HAPPY
2018
NEW YEAR
试验设计 (Design Of Experiment, 简称 DOE) ,是研究和处理多因子与响应变量关系的一种方法。它通过合理地挑选试验条件,安排试验,并通过对试验数据的分析,从而建立响应与因子之间的函数关系,或者找出总体最优的改进方案。最基本的试验设计方法是全因子试验法,需要的试验次数最多,其它试验设计方法均以“减少试验次数”为目的,例如部分因子试验、正交试验、均匀试验等。
从上个世纪 20 年代育种科学家费雪 (RonaldFisher) 在农业试验中首次提出 DOE 的概念, DOE 已经历了 90 多年的发展历程,在学术界和企业界均获得了崇高的声誉。然而,由于专业统计分析的复杂性和各行各业的差异性, DOE 在很多人眼中逐渐演变为可望而不可及的空中楼阁。其实, DOE 绝不是少数统计学家的专属工具,它很容易成为各类工程技术人员的好朋友、好帮手。
一、为何要进行试验设计
在进行6西格玛项目的改进阶段时,我们经常需要面对的一个问题是:在相当多的可能影响输出Y的自变量X中,确定哪些自变量确实显著地影响着输出,如何改变或设置这些自变量的取值会使输出达到最佳值?
我们传统使用的方法:将影响输出的众多输入变量在同一次试验中只变化一个变量,其他变量固定。
传统方法的缺点:试验周期长,浪费时间,试验成本高;试验方法粗糙,不能有效评估输入间的相互影响。
可以有效克服上述缺点的试验方法是:DOE
DOE取得的是突破性改善
试验策划时,研究如何以最有效的方式安排试验,能有效识别多个输入因素对输出的影响;
试验进行时,通过对选定的输入因素进行精确、系统的人为调整来观察输出的变化情况;
试验后通过对试验结果的分析以获取最多的信息,得出“哪些自变量X显著地影响着输出Y,这些X取什么值时会使Y达到最佳值”的结论。
我们在分析阶段使用回归分析方法对历史数据进行分析,获得了相应的回归方程,得到Y与各个X间的关系式。但这种关系的获得是“被动”的,因为我们使用的是已有的现成的数据,几乎无法控制适用范围,无法控制方程的精确度,只能是处于“有什么算什么”的状况。
我们采用DOE的方法,自变量常取一些过去未曾取过的数值,并且进行精确的控制,对要研究的问题进行更广泛的探索,目的是要取得突破性改善。
二、DOE的基本术语
2.1 因子:
影响输出变量Y的输入变量X称为DOE中的因子。
可控因子:在实验过程中可以精确控制的因子,可做为DOE的因子。
非可控因子:在实验过程中不可以精确控制的因子,亦称噪声因子,不能作为DOE的因子。只能通过方法将其稳定在一定的水平上,并通过对整体试验结果的分析,确定噪声因子对试验结果的影响程度。
可控因子对Y的影响愈大,则潜在的改善机会愈大。
在DOE的策划阶段,首先要识别可控因子和噪声因子。
2.2 水平:
因子的不同取值,称为因子的“水平”。
2.3 处理:
各因子按照设定的水平的一个组合,按照此组合能够进行一次或多次试验并获得输出变量的观察值。
2.4 模型与误差:
按照可控因子x1、X2、。。。XK建立的数学模型。
Y=F( x1、X2、。。。XK )+ε
误差ε包含:由非可控因子所造成的试验误差。
失拟误差(lack of fit):所采用的模型函数F与真实函数间的差异。
2.5 望大、望小、望目:
望大:希望输出Y越大越好。
望小:希望输出Y越小越好。
望目:希望输出Y与目标值越接近越好。
2.6 主效应:
一个因子在不同水平下的变化导致输出变量的平均变化。
因子的主效应=因子为高水平时输出的平均值-因子为低水平时输出的平均值。
交互效应:如果一个因子的效应依赖于其它因子所处的水平时,则称两个因子间有交互效应。
因子AB的交互效应=(B为高水平时A的效应- B为低水平时A的效应)/2。
