选自tryolabs
参与:、黄、蒋思远
本文作者总结了2017年NLP领域深度学习技术的进展及其未来发展趋势,并与大家分享作者今年最喜欢的研究。2017年是NLP领域的重要一年。深度学习得到了广泛的应用,这种趋势还会继续。
近年来,深度学习体系结构和算法在图像识别和语音处理领域取得了很大进展。起初,深度学习在自然语言处理中的表现并不令人印象深刻,但现在我们可以看到深度学习对自然语言处理的贡献,并在许多常见的自然语言处理任务中取得了顶尖的结果,如命名实体识别、词性标注或情感分析,其中神经网络模型优于传统方法。而机器翻译的进步也许是最显著的。
在本文中,我将总结2017年自然语言处理领域深度学习技术的进展。可能会有疏漏,毕竟覆盖所有的论文、框架、工具太难了。我想和你分享一些我今年最喜欢的研究。我觉得2017年对NLP来说是重要的一年。深度学习在自然语言处理中得到了广泛的应用,并在许多分支取得了令人印象深刻的成果,这些都表明这一趋势不会停止。
从训练单词2到使用预训练模型
可以说,单词嵌入是最广为人知的自然语言处理深度学习技术。它遵循哈里斯提出的分布式假设,根据该假设,具有相似含义的单词通常出现在相似的上下文中。要了解更多关于单词嵌入的知识,建议阅读文章“单词嵌入:如何将文本转换成数字”。
分布式词语向量示例。
Word2vec和Glover是该领域的先锋算法。虽然不能称之为DL,但是它们训练出来的模型通常作为NLP方法的输入数据进行深度学习。效果很好,所以越来越多的人开始使用单词嵌入。
最初,对于需要嵌入单词的自然语言处理问题,我们倾向于通过使用与该领域相关的大型语料库来训练我们自己的模型。当然,这并不是促进单词嵌入广泛使用的最佳方式,所以人们开始慢慢转向预训练模式。通过在维基百科、推特、谷歌新闻、网页抓取等上的训练,这些模型可以很容易地将单词嵌入到DL算法中。
今年,证实了预训练单词嵌入模型仍然是NLP的核心问题。比如Facebook人工智能实验室的fastText发布了294种语言的预训练向量,对社区的贡献很大。除了大量的语言之外,fastText的用处在于它使用了n元这个字符作为它的特征。这使得fastText避免了OOV问题,因为即使是非常罕见的单词也可能与普通单词共享字符N元。从这个意义上来说,fastText的性能比word2vec和GloVe更好,在小数据集上也更好。
然而,尽管我们看到了一些进展,但在这一领域仍有许多工作要做。例如,NLP框架spaCy通过集成单词嵌入和DL模型在本地完成命名实体识别和依赖解析等任务,允许用户更新模型或使用他们自己的模型。
我觉得这是趋势。未来会有针对特定领域的岗前培训模式。),这在NLP框架中很容易使用。就我们的用法而言,锦上添花的是用尽可能简单的方式调整它们。与此同时,嵌入自适应词的方法开始出现。
使用通用嵌入来适应特定的用例
也许使用预训练单词嵌入的主要缺点是训练数据和真实数据之间的单词分布差距。假设你有一个生物论文、食谱或经济研究论文的语料库。由于您可能没有足够大的语料库来训练嵌入,嵌入常用单词可能会帮助您提高结果。但是,如果您可以根据您的特定用例来调整通用嵌入呢?
