正文|龚传杰@中兴大数据
如果采用MapReduce计算框架,Hive SQL将被翻译成两个MR作业,第一个MR作业执行后存储在HDFS系统中,下一个MR作业从HDFS读取数据执行。如果采用TEZ计算框架,将生成一个简单的DAG作业,可以大大减少读取磁盘所消耗的时间。
我们可以简单地在环境中操作,并比较以下两种执行引擎操作的结果:
如果采用MapReduce计算框架,Hive SQL会被翻译成4个MR作业,多次读写磁盘。所以启动多轮作业的成本略高,不仅占用资源,而且耗费大量时间。如果采用TEZ计算框架,会生成简洁的DAG作业,运行后操作人员不会退出,上一轮的操作人员在下一轮继续使用,会大大减少磁盘的IO操作,从而使计算速度更快。下图是两个计算框架的流程图:
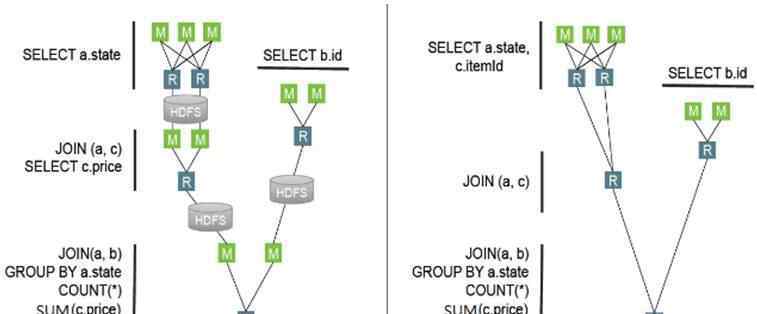
蜂巢磁流变仪与蜂巢TEZ仪计算流程的比较
我们在环境中的操作比较了以下两个执行引擎操作的结果:
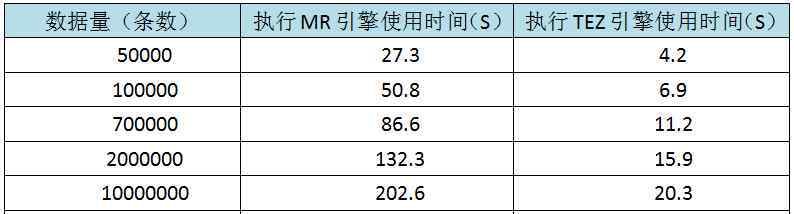
从上表可以看出,TEZ的执行效率比MR要高效得多,而TEZ的优势会随着数据量的不断增加而变得更加明显。当然,如果再次修改HQL语句,执行更复杂的语句,比如增加排序和平均运算,计算量会增加,更能看出TEZ的执行效率。
TEZ发展趋势
根据阿帕奇TEZ官方网站,以下新功能将在未来版本中添加:
任务抢占,即通过资源抢占的方式,可以给优先级较高的任务以优先权。
任务执行断点检查。通过在任务执行过程中记录断点,可以在任务失败时从断点恢复运行,从而避免任务重新计算。这个功能很难实现。就目前纱线的设计架构而言,完成的任务只能不重新计算,运行的任务需要重新计算。
容器再利用。这主要涉及到两个方面:一方面,同一个应用的多个任务可以复用一个Container,这是一个很重要的特性,社区里的讨论也很热闹,有兴趣的可以进入社区看看。另一方面,不同应用的Container复用,即不同应用的多个任务可以复用一个Container,这对于人们来说是不难期待的。
总结
TEZ执行引擎的出现可以帮助我们解决现有磁共振框架的一些缺点,如迭代计算和交互式计算。除了蜂巢组件之外,猪组件也将TEZ应用到它自己的优化中。此外,TEZ是基于纱,所以它可以与原磁共振共存,而不会相互冲突。在实际应用中,我们只需要在hadoop-env.sh文件中配置TEZ的环境变量,并在mapred-site.xml中将执行作业的架构设置为SHARE-TEZ,这样运行在SHARE上的作业就会以TEZ计算模式运行,方便原系统访问TEZ。当然,如果我们只想让Hive使用TEZ,不想修改整个系统,那么我们可以在Hive中单独修改,这也很简单,这样Hive就可以在MR和TEZ之间自由切换,而不影响原来的Hadoop MR任务,所以TEZ的耦合度很低,让我们使用起来很轻松方便。
随着互联网的飞速发展,算法得到了不断的优化和改进,目的只有一个:不被现实淘汰。
大数据时代的思考和洞察力
长按二维码注意
1.《tez 比MR至少快5倍的神器,竟然是它》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《tez 比MR至少快5倍的神器,竟然是它》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/shehui/837751.html