三、试验设计的基本原则
完全重复进行试验的目的就是比较不同处理之间是否有显著差异,而显著性检验是拿不同总体间形成的差别与随机误差相比较,只有当各总体间的差别比随机误差显著地大时,才说“总体间的差别是显著的”,没有随机误差的估计就无法进行任何统计推断。
因此,在试验的安排中,在处理相同的条件下一定要进行完全重复试验,以获得试验误差的估计。
注意:
一定要进行不同单元的完全重复,不能仅进行同单元的重复取样
例如:在研究热处理问题时,不能仅从同一次试验中抽取不同的样品进行性能测试,而应该对同一组试验条件进行重新重复试验;否则将会造成试验误差的低估。
随机化
以完全随机的方式安排各次试验的顺序和所有试验单元。目的是防止那些试验者未知的但可能会对响应变量产生某种影响的变量干扰对实验结果的分析。
随机化并没有减少试验误差本身,但随机化可以使不可控因素对实验结果的影响随机地分布于各次试验中。
区组化
实际工作中,各试验单元间难免会有某些差异,如果可以按照某种方式进行分组,每组内可以保证差异较小,而允许区组间差异较大,可以很大程度上消除由于较大试验误差所带来的分析上的不利。
能分区组者则分区组,不能分区组者则随机化。
四、DOE的一般步骤
通过历史数据或现场数据确定目前的过程能力;
确立试验目标并确定衡量试验输出结果的变量;
重新评估优化后的过程能力;
确定可控因素和噪声因素;
确定每个试验因素的水平数和各水平的实际取值;并确定试验计划表;
验证测量系统;
按照试验计划表进行试验;并测量试验单元的输出;
分析数据,进行方差分析和回归分析,找出主要因素并确定输入和输出 的关系式;
确认取得最好的输出结果的因素水平的组合;
在此优化组合的因素水平上进行重复试验以确认效果;
通过标准作业程序固定优化的条件,并进行控制;
五、DOE所用到到的最主要的工具
测量系统分析(MSA)
假设检验:看检验结果的P值,P值小于设定的显著性水平(例如0.05)时判定要检验的两总体间有显著差异; P值大于设定的显著性水平(例如0.05)时判定要检验的两总体间没有有显著差异;
方差分析:看检验结果的P值,P值小于设定的显著性水平(例如0.05)时判定要检验的多总体间有显著差异; P值大于设定的显著性水平(例如0.05)时判定要检验的多总体间没有有显著差异;
回归分析:看检验结果的P值,P值小于设定的显著性水平(例如0.05)时判定要检验的回归项或回归方程显著(有效); P值大于设定的显著性水平(例如0.05)时判定要检验的回归项或回归方程不显著(无效);
六、DOE的类型
因子筛选设计:试验目的是为了确定在相当多的自变量中,哪些自变量并不显著地影响输出并予以删除,而保留那些显著影响输出的自变量。
回归设计:试验目的是为了确定输入与输出之间的关系式,找出回归方程。
七、DOE试验7大步骤
第一步 确定目标
我们通过控制图、故障分析、因果分析、失效分析、能力分析等工具的运用,或者是直接实际工作的反映,会得出一些关键的问题点,它反映了某个指标或参数不能满足我们的需求,但是针对这样的问题,我们可能运用一些简单的方法根本就无法解决,这时候我们可能就会想到试验设计。对于运用试验设计解决的问题,我们首先要定义好试验的目的,也就是解决一个什么样的问题,问题给我们带来了什么样的危害,是否有足够的理由支持试验设计方法的运作,我们知道试验设计必须花费较多的资源才能进行,而且对于生产型企业,试验设计的进行会打乱原有的生产稳定次序,所以确定试验目的和试验必要性是首要的任务。随着试验目标的确定,我们还必须定义试验的指标和接受的规格,这样我们的试验才有方向和检验试验成功的度量指标。这里的指标和规格是试验目的的延伸和具体化,也就是对问题解决的着眼点,指标的达成就能够意味着问题的解决。
第二步 剖析流程