在NLP中,这种自适应通常称为跨域或域自适应技术,与迁移学习非常接近。杨等人今年提出了一个很有意思的工作。给定源域嵌入,他们展示了一个正则化的跳格模型来学习目标域中的单词嵌入。
它的核心思想简单却有效。想象一下,如果我们知道源域中的w这个词嵌入为w_sws。为了计算w_twt的嵌入,研究人员在w_sws中加入了两个域之间的特定迁移。基本上,如果单词经常出现在两个域中,就意味着它们的语义不依赖于域。这种情况下迁移量很大,两个域生成的嵌入可能是相似的。然而,如果一个特定域的单词在一个域中出现的频率比在另一个域中出现的频率高得多,那么迁移量就很小。
没有得到广泛的探索,我认为在不久的将来会得到更多的关注。
情感分析令人难以置信的“副作用”
青霉素,x光,甚至邮件都是意想不到的发现。今年,拉德福德等人发现训练模型中的单个神经元具有高度可预测的情感值,并探索了字节级循环语言模型的属性,旨在预测亚马逊评论文本中的下一个字符。是的,这个单一的“情绪神经元”可以相当准确地区分负面评论和正面评论。
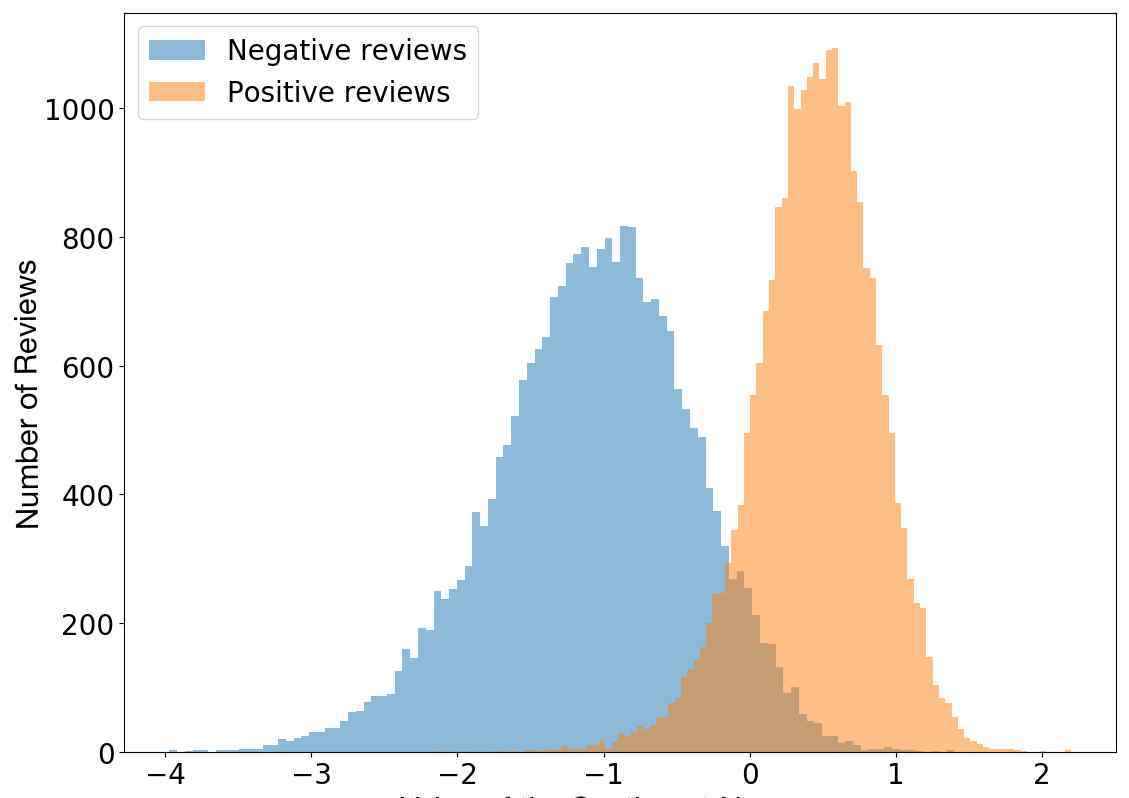
评论极性vs神经元值。
注意到这一行为后,拉德福德等人决定在斯坦福情感树库上对该模型进行测试,测试结果表明其准确率高达91.8%,而之前的最优结果为90.2%。这意味着通过显著减少实例的使用,他们以无监督的方式训练的模型至少在一个特定但被广泛研究的数据集上获得了目前最好的情感分析结果。
运行中的情绪神经元
因为模型是在角色级别工作的,所以神经元会为文本中的每个角色改变状态,其工作方式似乎相当惊人。

情感神经元的行为。
比如单词best后,神经元值强正;然而,当“可怕”这个词出现时,神经元值的状态完全相反。
生成极性有偏差的文本
当然,训练好的模型仍然是一个有效的生成模型,所以可以用来生成类似亚马逊评论的文本。但是,我发现你可以简单地重写情感神经元的值,选择生成文本的情感级别。

生成一个文字示例。
拉德福德等人选择的神经网络模型是克劳斯等人在2016年提出的乘法LSTM。之所以选择这个模型,是因为他们观察到,在给定的超参数设置下,乘法LSTM的收敛速度比一般LSTM快。该模型有4096个单元,在8200万个亚马逊评论语料库中进行训练。
推特上的情感分析
Twitter上的情感分析是一个非常强大的工具,无论是获取客户对企业品牌的评价,分析营销活动的影响,还是民意调查。
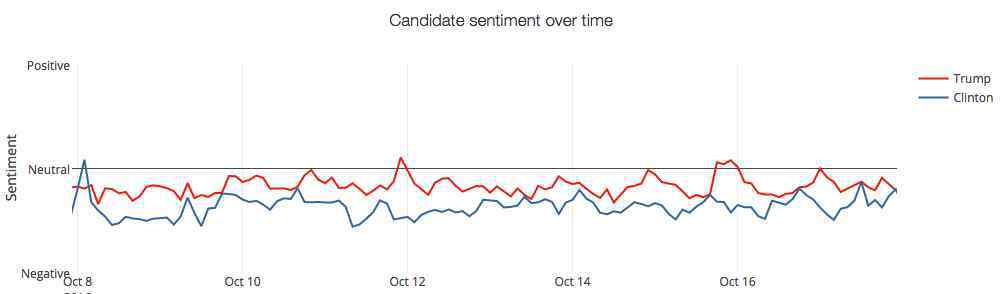
特朗普和希拉里在Twitter上的情感分析。
SemEval 2017
Twitter中的情感分析不仅引起了NLP研究人员的关注,也引起了政治和社会科学的关注。这也是为什么从2013年开始,SemEval竞赛就设立了Twitter情感分析任务。
