本文转载授权机心,禁止转载两次。
选自kdkings,机器之心编译,参加:特伦斯L,李亚洲;
原文链接:http://mp.weixin.qq.com/s/-1Ze6jXQP4lAm-oRNWFmEw
引导阅读
最新的KDKings调查显示了数据科学家最常用的算法列表。这个列表包含了很多惊喜,包括最学术的算法和面向产业化的算法。
在过去的12个月中,您将哪些方法/算法应用于实际的数据科学相关应用?
这是基于844名选民的投票结果
十大算法及其投票者比例如下:

图1:数据科学家使用的十大算法
在文章的最后,列出了所有的算法
每位受访者平均使用8.1种算法,与2011年类似调查的结果相比,这是一个巨大的增长
与2011年的数据分析/数据挖掘调查相比,我们注意到回归、聚类、决策树/规则和可视化仍然是最常用的方法。增幅最大的是确定的以下算法:
从2011年的23.5%到2016年的32.8%,同比增长40%
文本挖掘,从2011年的27.7%到2016年的35.9%,同比增长30%
可视化,从2011年的38.3%上升到2016年的48.7%,同比增长27%
时间序列/序列分析,从2011年的29.6%到2016年的37.0%,同比增长25%
异常/偏差检测,从2011年的16.4%上升到2016年的19.5%,同比增长19%
综合方法,从2011年的28.3%到2016年的33.6%,同比增长19%
支持向量机,从2011年的28.6%到2016年的33.6%,同比增长18%
回归,从2011年的57.9%到2016年的67.1%,同比增长16%
在2016年的调查中,最受欢迎的算法有了新的列表:
K-最近的邻居,46%
主成分分析,43%
随机森林,38%
优化,24%
神经网络-深度学习,19%
奇异值分解,16%
降幅最大的是:
关联规则从2011年的28.6%下降到2016年的15.3%,同比下降47%
隆起形态从2011年的4.8%下降到2016年的3.1%,同比下降36%
因子分析,从2011年的18.6%到2016年的14.2%,同比下降24%
生存分析,从2011年的9.3%到2016年的7.9%,同比下降15%
下表显示了不同算法类型的使用:监督算法、非监督算法、元算法,以及由职业类型决定的算法的使用。我们排除了北美和其他职业类型。
职业类型
投票率%
使用的算法的平均数量
%监控算法使用情况
%无监督算法使用
%元使用率
%其他方法使用
一个
工业
59%
8.4
94%
81%
55%
83%
2
政府/非营利组织
4.10%
9.5
91%
89%
49%
89%
三
学生
16%
8.1
94%
76%
47%
77%
四
学术界
12%
7.2
95%
81%
44%
77%
五
整体
8.3
94%
82%
48%
81%
表1:根据职业类型使用不同的算法
我们注意到几乎每个人都使用监督学习算法。
政府和工业数据科学家比学生和学术研究人员使用更多不同类型的算法,而工业数据科学家更喜欢使用元算法。
接下来我们按照职业类型分析了算法+深度学习的前10种用法。
运算法则
工业
政府/非营利组织
学术界
学生
整体
1回归71%63%51%64%67%2聚类58%63%51%58%57%3决策59%63%38%57%55%4可视化55%71%28%47%49%5K-近邻法46%54%48%47%46%6主成分分析43%57%48%40%43%7统计47%49%37%36%43%8随机森林40%40%29%36%38%9时间序列42%54%26%24%37%10文本挖掘36%40%33%38%36%11深度学习18%9%24%19%19%表2:按职业类型分类的十大算法+深度学习用法
为了更清楚地看到差异,我们计算了特定职业分类相对于平均算法使用的算法偏差,即偏差 =使用/使用
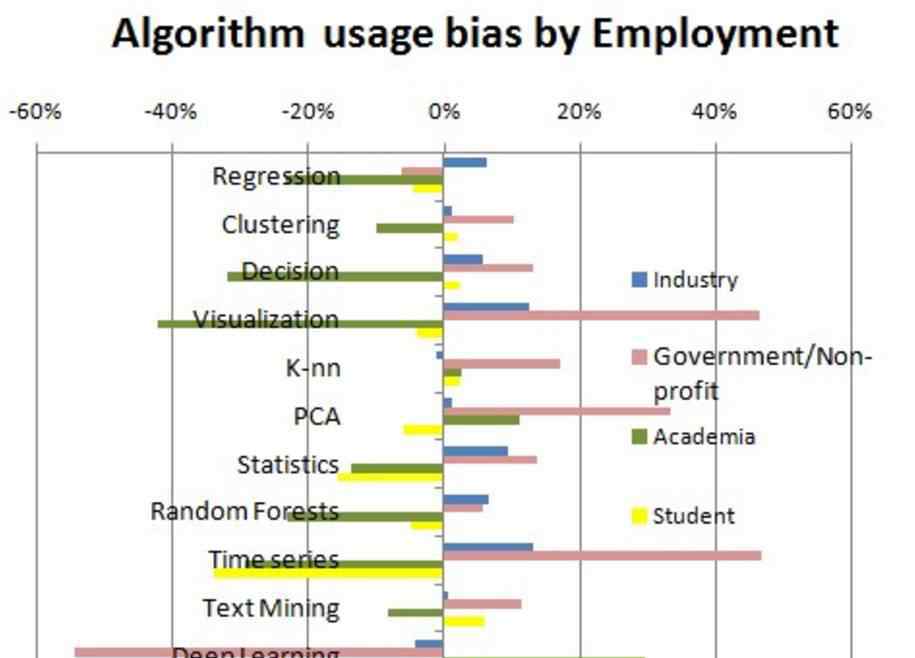
图2:职业对算法的偏好
我们注意到,工业数据科学家更倾向于使用回归、可视化、统计、随机森林和时间序列。政府/非营利组织更喜欢使用可视化、主成分分析和时间序列。学术研究者更喜欢使用主成分分析和深度学习。学生一般用的算法比较少,但大多是文本挖掘和深度学习。
接下来,让我们来看看特定地区的参与情况,指出kdkings的总体用户:
