负责比赛录像解析并将分析后数据推送至PubSub;分析/挖掘数据DB代理负责接收录像分析数据并批量写入Bigtable;联赛分析监控模块负责监控各任务进度情况并实时告警。同时,所有模块都选择Golang重构,利用其“自然”的并发能力,提高整个系统的数据挖掘和数据处理性能。

图4联盟-ETL架构
分布式存储
如上所述,在1.0架构中,我们使用MySQL来存储大量的游戏数据和视频分析数据。在大数据高并发的场景下,MySQL的整体应用开发变得越来越复杂。比如不能支持频繁的模式变更,架构设计需要合理考虑子数据库和子表的时序,以及数据达到一定级别时子数据库面临的可扩展性问题。
参考Google的Bigtable,Bigtable和HBase作为一个分布式、可扩展的大数据存储系统,能够很好的支持随机、实时的数据读写访问,更适合FunData数据系统的数据顺序和复杂度。

图5 Hadoop生态
在数据模型上,Bigtable和HBase通过行键、列名和时间戳来定位单元格。
比如在FunData数据系统中,比赛数据的RowKey是以hash_key+match_id的形式构造的,因为DOTA2的match_id是按顺序递增的,在每个match_id之前加入一致哈希算法计算的hash_key,可以防止分布式存储中的单热点问题,提高整个存储系统的数据负载均衡能力,实现更好的分片
如图7所示,我们预设了多个键值作为哈希环上RowKey的前缀。当我们得到match_id时,我们通过一致哈希算法得到哈希环节点对应的match_id的键值,最后通过将键值与match_id拼接来构建RowKey。

图7一致性散列构造行关键字
时间戳的使用方便了我们在聚合数据时重复写入相同RowKey和Column的数据。HBase/Bigtable有自己的GC策略,清理过期时间戳数据,读取时取最新时间节点的数据。
在这里,你可能有一个问题。Bigtable和HBase只能用作一级索引。向RowKey添加hash_key后,不能按row_range批量读取,也不能按时间批量查询。在使用Bigtable和HBase的过程中,二级索引需要业务定制。在实际场景中,我们的工作人员将建立一个时间戳索引——RowKey,并在处理每个比赛数据时将其存储在MySQL中。当需要基于时间的批量查询时,首先查询索引表拉取RowKeys的列表,然后得到相应的数据列表。
在数据读写方面,Bigtable/HBase和MySQL也有很大不同。通常,MySQL使用查询缓存,当模式更新时,这将失败。此外,查询缓存依赖于全局锁保护。当缓存大量数据时,如果查询缓存失败,表将被锁定。
如图8所示,以HBase为例,客户端在读取数据时,首先通过zookeeper定位RowKey所在的RegionServer。在读取请求到达区域服务器之后,区域服务器组织扫描操作,并最终合并查询结果以返回数据。因为一个查询操作可能包括多个区域服务器和多个区域,并且数据搜索是同时执行的,并且HBase的LRUBlockCache不会锁定所有数据查询。
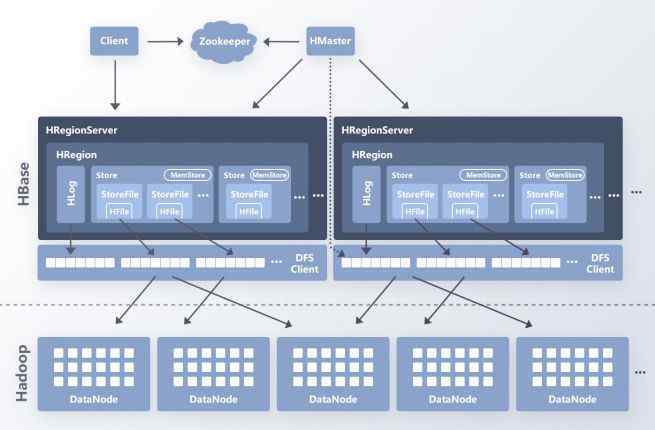
图8 HBase架构
基于新的存储架构,我们的数据维度已经从单一游戏扩展到玩家、英雄和联盟,如图9所示。

图9数据维度
系统解耦
如上所述,在1.0架构中,内存中的消息队列用于数据传输。因为内存中的队列数据不是持久存储的,并且与主模块强耦合,主节点的更新或异常死机将导致数据丢失和长时间的恢复。因此,在2.0架构中,采用第三方的消息队列作为消息总线,保证了系统“上下游”节点的解耦,可以多次迭代更新,使历史消息具有可追溯性,并基于云平台使消息积累可见。

图10数据监控
数据应用编程接口层
1.0为了快速上线,系统的数据API层并没有在架构上做太多的设计和优化,而是使用域名来实现负载均衡,使用开源DreamFactory搭建的ORM层以其RESTful接口访问数据。
这种体系结构的开发和使用存在许多问题:
API层部署在国内阿里云上,数据访问需要跨洋;ORM层提供的API获取表的全字段数据,数据粒度大;无缓存,应对大流量场景(如17年震中杯与ESL)经常出现服务不可用;多DB的数据聚合放在了API层,性能不足;服务更新维护成本高,每次更新需要从域名中先剔除机器。为了解决上述问题,我们从两个方面重构了1.0数据API层,如图11所示。

图11数据应用编程接口的新架构
链接的稳定性
在全局链路上,我们使用CDN动态加速来保证接入稳定性。同时利用云厂商CDN进行备份容灾,实现二级切换。
在调度能力和恢复能力方面,我们构建了自己的灰色系统,将不同维度的数据请求调度到不同的数据API,降低了不同维度的数据请求对系统的影响;借助灰度系统,API服务更新的风险和异常时的影响面也得到有效控制。根据云平台可用区域的特点,灰度系统还可以方便地实现跨可用区域的后端API服务,从而实现物理架构上的容灾。
此外,为了保证内部跨洋接入链路的稳定性,我们在阿里巴巴云北美机房设置了数据代理层,并使用海外专线提高接入速度。
数据的高可用性
在访问分布式存储系统后,外部数据API层也按照扩展的数据维度进行拆分,多个数据API向外界提供服务。比如比赛数据、联赛赛程等数据访问量较大,要与英雄、个人、道具数据分开,防止比赛/赛事的异常界面影响到所有无法访问的数据。
对于热数据,内部cache层会定期写入Cache,数据的更新也会触发Cache的重写,从而保证比赛期间数据的可用性。
-结论
本文介绍了FunData数据平台体系结构的演进过程,分析了旧系统在体系结构上的不足,以及在新系统中采用什么技术和体系结构手段来解决这些问题。
自4月10日FunData上线以来,已有300多家技术开发商申请了API-KEY。目前也在专注于新数据点的快速迭代开发,比如联盟统计。游戏实时数据等。
声明:本文为作者提交,版权归作者本人所有,首次发表于CSDN。
要求文件!
1.《电竞游戏平台 一文了解电竞游戏平台的大数据玩法儿!》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《电竞游戏平台 一文了解电竞游戏平台的大数据玩法儿!》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/guoji/1693064.html