
今天跟大家分享一下基于Python的上海天气数据获取(含空气质量数据)。
本次分享的数据来源是“2345天气预报网”(http://tianqi.2345.com/wea_history/58362.htm),尤其在2016年以后数据中新增了有关空气质量的指标,具体可见下图:
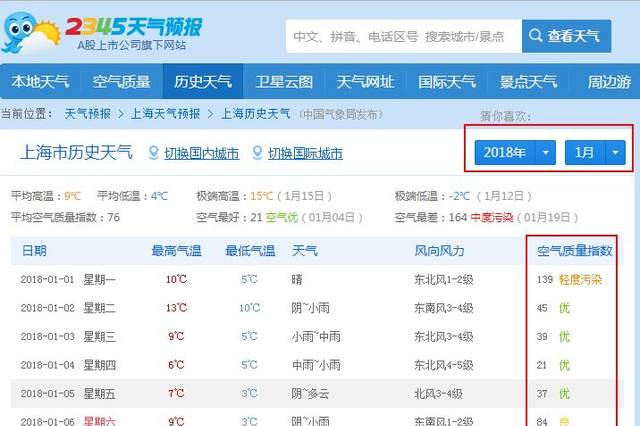
首先看看数据是否直接嵌在html网页中,最有效的方法是在原网页中选择不同的年份和月份,看看链接是否发生变动。经测试,网页链接无变化,那就说明天气数据一定异步存储在别的文件中,接下来就要找到这个存储数据的文件了。
按照爬虫的一般套路,首先在原网页中按入F12快捷键,选择Network,然后再从原网页中选择不同的年份或月份,你就会从XHR或JS中找到那个文件。很显然,这里的天气数据是存储在JS文件中的:
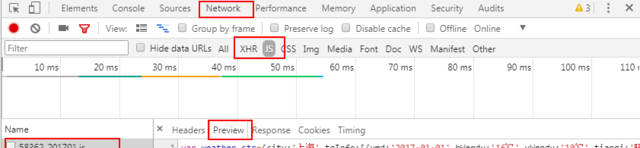
接下来就是确定这个文件的链接地址,如下图所示,这个链接还是非常简洁的,你可以选择不同的年份或月份,发现这些链接的规律,然后一次性生成这些具有规律的链接。

# 生成所有目标链接,用于后期的爬虫
urls = []
foryear inrange( 2011, 2018):
formonth inrange( 1, 13):
ifyear <= 2016: urls.append( 'http://tianqi.2345.com/t/wea_history/js/58362_%s%s.js'%(year,month))
else:
ifmonth< 10: urls.append( 'http://tianqi.2345.com/t/wea_history/js/%s0%s/58362_%s0%s.js'%(year,month,year,month))
else: urls.append( 'http://tianqi.2345.com/t/wea_history/js/%s%s/58362_%s%s.js'%(year,month,year,month))urls
不妨以urls中的第一个链接为例,看看能够从中抓到什么内容:
# 导入模块
importrequests
# 对目标链接发送请求
url = urls[ 0]response = requests.get(url).textresponse
很棒,所有跟天气相关的数据,都可以获取到,接下来通过正则表达式将每个关心的字段都存储到列表中:
# 导入模块
importre
# 正则匹配
ymd = re.findall( "ymd:'(.*?)',",response)high = re.findall( "bWendu:'(.*?)℃',",response)low = re.findall( "yWendu:'(.*?)℃',",response)tianqi = re.findall( "tianqi:'(.*?)',",response)fengxiang = re.findall( "fengxiang:'(.*?)',",response)fengli = re.findall( ",fengli:'(.*?)'",response)aqi = re.findall( "aqi:'(.*?)',",response)aqiInfo = re.findall( "aqiInfo:'(.*?)',",response)aqiLevel = re.findall( ",aqiLevel:'(.*?)'",response)
最终,可以使用for循环完成所有链接数据的获取,得到如下形式的一张表格:
1.《上海历史天气和空气质量数据获取》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《上海历史天气和空气质量数据获取》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/keji/18881.html