全球人工智能
现在我们再来演示一下。通过神经网络分析观察到的信息,选择左侧的行为。我们直接进行反向传输,增加下次被选中的可能性。但是奖惩信息告诉我们这次的行为是不好的,所以我们行动可能性的增加会减少。这样,我们就可以依靠奖励来影响我们神经网络的反向传递。再举个例子。如果这个观察信息让神经网络选择了正确的行为,然后正确的行为想进行反向传播,那么下次选择正确的行为会更多,这时奖惩信息也来了,告诉我们这是一个好的行为,那么我们在这个反向传播中会付出更大的努力,这样下次选择会更猛烈!这是政策梯度的核心思想。很简单。

什么是演员-评论家?
今天我们就来讲一个强化学习的组合,Actor criteria,它结合了基于值(比如Q学习)和动作概率(比如策略梯度)的两种强化学习算法。
以下是演员-评论家的简短视频介绍:
为什么有演员和评论家
我们有一个像Q学习这样伟大的算法,为什么我们要修改一个演员评论家?原来,演员-评论家演员的前生是政策梯度,这样就很容易在连续动作中选择合适的动作,但是Q-learning这样做就会瘫痪。为什么不直接使用策略梯度?本来Actor批评家的前身是Q-learning或者其他基于价值的学习方法,可以一步更新,而传统的Policy Gradients是轮更新,降低了学习效率。
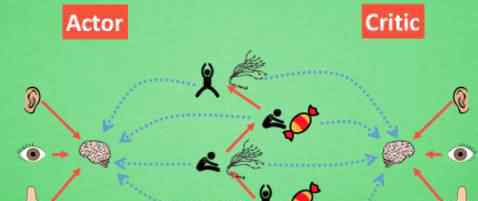
演员兼评论家

现在我们有两个不同的系统,Actor和criteria,可以用不同的神经网络代替。正如《政策梯度》这部电影所提到的,现实中的奖惩会影响《演员》的更新。策略梯度也依赖于此来获得适当的更新。那么什么时候会有可以学习的奖惩呢?这不就是价值基础强化学习法所做的吗?那么让我们拿一个批评家来学习这些奖励和惩罚机制。学完之后,演员会告诉演员你做的好,做的不好。批评家利用学习环境和奖励之间的关系。你可以看到你当前状态下的潜在奖励,所以用它来指出Actor可以让Actor每一步都更新。如果使用简单的策略梯度,参与者只能等到回合结束后才能开始更新。
添加单步更新属性
然而,事情总有不好的一面。actor-critice涉及两个神经网络,每次参数连续更新,每次参数更新前后都有相关性,导致神经网络只片面地看问题,甚至导致神经网络什么都不学。Google DeepMind修改了Actor批评家的算法来解决这个问题。
深度确定性策略梯度(ddpg)的改进版本

在电子游戏雅达利中成功使用的DQN网络被添加到演员评论系统中。这种新算法被称为深度确定性策略梯度,它成功地解决了连续运动预测中不学习任何东西的问题。那么,让我们来谈谈什么是深度确定性策略梯度的高级版本。
知乎张文链接:
https://zhuanlan.zhihu.com/p/25290858
https://zhuanlan.zhihu.com/p/25829036
https://zhuanlan.zhihu.com/p/25831658
热门文章推荐
1.《大强化 干货|三大强化学习武器的作用和使用方法(附视频)》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《大强化 干货|三大强化学习武器的作用和使用方法(附视频)》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/801725.html