关注流程,使我们应该具备的习惯,就像我们的很多企业做水平对比一样,经常会有一个误区,就是只讲关注点放在利益点上,而忽略了对流程特色的对比,试验设计的展开同样必须建立在流程的深层剖析基础之上。任何一个问题的产生,都有它的原因,事物的好坏、参数的变异、特性的欠缺等等都有这个特点,而诸多原因一般就存在于产生问题的流程当中。流程的定义非常的关键,过短的流程可能会抛弃掉显著的原因,过长的流程必将导致资源的浪费。我们有很多的方式来展开流程,但有一点必须做到,那就是尽可能详尽的列出可能的因素,详尽的因素来自于对每个步骤地详细分解,确认其输入和输出。其实对于流程的剖析和认识,就是改善人员了解问题的开始,因为并不是每个人都能掌握好我们所关注的问题。这一步的输出,使我们的改善人员能够了解问题的可能因素在哪里,虽然不能确定哪个是重要的,但我们至少确定一个总的方向。
第三步 筛选因素
流程的充分分析,是我们有了非常宝贵的资料,那就是可能影响我们关注指标的因素,但是到底哪个是重要的呢?我们知道,对一些根本就不或微小影响因素的全面试验分析,其实就是一种浪费,而且还可能导致试验的误差。因此将可能的因素的筛选就有必要性,这时,我们不需要确认交互作用、高阶效应等问题,我们的目的是确认哪个因素的影响是显著的。我们可以使用一些低解析度的两水平试验或者专门的筛选试验来完成这个任务,这时的试验成本也将最小处理。而且对于这一步任务的完成,我们可以应用一些历史数据,或者完全可靠的经验理论分析,来减少我们的试验因子,当然要注意一点就是,只要对这些数据或分析有很小的怀疑,为了试验结果的可靠,你可以放弃。筛选因素的结果,使得我们掌握了影响指标的主要因素,这一步尤为关键,往往我们在现实中是通过完全的经验分析得出,甚至抱着可能是的态度。
第四步 快速接近
我们通过筛选试验找到了关键的因素,同时筛选试验还包含一些很重要的信息,那就是主要因素对指标的影响趋势,这是我们必须充分利用的信息,它可以帮助我们快速的找到试验目的的可能区域,虽然不是很确定,但我们缩小了包围圈。这时我们一般使用试验设计中的快速上升(下降)方法,它是根据筛选试验所揭示的主要因素的影响趋势来确定一些水平,进行试验,试验的目的就像我们在寻找罪犯一样的缩小嫌疑范围,我们得出的一个结论就是,我们的改善最优点就在因素的最终反映的水平范围内,我们离成功更近了一步。
第五步 析因试验
在筛选试验时我们没有强调因素间的交互作用等的影响,但给出了主要的影响因素,而且快速接近的方法,使我们确定了主要因素的大致取值水平,这时我们就可以进一步的度量因素的主效应、交互作用以及高阶效应,这些试验是在快速接近的水平区间内选取得,所以对于最终的优化有显著的成效,析因试验主要选择各因素构造的几何体的顶点以及中心点来完成,这样的试验构造,可以帮助我们确定对于指标的影响,是否存在交互作用或者那些交互作用,是否存在高阶效应或者哪些高阶效应,试验的最终是通过方差分析来检定这些效应是否显著,同时对以往的筛选、快速接近试验也是一个验证,但我们不宜就在这样的试验基础上就来描述指标与诸主效应的详细关系,因为对于3个水平点的选取,试验功效会有不足的可能性。
第六步 回归试验
我们在析因试验中,确定了所有因素与指标间的主要影响项,但是考虑到功效问题,我们需要进一步的安排一些试验来最终确定因素的最佳影响水平,这时的试验只是一个对析因试验的试验点的补充,也就是还可以利用析因试验的试验数据,只是为了最终能够优化我们的指标,或者说有效全面的构建因素与水平的相应曲面和等高线,我们增加一些试验点来完成这个任务。试验点一般根据回归试验的旋转性来选取,而且它的水平应该根据功效、因子数、中心点数等方面的合理设置,以确保回归模型的可靠性和有效性。这些试验的完成,我们就可以分析和建立起因素和指标间的回归模型,而且可以通过优化的手段来确定最终的因子水平设定。当然为了保险起见,我们最后在得到最佳参数水平组合后进行一些验证试验来检验我们的结果。