美国/加拿大,40%
欧洲,32%
亚洲,18%
拉丁美洲,5%
非洲/中东,3.4%
澳大利亚/新西兰,2.2%
在2011年的调查中,我们将行业/政府分为一组,将学术研究/学生分为第二组,计算算法对行业/政府的善意度:
N / N
- - 1
N / N
因此,亲密度为0的算法意味着它在行业/政府和学术研究人员或学生之间平等使用。ig亲密度越高,算法在工业界的应用越广泛,越接近“学术”。
最“工业化”的算法是:
异常检测,1.61
生存分析,1.39
因子分析,0.83
时间序列/系列,0.69
关联规则,0.5
向上建模是最“工业算法”。令人惊讶的是,它的利用率极低——只有3.1%——是本次调查算法中最低的。
最学术的算法是:
传统神经网络,-0.35
朴素贝叶斯,-0.35
支持向量机,-0.24
深度学习,-0.19
EM,-0.17
下图显示了所有的算法和它们的工业/学术亲密度。
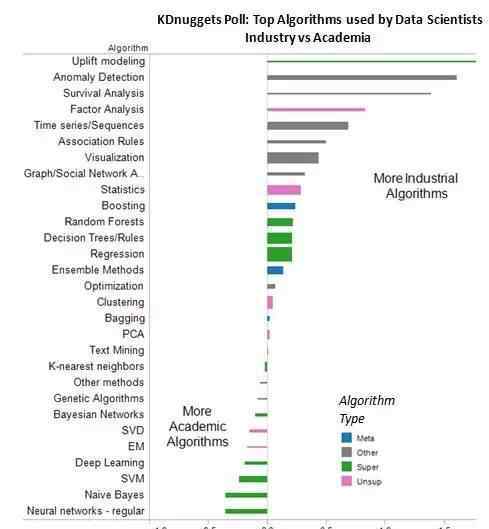
图3: KD掘金投票:数据科学家最常用的算法:工业界VS学术界
下表详细介绍了算法、两次调查中使用的算法比例以及如上所述的行业友好性。
下图按列显示了算法的详细信息
n:根据使用情况排名
算法,命名算法,
类型:S-监督,U-监督,M-元,Z-其他,
2016年调查中使用此算法的受访者比例
在2011年调查中使用该算法的受访者比例
变化,
行业亲密度
普通
运算法则
类型
2016年使用率%
2011年使用率%
变化程度%
产业亲和力
1回归S67%58%16%0.212聚类U57%52%8.70%0.053决策树/RulesS55%60%-7.30%0.214可视化Z49%38%27%0.445K-近邻法S46%0.326主成分分析U43%0.027统计Z43%48%-11%1.398随机森林S38%0.229时间序列/序列分析Z37%30%25%0.6910文本挖掘Z36%28%29.80%0.0111组合方法M34%28%18.90%-0.1712支持向量机S34%29%17.60%-0.2413BoostingM33%23%40%0.2414常规神经网络S24%27%-10.50%-0.3515最优化Z24%0.0716朴素贝叶斯S24%22%8.90%-0.0217BaggingM22%20%8.80%0.0218偏差检测Z20%16%19%1.6119神经网络-深度学习S19%-0.3520奇异值分解U16%0.2921关联规则Z15%29%-47%0.522图/连接/社会网络分析Z15%14%8%-0.0823因素分析U14%19%-23.80%0.1424贝叶斯网络S13%-0.125遗传算法Z8.80%9.30%-6%0.8326生存分析Z7.90%9.30%-14.90%-0.1527最大期望U6.60%-0.1928其他方法Z4.60%-0.0629Uplift modelingS3.10%4.80%-36.10%2.01表3: KD掘金2016调查:数据科学家使用的算法
结束
请发送电子邮件到holly0801@163.com提交和反馈。微信官方账号转载大数据文章请向原作者申请授权,否则任何版权纠纷都与大数据无关。
大数据
为您提供与大数据相关的最新技术和信息。
最近的精彩文章:
161224
161222
161216
161213
161208
161206
161205
161129
161126
161122
161119
161114
161112
161108
161107
161105
161028
161025
161023
161016
161014
161009
161001
更多精彩文章,请在公众号后台点击“历史文章”查看,谢谢。1.《nuggets 数据科学家最常用的十种算法(KDnuggets官方调查)》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《nuggets 数据科学家最常用的十种算法(KDnuggets官方调查)》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/shehui/1684738.html