人们常说,有人的地方就有江湖。而我们要说,有江湖的地方就有欺诈。反欺诈由来已久,从最原始的人工检测,到后来的黑白名单、规则引擎、有监督学习算法,再到现如今的无监督学习,演化至今,欺诈与反欺诈手法可谓变化多端,此消彼长。常言道,道高一尺,魔高一丈。这句话用在欺诈与反欺诈行业再合适不过了。在巨额利益的诱惑下,欺诈者不断扩充队伍,升级技术,变化攻击方式,给个人和企业带来了巨大威胁。
在与欺诈分子斗争的诸多年间,反欺诈不断形成了自己的方法论。具体都有哪些方法?都适应哪些场景?哪种方法更有效?且听黄姐姐娓娓道来。
方法一、黑白名单
黑白名单是最原始的反欺诈手段,顾名思义,黑名单就是坏人,白名单则指好人。举个?:人行征信记录着每个信用卡持卡人的还款记录,如果你有信用卡逾期且拒绝还款,甚至直接从人间蒸发,那么恭喜你,你可能就上了人行的黑名单。一段时间后,你重新在江湖上复出,想着:申请个新信用卡吧!银行在接到你的申请表后,在黑名单上一查,发现了你,于是乎,驳回!这就是黑名单的使用方式。黑名单的应用非常广,且一份黑名单通常能卖到很高的价格,例如:你经常在淘宝上购买退货险,又屡屡退货,那么,你就有可能上了骗保的黑名单,想再次购买退货险就很难了。
方法二、规则引擎
黑名单的优缺点十分明显,优点就是简单方便,各行各业各产品的反欺诈都可以用黑名单,缺点就是无法发现新骗子。黑名单的升级版本是规则引擎,还是拿退货险举例。之前,保险公司拿着一个清单来比对哪些人可以购买退货险,经过一段时间的积累,保险公司发现,退货比例超过80%的用户极可能再次退货,疑似骗保;或者连续退货超过5次的用户的骗保嫌疑也非常大。于是乎,保险公司设定了一个阈值,规则如下:
1. 连续退货5次的用户,拒绝其购买退货险;
2. 退货比例超过80%,拒绝其再次购买退货险。
很明显,只要符合这两种规则的任何一个,就会被保险公司拒之门外。这相比于黑名单,可以检测到新的欺诈者,算是进了一大步。但是,规则引擎却无法检测到新的欺诈模式。假设,通过不断的测试规则,我发现了这个阈值。于是乎,我准确控制自己的退货率在79%以下, 便可以继续自己的骗保生涯,躺着赚钱了。一段时间后,保险公司再次发现了我的伎俩,于是把阈值下调到50%。
规则引擎通常可配合黑名单一起使用,通过规则引擎抓到的坏人被列到黑名单中。
规则引擎的规则是如何生成的?答案是:经验!这听起来有点不靠谱,万一经验错了怎么办?事实上,的确会发生这样的情况。例如,通过我们之前的经验判断,认为退货比例超过80%的就是坏用户。那么,假设我是一个网购新人,第一次买衣服,发现号码小了,于是退货。那么,我购买的第一单就退货哦,退货比例100%,能说我就是骗保的吗?下次就不让我买退货险了?这显然不符合逻辑!
正因为经验的不确定性,规则通常需要投入大量的精力维护,不断更新、修改、删除、添加等等,否则就会造成大量的FP和FN。
方法三、有监督学习
有监督学习是应用最为广泛的反欺诈方法。有监督学习通常需要大量的有标签数据来训练模型,以此来预测还未被标注的数据。拿垃圾邮件举例,假设你把5000封已经由人工确认过的垃圾邮件输入到了模型,告诉模型:hey,这些是垃圾邮件,帮我分析下!于是模型开始工作,通过对标题的识别,对邮件内容句子的分割,关键词的识别等各种分析方法,找到了某种你没办法说得清楚的内在关系。为了方便说明,我尝试把这种关系抽象出来:
标题里有“福利”二字的,有90%的可能性是垃圾邮件;
内容里有“汇款账号:xxxxxx”的,有10%的可能性是垃圾邮件;
一次性发送超过200封的,有60%的可能性是垃圾邮件;
回复率低于10%的账户,有70%的可能性是垃圾邮件;
这里,百分之多少称为权重。
训练好后,你给模型一封新邮件,模型通过检测以上各个子项,并对每一个子项乘以权重后相加,就得出一个分数,例如,这封有80%的可能性是垃圾邮件。
