
前言
我应该先写这个索引,只能说最后一篇博客写的早。
涉及的知识点/你能知道的点,关键词
索引原理,底层存储;
二叉树、二叉树
聚集索引、非聚集索引、联合索引、覆盖索引
为什么索引无效/索引无效原则
主体

什么是指数?
索引是一种分散的数据结构,创建它是为了加快表中数据行的检索
为什么索引
索引可以大大减少存储引擎需要扫描的数据量
索引可以把随机IO变成顺序IO
索引可以帮助我们避免在分组和排序时使用临时表。
索引上数据结构的比较
二叉树
二叉树,不说别的,有个致命的问题。如果存储的数据是在极端情况下,它将直接成为一个链表
平衡二叉树
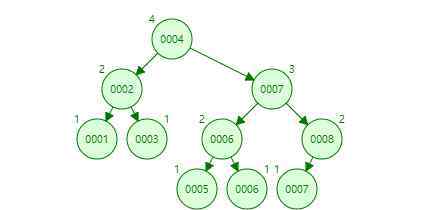
这里,二叉树是相对平衡的树,叶节点的高度差等于1
平衡二叉树解决了上面二叉树提到的问题。
但是仍然存在一些问题:
1.平衡二叉树的高度还是很高的,每个节点只有两个分支。
2.操作系统的io预读能力没有得到很好的利用
内存和磁盘数据交互的单位是页,一页的大小是4k还是8k
即主io的大小为4k,平衡二叉树的每个节点只存储一个数据,部分引用远远不足以填充4k 空的空间
b树多路径平衡查找树
兄弟,我真的不想听任何人念B减Tree。
应该看什么?难道我心里没有秩序吗

B-Tree解决了上面两个问题,然后它有一些属性:
1.B-Tree是一棵绝对平衡的树,叶子永远在一层。
2.在mysql中,充分利用了io的预读能力,每次io取出的数据都是16 K。
只看图中每一个方块。他的尺寸是16 K。
如果索引的数据类型是int,int的大小是4k,如果计算一些引用,那么每个节点的锁中存储的数据是16/4+2k个数据。当然这个数据没必要当真,看看就好。
同时,当存储相同数量的数据时,树要短得多
3.在B树中,节点的数据去间隔属于左开和右开间隔,最大节点数=最大路径数-1
b+树增强型多路平衡查找树