今年共有48个团队参与任务,可见人们对Twitter情感分析的重视。为了说明SemEval竞赛中Twitter情感分析的内容,我们来看看今年竞赛的子任务:
子任务A:给定一条推文,判断推文表达的情绪是积极的、消极的还是中性的。
子任务B:给定一条推文和一个话题,区分推文传达给话题的情绪是积极的还是消极的。
子任务C:给定一条推文和一个话题,区分推文传达给话题的情感是强正、弱正、中性、弱负还是强负。
子任务D:给定一组关于同一话题的推文,评估正面推文和负面推文的分布情况。
子任务E:给定一组关于同一话题的推文,评价这组推文在强正、弱正、中性、弱负、强负中的分布情况。
其中,子任务A是最常见的情感分析任务,有38个团队参与这个任务,但其他几个任务更具挑战性。组织者表明,深度学习方法的使用是突出的,并不断改进。今年,20个团队采用了深度学习模式,如CNN和LSTM。此外,虽然SVM模型仍然很受欢迎,但许多参赛者将它们与神经网络方法结合起来,或者使用文字嵌入特征。
BB_twtr系统
我发现今年让我印象深刻的是一个纯DL系统BB_twtr,在英语任务的五个子任务中排名第一。本系统作者将10个CNN和10个双向LSTM结合起来,采用不同的超参数和预训练策略进行训练。
为了训练这个模型,作者使用人工标注的推文构建了一个包含1亿条推文的未标注数据集。作者只是通过表情符号将推文标记为积极情绪或消极情绪,并从中提取出一个孤立的数据集。为了嵌入预先训练好的单词作为CNN和双向LSTM的输入,作者使用word2vec、GloVe和fastText在未标记的数据集上构造单词嵌入。然后他利用之前孤立的数据集对单词嵌入进行细化,添加正负信息,最后利用人工标注的数据集再次进行细化。
之前使用SemEval数据集的经验表明,使用GloVe会降低性能,对于所有的标准数据集都没有唯一的最优模型。因此,笔者将所有模型与软投票策略相结合,用这种方法产生的模型优于2014年和2016年的模型。
即使这种结合不是有机进行的,这种简单的软投票策略也证明了模型的有效性,所以这项工作展示了结合DL模型的潜力,端到端方法在Twitter情感分析任务中的性能优于监督方法。
激动人心的抽象抽象系统
自动摘要是类似机器翻译的自然语言处理任务。自动摘要系统有两种主要方法:提取——从源文本中提取最重要的部分来创建摘要;创成式——通过生成文本来创建摘要。从历史的角度来看,提取自动摘要方法是最常用的,因为它的简单性优于生成自动摘要方法。
近年来,基于RNN的模型在文本生成领域取得了惊人的成就。他们在短的输入输出文本上工作得很好,但在处理长文本上不太擅长,长文本不一致,重复。保卢斯等人提出了一种新的神经网络模型来克服这一局限性。结果很好,如下图所示。

自动摘要生成模型图。
保卢斯等人使用biLSTM编码器读取输入,使用LSTM解码器产生输出。他们的主要贡献是一种新的内部注意策略,这种策略分别关注输入和连续生成的输出。和强化学习相结合的新训练方法。