以上就是一个有监督学习的抽象过程,其中一个重要的步骤就是通过不断的迭代计算每一个子项应该被赋予的权重值。权重值计算好后,就可以说这个模型训练好了。
有监督学习的好处也十分明显,它可以帮我们分析隐层关系。我们可以不必知道到底有监督是如何做分析的,每一个子项被赋予了多少权重,我们只需要知道符合某种规则的就是坏人。此外,有监督还有助于处理多维数据。由于规则是人凭经验产生了,而如果老板丢给你一组数据,每一条数据都有多达500个字段,让你凭肉眼看出其中的关系,你恐怕要抓狂了。此时,有监督就可以解决你的问题了。
但有监督也有一个明显的弊端,每一个模型都需要大量的训练数据,训练一个模型也需要较长的时间。现在的骗子是何其聪明啊,到处打游击战。在你发现有入侵者后,你立马开始训练模型,然而,再你还没有训练好,骗子们可能就已经离开,开始找下一个目标了。如此,有监督便无法应对复杂多变,诡计多端的欺诈者了。
方法四、无监督学习
近年来,无监督为反欺诈打开了新大门,主要方式有聚类和图形分析。无监督无需任何训练数据和标签,通过发现用户的共性行为,以及用户和用户的关系来检测欺诈。下图描述了聚类的方式:
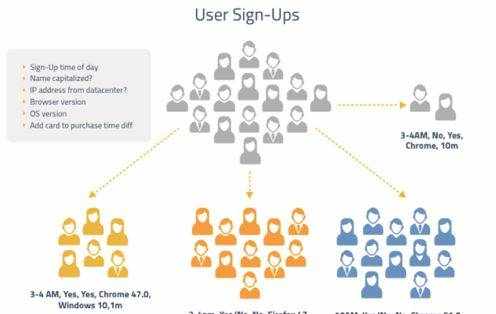
有这样一群用户注册事件,我们通过聚类发现其几个小群符合某些共性:例如:注册时间集中,都使用了某操作系统,某一个浏览器版本等。这个用户任何一个单独拿出来分析,看上去都是再好不过的用户了,而如果其符合某种超乎寻常的一致性就十分可疑了。例如,你发现一群人在凌晨2点-3点,采用chrome浏览器注册了某产品,其ip的前20位相同,GPS定位小于1公里,且注册后都去修改了昵称和性别。如果一个人这么做,你觉得正常啊,某个夜猫子随便逛网站而已。而如果一群人这么做,你心里恐怕就要犯嘀咕了吧!
下图描述了图形分析的方式:
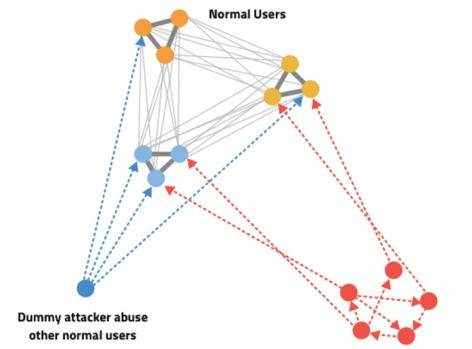
为了解释分析逻辑,还是拿垃圾邮件举例。一个正常的邮箱,往来信件比例不会相差特别离谱,中国有句古话“来而不往非礼也”!你收到人家的一封邮件,回复一下“well received”是起码的礼仪。而我相信你基本上不会回复任何一个垃圾邮件或广告邮件,而是直接删除吧!通过回复率来判断垃圾邮件也是一个常用的方式。
图中,左下角是一个低端的攻击者,只是单纯地发送大量垃圾邮件,而邮件的回复率几乎为0,对于这种邮箱,我们很容易判断其为垃圾邮箱。右下角的群体就聪明多了,他们通过互相间的往来邮件来增加回复率,告诉反欺诈者:看,我有收到邮件哦!人家有回复我哦!你可不能抓我!这些邮箱通常互加好友,互通邮件,以此来伪装成正常用户。
通过无监督学习,我们可以发现这种类型的伪装者,将其一网打尽。
无监督算法应用于反欺诈检测,通常还有一个优势,那就是提前预警。现在聪明的骗子都知道要潜伏一段时间再发起攻击,以免太容易被发现。而由于其在潜伏期的行为依然符合某种规律,具有某些一致性,所以同样还是会无监督算法捕捉到。在攻击发生前就指认骗子,这一点,其他三种方法恐怕是望尘莫及!这也是无监督之所以在反欺诈检测大放光彩的重要原因之一。
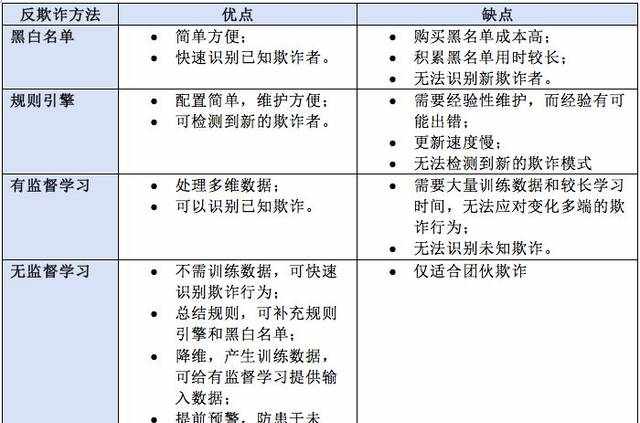
可见,反欺诈手法无分优劣,选择适合自己的就是最好的!
如果你的欺诈问题非常多,不妨将所有方法综合起来用,建立一个全栈式检测平台。
1.《反欺诈之四大杀器》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《反欺诈之四大杀器》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/junshi/23444.html