第七步 稳健设计
我们知道,试验设计的目的就是希望通过设置我们可以调控的一些关键因素来达到控制指标的目的,因为对于指标来讲我们是无法直接控制的,试验设计提供了这种可能和途径,但是在现实中却还存在一类这样的因素,它对指标影响同样的显著,但是它很难通过人为的控制来确保其影响最优,这类因素我们一般称为噪声因素,它的存在往往会使我们的试验成果功亏一篑,所以对待它的方法,除了尽量的控制之外可以选用稳健设计的方法,目的是这些因素的影响降低至最小,从而保证指标的高优性能。事实上这些因素是普遍存在的,例如我们的汽车行驶的路面,不可能保证都是在高级公路上,那么对于一些差的路面,我们怎样来设计出高性能呢?这时我们会选择出一些抗干扰的因素来缓解干扰因素的影响,这就是稳健设计的意图和途径。通常我们会经常使用在设计和研发阶段,但有时也会随着问题的产生而暴露出来,但我们会提出一个问题了,重新选定主要因素的水平会不会带来指标的振荡和劣化,这是完全有可能的,但我们可以通过EVOP等途径来重新设定以保证因素更改后的输出效果。
小结:
1.试验设计需要成本的投入,我们必须确定试验进行的必要性,以及选取最优的设计方案。
2.水平的选取可能直接影响试验设计的结果,要谨慎的选取,最后有专业知识和历史数据的支持。
3.尽可能的利用一些历史数据,在确认可靠后提取对我们试验有用的信息,来尽量减少试验投资和缩短试验周期。
4.试验设计并不能提供解决所有问题的途径,现实当中的局限验证了这一点,我们要全面考虑解决问题的方式,选取最有效、最经济的解决途径。
5.注意充分的分析流程,不要遗漏关键的因素,不要被一些经验论的不可能结论左右。
6.除了试验设计涉及的因素外,要尽量确定所有的环境因素是稳定和符合现实的,往往会做不到这一点,我们可以用随机化、区组化来尽量避免。
7.注意结果的验证和控制,不要轻信结果。
8.尽量保证试验的仿真性,避免一些理想的试验环境,比如试验室,理想不现实的环境是的试验可能根本就没有作用。
9.试验设计者要关注试验过程,保证试验意图和方案的彻底执行。
10.如果实现一步到位的试验设计是可能的,那就不要犹豫的开展吧,上面的七步只是针对普通的情况。
八、案例分享
案例一:
举个生活中的例子,相信大家都吃过爆米花,但是大家是否都了解爆米花的制作过程?在品尝爆米花的时候,不知道您是否注意到有很多爆米花没有爆开,也有很多被爆焦。这两种情况都是生产过程中的质量缺陷。

主要因子: 1 )加工爆玉米花的时间(介于 3 至 5 分钟之间); 2 )微波炉使用的火力(介于 5 至 10 档之间); 3 )使用的玉米品牌( A 或 B )。
响应:玉米的 " 爆开个数 " 或“爆开率”。
在爆玉米花时,我们希望所有(或几乎所有)的玉米粒都爆开了,没有(或很少)玉米粒未爆开,这是最终关注的重点。
试验设计的主线是根据因子的取值范围,进行多种参数组合,如下图为两水平试验组合,形成多次试验的方案,依次进行试验后,通过试验结果分析,确定哪一种参数组合是最优的。

利用最小二乘法等拟合方法,建立响应与多个因子之间的数学模型,亦称响应面模型。
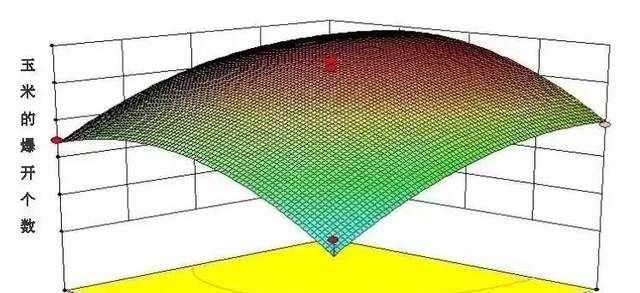
最终通过试验设计确定:使用 A 品牌,加工 5 分钟,并将火力调为 6.96 级。试验预测在此种设置下加工,产出的玉米粒 445 个全部都爆开了。
本文的试验既可以是实物试验,也可以是仿真,在可靠性设计分析中,试验设计常用于解决无法建立显式的可靠性模型等问题,起到事半功倍的作用。
案例二:
DOE在生活中如何应用?