注意力策略
目标是避免重复输出。研究人员在解码时使用时间注意力来查看输入文本之前的片段,从而确定接下来要生成的单词。这迫使模型在生成过程中使用输入的不同部分。他们还要求模型评估解码器中先前的隐藏状态。然后结合这两个函数在输出摘要中选择最合适的词。
强化学习
创建摘要时,两个人会使用不同的单词和句子序列,两个摘要可能都有效。所以好的摘要的词序不一定和训练数据集中的顺序匹配。基于此,作者没有使用标准的教师强制算法,可以最大限度地减少每个解码步骤的损失;相反,他们使用强化学习策略,这被证明是一个很好的选择。
几乎是端到端模式的结果
该模型在CNN/Daily Mail数据集上进行了测试,目前取得了最好的结果。此外,涉及人类评估员的具体实验证明,人类的阅读能力和质量也有所提高。经过基本的预处理,得到这样的结果是很神奇的,包括:标记输入文本,降低大小写,用0替换数字,去除数据集中的一些实体。
走向完全无监督机器翻译的第一步
双语词典的构建,即利用源语言和目标语言的单语语料库获取两种语言的词向量之间的映射关系,是一项古老的自然语言处理任务。双语词典的自动构建在信息检索、统计机器翻译等自然语言处理任务中起着一定的作用。但是,这种方法主要依赖于初始双语词典,通常不容易获得或构建。
随着单词嵌入的成功,跨语言单词嵌入出现,其目标是在空之间对齐嵌入而不是字典。不幸的是,这种方法仍然依赖于双语词典或平行语料库。Conneau等人在论文中提出了一种有前途的方法,该方法不依赖于任何特定的资源,在单词翻译、句子翻译检索和跨语言词汇相似性等任务上优于顶级的监督方法。
该方法以在单语数据上训练的两种语言的单词嵌入集为输入,然后学习它们之间的映射,使得共享空中的翻译结果接近。他们使用在维基百科文档上用fastText训练的无监督单词向量。下图显示了它的主要思想:
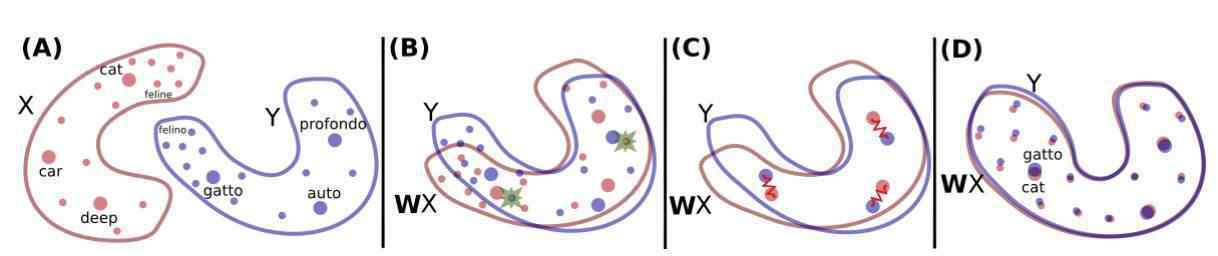
构建空中嵌入的两个单词之间的映射。红色的X分布是英语单词的单词嵌入,蓝色的Y分布是意大利语单词的单词嵌入。
首先,他们使用反学习学习旋转矩阵w,w来执行第一次原始对齐。它们基本上是按照Goodfellow等人的命题训练生成对抗网络。要直观了解GAN的工作原理,建议阅读https://try olabs . com/blog/2016/12/06/major-advances-deep-learning-2016/。
为了用对抗学习来建模问题,他们让鉴别器具有决定性,从WX和Y中随机抽取一些元素,这些元素属于WX和Y,然后训练W,阻止鉴别器做出准确的预测。在我看来,这种做法很巧妙,很优雅,直接效果也很好。
之后,他们分两步重新定义了映射。一步是为了避免映射计算中稀有词带来的噪声,另一步是利用学习到的映射和距离度量来构造实际的翻译结果。