b+树属于增强型B-树,具有B-树的所有优点
但与B-Tree略有不同:
最大节点数=最大路径数
数据间隔是左闭右开的间隔
最大的区别是只有叶节点存储数据,非叶节点只存储关键字和引用
并且节点直接按顺序排列,参考相邻节点
优于二叉树
1.它是B-Tree的增强版,具有B-Tree的所有优点
2.扫描图书馆的能力更强
从图上的数据结构来看,b+树的叶节点形成了一个链表,所以在查询范围时,数据会沿着链表进行扫描,不会返回到上级节点。
3.磁盘具有较强的读写能力
因为,他比b树多了一条路
4.分选能力更强
原因同上
5.查询效率更加稳定
数据都存储在叶节点上,所以随机访问时这个时候IO是一样的,所以时间差不多。
数据结构网站:https://www.cs.usfca.edu/~画廊/可视化/算法
我上面的图就是从这里剪下来的,然后感兴趣的同学可以看看,看看数据是如何在各种数据结构中插入、删除、搜索的。
数据在引擎中的存储
不知道大家对引擎了解多少,然后应该有一篇略短的文章介绍几个mysql引擎。
在这里,我们需要知道在不同的引擎下,数据库中数据的具体存储是不同的。
让我们来介绍一下innodb和myisam中的数据存储情况
引擎
看一张以前画的旧画
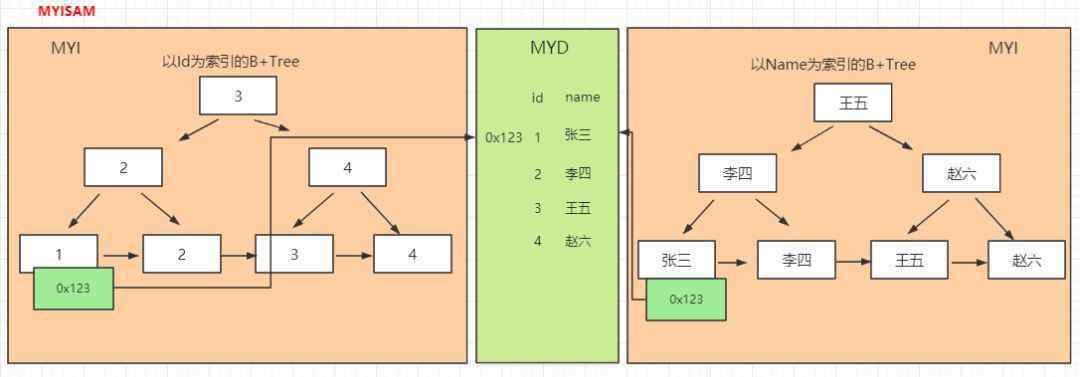
在myisam中,数据表将生成三个文件:。frmmyi.myd。
那个。frm文件存储数据表的表结构,这里不强调,它是一个将在所有引擎中生成的文件
。myi文件,它在表中存储索引。
。myd文件,它将数据存储在表中。
在myd中,是数据,如图。
将在MYI生成多个非聚集索引树,左侧的索引树为标识,右侧的索引树为名称。当然,它们都在一个文件中,只是为了更好的性能而在两侧绘制。当始终检索叶节点时,其保存的数据也是相应的引用,它指的是磁盘上的实际物理地址。
引擎
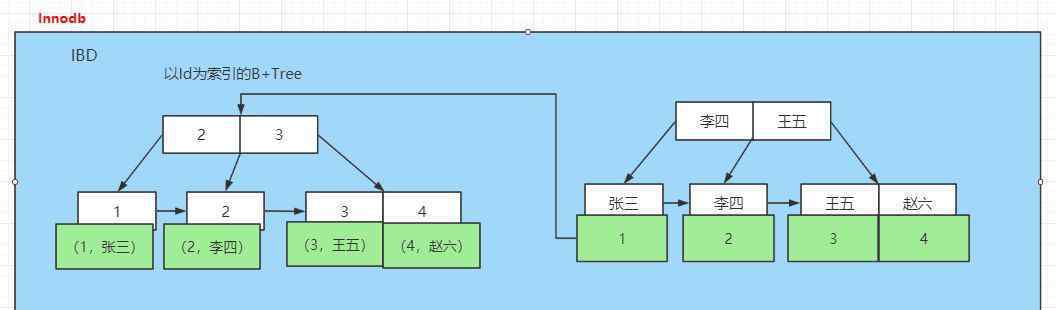
innodb下会生成两个文件,所以不会提到frm,所以只使用一个IBD文件来存储数据。
IBD存储的是数据和索引,包括一个按标识索引的聚集索引树和多个非聚集锁索引。
其中以ID为索引的聚簇索引树,叶节点包含某一行的所有数据。别问我什么是聚集索引,我会告诉你的
那么其他索引的索引树就是非聚集索引,叶子节点存储它们对应的id。
在用非聚集索引树搜索数据时,我们会先通过非聚集索引树找到对应的主键,然后在以主键为索引的聚集索引树中找到对应的主键,最后找到需要的数据。
这里我们扩展了两个概念,组合指数和覆盖指数。
复合索引,顾名思义,你可能理解为多个索引加在一起,所以我现在纠正一下它的名字。对于一般的索引,我们称之为单值索引。当多个字段放在一起作为索引时,我们称之为复合索引。事实上,当复合索引字段为1时,单值索引并不是一种特殊情况。
覆盖索引。如果选择字段/数据,可以直接通过索引树找到数据,不需要再在聚集索引的叶节点找到数据。此时,我们要求他覆盖索引。
例如,在上图中,在添加了电话和电子邮件等其他字段后,我们从表中选择了身份证、姓名、姓名= '张三'
此时,只能在名称的索引树中找到并返回id和名称。
无效索引
我相信索引是无效的,很多同学都是死记硬背的。背诵当然是一种方法,或者有一些顺口溜。
他们都很好。如果你愿意,你可以被接受,但要明白为什么这样更好。
其实索引和数据的存储上面都有提到,失败的原因已经在其中了。
我总结了一句话,就是永远不要让系统不堪重负。
例如,使用
其他情况也一样。
这里说的是一个问题,比如什么时候到期,什么时候背,什么时候不到期,可以继续背。这里我们添加一个离散的问题
离散性的主要问题是,当你创建一个索引的时候,如果一个列的离散性很差,那么你用的时候可能就不行了,这是系统优化的一个点。其实还是和上面一样。你的指数离散型好差,我好困惑,不知道该何去何从。我还不如自己遍历整个表。你应该去呆在凉爽的树下。你最好找一棵榴莲树。
基本上索引失效的问题就到此为止了。
优化
我不能谈论光的原理,
现在来说一些可以优化的部分。对于以上内容,可以消化优化点,不懂的可以回去通过优化点找到共鸣
-索引列的数据长度可以尽可能小
-索引不能尽可能多,但要尽可能完整
-匹配的列前缀可用于索引,如99%,如%99%不能使用索引。
-不是int和
-匹配范围值、排序依据、分组依据也可以使用索引
-使用更多指定的列进行查询,只返回所需的数据列,使用更少的select *;
-表达式和函数不能用于索引列
-对于过长的字符串,需要通过创建前缀索引来创建索引;
如果不从联邦索引中索引的最左边开始查找,就不能使用该索引
该索引可用于联合索引中与最左边的第一行完全匹配并与范围匹配的另一列
在联邦索引中,如果查询中有一列的范围查询,则它右边的所有列都不能使用该索引;
标签
你好,沃洛德
-
原文:https://blog.csdn.net/wangjinlong_/article/details/85951720
版权声明:本文为博主原创文章。请附上博客链接转载!
1.《索引 【数据库】——Mysql索引的底层剖析》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《索引 【数据库】——Mysql索引的底层剖析》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1666962.html