之前在网上看过一个叫《三个罗密欧与一个朱丽叶》的DOE案例,摘录下来跟大家分享,通过这个案例,我们能很容易地理解什么是DOE,了解到其遵循的三项基本原则: 均衡性(Balanced)、随机性(Randomization)和重复性(Replication) 。同时也能体会到使用DOE其实并不需要什么高深的技术,人人都可掌握,甚至在日常生活中也可以运用。
这个案例是Symphony Technologies公司执行总监Ravi与他两位朋友Naren和Deepak的真实故事,他们当年通过试验设计的方法发现了女孩Renu对Deepak情有独钟,最后他俩真的喜结连理,成就一世佳缘。
聪聪、明明和帅帅在大学时每天都一块上学。一个阳光明媚的早上,他们经过一家别墅时,一个叫丽丽的女孩冲出了家门,留给了他们一个含情脉脉的微笑。哇!真漂亮啊!他们惊呆了,三个年轻人很庆幸他们的重大发现,相约每天同一时间经过这栋别墅。他们都喜欢上了丽丽,并且想追求她,但理性告诉他们,丽丽只是喜欢他们中的某一位。他们很想知道这个女孩到底喜欢谁?但都不好意思直接去问。于是,他们发挥聪明才智,设计并实施了一系列实验来确定丽丽所钟情的对象……
他们按设定的方式单独、两两或三人同时经过丽丽的家门口,测试丽丽的反应,以便确认丽丽到底喜欢谁。实验安排如下 :

显然,帅帅是明显的赢家,聪聪和明明握住帅帅的手,祝他好运。
DOE是研究如何制定试验方案,以提高试验效率,缩小随机误差的影响,并使试验结果能有效地进行统计分析的理论与方法。在这个案例中有 三个因子(Factor) :聪聪、明明和帅帅,在试验中所有因子都有计划地被故意改变,并测量每次试验组合时的响应;当事人有两种状态:在场和不在场,这种因子被故意改变的状态就称为 水平(Level) 。一个有效的试验设计可以在同一次试验中改变多个因子,这将大大降低试验的次数,而且能够获得足够的信息使结果可信。
测量的目标变量叫 响应(Response) ,它被表达为丽丽是否出现。而响应的不同称为 效应(Effect) ,可以用上述的分析图来表示。这个案例中所进行的试验是 均衡的(Balanced) ,因为每个人在每种状态下被测试的次数是一样的,这样有助于其公平性。
而不同人员组合的出场顺序是通过掷骰子 随机的(Randomization) 决定的,非随机性的试验中外部因素会以系统性的方式影响到响应的结果,这种风险就是 噪音(Noise) 。试验进行了两周,是为了满足其 重复性(Replication) 的要求,这样可以得到更多的信息,有利于提高评估结果的可信度,但过多的重复次数显然会增加试验过程的成本。
回头再看看两个周日的试验出了什么差错呢?为什么丽丽对帅帅的出现没有作出响应呢?原来,在第一个周日,丽丽的父亲因为琐事将她关在了屋子里。丽丽的父亲是这次试验中不可控制的外部因素,它会随机地突然出现,影响丽丽的响应从而混淆试验结果。看来用 潜在变量(Lurking Variable) 定义丽丽的父亲最合适不过了。在第二个周日,丽丽因为心情不好而没有如期出现。毕竟她是人,不能期望她的行为总是保持与统计的规律一致,这就是在试验中经常会遇到的 试验误差(Experimental Error) 。
DOE固然是一种高级的质量工具,也的确有着非常复杂和庞大的理论系统和统计知识,要说懂,绝非易事。但我们没有必要去崇拜或者惧怕它,在品质管理的过程中,我们的目的是为了解决问题,而不是做学问搞研究,只要结合实际的需求,把握住其应用本质,在荆棘丛生的路,也终究会豁然开朗,柳暗花明。
<完>
质量
绿色
创新
人本
1.《质量工具丨DOE(试验设计)介绍》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《质量工具丨DOE(试验设计)介绍》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/tiyu/24050.html