这种方法在某些情况下效果很好。例如,在英语-意大利语单词翻译中,在P@10中,该方法对1500个源单词的准确率比最优平均准确率高近17%。
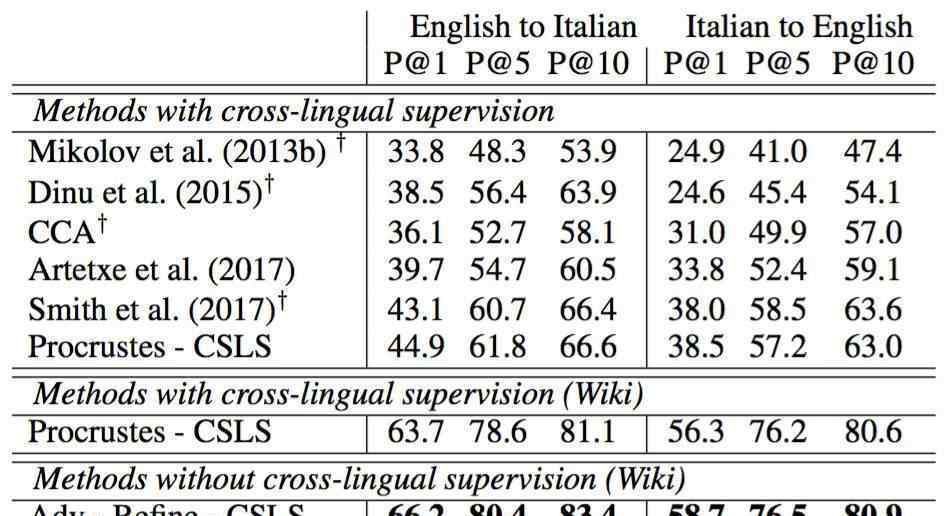
英语-意大利语单词翻译的平均准确率。
Conneau等人声称他们的方法是走向无监督机器翻译的第一步。如果是这样,那就太好了。这种新方法能走多远还有待观察。
专用框架和工具
有大量的通用的DL框架和工具,其中一些被广泛使用,比如TensorFlow、Keras和PyTorch。然而,用于NLP的开源DL框架和工具已经出现。2017年对我们来说是重要的一年,因为许多有用的开源框架对社区开放。其中三个特别引起了我的注意,你可能会觉得它们很有趣。
AllenNLP
AllenNLP框架是一个基于PyTorch的平台,可以在语义NLP任务中轻松使用DL方法。它的目标是让研究人员设计和评估新的模型。该框架包括常见语义自然语言处理任务的模型引用实现,如语义角色标注、字面含义和共指解析。
ParlAI
ParlAI框架是一个用于对话研究的开源软件平台。它是用Python实现的,目标是为对话模型的共享、培训和测试提供一个统一的框架。ParlAI提供了一种与亚马逊土耳其机器人轻松集成的机制。它还提供了该领域常用的数据集,支持多种模型,包括记忆网络、seq2seq和注意力LSTM等神经网络模型。
OpenNMT
OpenNMT toolkit是一个序列到序列模型的通用框架,可用于执行机器翻译、摘要、图像到文本和语音识别等任务。
标签
不可否认,解决NLP问题的DL技术在不断发展。一个重要的指标是近年来在美国公民自由联盟、欧洲公民自由联盟、EACL和全国公民自由联盟等重要的全国公民自由联盟会议上深度学习论文的比例。
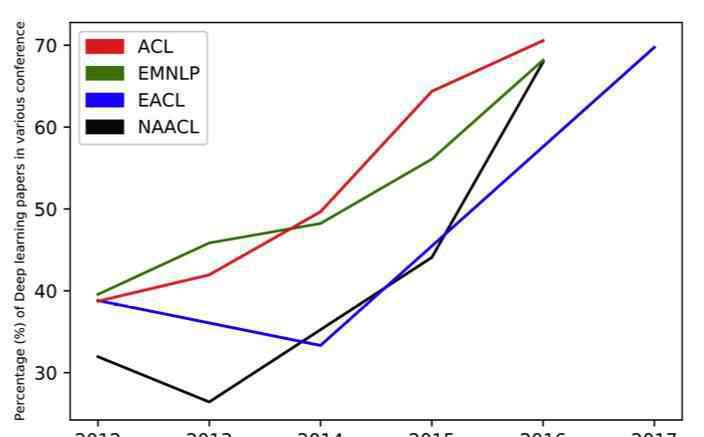
深度学习论文在NLP会议论文中的比例。
然而,对端到端学习的研究才刚刚开始。我们仍然通过处理一些经典的NLP任务来准备数据集,例如清理、标记化或统一一些实体。).我们也使用通用嵌入,但是缺点是他们无法捕捉到特定领域术语的重要性,也没有很好的处理多词表达,这是我在以往的项目中多次发现的一个重要问题。
2017年是深度学习应用于NLP的伟大一年。希望2018年,端对端学习的研究更多,专业开源框架更加完善。
扩展阅读
《自然语言处理研究中的深度学习方法:基于深度学习的自然语言处理的最新趋势》,杨等:https://arxiv.org/pdf/1708.02709.pdf
从字符到理解自然语言:健壮的面向NLP的端到端深度学习,Blunsom等:http://drops . dagstuhl . de/opus/vollte ext/2017/7248/pdf/Dag rep _ v 007 _ i001 _ p129 _ s 17042 . pdf
CNN与RNN自然语言处理的比较研究,尹等:
GAN的工作原理:2016年深度学习的重大进展,pablo Soto:https://tryolabs . com/blog/2016/12/06/major-advances-deep-learning-2016/
Word嵌入:如何将文本转换成数字,Gabriel morde CKI:https://monkey learn . com/blog/word-embeddeds-transform-text-numbers/
《2017年的文字嵌入:趋势和未来方向》,塞巴斯蒂安·路德:http://ruder.io/word-embeddings-2017/
引用
从字符到理解自然语言:对NLP Phil Blunsom,Kyunghyun Cho,克里斯·戴尔和Hinrich Schütze 健壮的端到端深度学习
BB_twtr at SemEval-2017任务4:使用CNNs和LSTMs Mathieu陈腔滥调进行推特情感分析
无平行数据的词汇翻译:亚历克西斯·康瑙、纪尧姆·兰普勒、马克·奥雷利奥·兰扎托、卢多维奇·德诺尔、埃尔韦·吉古
生成性对抗网伊恩·古德费勒、让·普格特-阿巴迪、迈赫迪·米尔扎、徐炳、大卫·沃德-法利、谢尔吉尔·奥泽尔、亚伦·库维尔和约西·本吉奥
泽利·哈里斯
神经机器翻译的开源工具包。
本·克劳斯、梁璐、伊恩·默里和史蒂夫·雷纳尔斯的序列建模乘法lstm
Parlai:对话研究软件平台Alexander H Miller,Will Feng,Adam Fisch,Lu,Dhruv Batra,Antoine Bordes,Devi Parikh和Jason Weston
连续空间词表征的语言规律
《手套:单词表征的全球向量》,杰弗里·潘宁顿、理查德·索舍尔和克里斯托弗·曼宁
学习产生评论和发现情绪亚历克拉德福德,拉斐尔约泽福维茨和伊利亚苏斯克弗
一种简单的基于正则化的跨域单词嵌入学习算法
美国有线电视新闻网与RNN自然语言处理的比较研究
基于深度学习的自然语言处理的最新趋势
原文链接:https://try olabs . com/blog/2017/12/12/deep-learning-for-NLP-advances-and-trends-in-2017/
这篇文章是为机器的核心编写的。请联系本微信官方账号进行授权。
1.《nlp 深度 | 一文概述2017年深度学习NLP重大进展与趋势》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《nlp 深度 | 一文概述2017年深度学习NLP重大进展与趋势》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1700409.html