背景:
在JD.COM家庭订单中心系统的业务中,无论是外部商家的订单生产还是内部上下游系统的依赖,订单查询的调用量都非常大,导致订单数据读多写少的情况。从JD.COM到家里的订单数据存储在Mysql中,但显然只通过数据库支持大量查询是不可取的。同时Mysql不够友好,无法支持一些复杂的查询,所以订单中心系统使用弹性搜索来承担订单查询的主要压力。
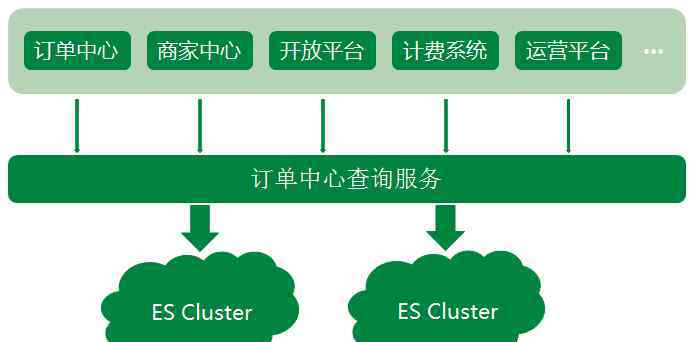
弹性搜索作为一个强大的分布式搜索引擎,支持近实时的数据存储和搜索,在JD.COM的家庭订单系统中发挥着巨大的作用。目前,订单中心的ES集群存储了10亿份文档,平均每天的查询量为5亿。近年来,随着JD.COM业务的快速发展,订单中心的专家系统架设方案也在不断发展。到目前为止,专家系统集群的建立是一种实时的互备份方案,保证了专家系统集群读写的稳定性。下面简单介绍一下这个过程和遇到的一些坑。
专家系统集群实施的演变:
1.初始阶段:
订单中心ES初期好到一张白纸,基本没有实施方案。许多配置保持集群的默认配置。整个集群部署在群的弹性云上,es集群的节点和机器部署混乱。同时,按照集群维度,一个ES集群会出现单点问题,这对于订单中心业务来说显然是不允许的。
2.集群隔离阶段:
与许多服务一样,es集群采用混合分发的方式。但由于订单中心es存储在线订单数据,偶尔会有大量系统资源被混合集群抢占,导致整个订单中心ES服务异常。
显然,对订单查询稳定性的任何影响都是不可容忍的。所以针对这种情况,首先对于订单中心es所在的弹性云,将系统资源抢占度高的集群节点移出,ES集群情况略有改善。但是随着集群数据的不断增加,弹性云配置已经不能满足ES集群的要求。为了实现完全的物理隔离,最终将订单中心的ES集群部署到高配置的物理机上,提高了ES集群的性能。
3.节点复制优化阶段:
ES的性能与硬件资源密切相关。当ES集群单独部署到物理机上时,集群内部的节点不会独占整个物理机的资源,同一台物理机上的节点在集群运行时仍然会存在资源抢占的问题。因此,在这种情况下,为了允许单个es节点使用最大的机器资源,每个ES节点被部署在单个物理机器上。
但是后来,问题又来了。单个节点出现瓶颈怎么办?应该怎么重新优化?ES查询的原理,当请求命中某个片段时,如果没有为查询指定片段类型(首选参数),请求将加载到片段号对应的每个节点上。群集的默认副本配置是一个主服务器和一对服务器。鉴于此,我们想到了扩展副本的方法,从默认的一主一对,扩展到一主两对,同时添加相应的物理机。

上图是订单中心ES集群实现示意图。整个实现方法使用VIP对外部请求进行负载均衡,第一层网关节点本质上是es中的客户端节点,相当于一个智能负载均衡器,起到分发请求的作用。第二层是数据节点,负责存储数据和执行数据相关操作。整个集群有一组主片和两组次片(一个主片和两个次片),从网关节点转发的请求在到达数据节点之前将通过轮询进行平衡。集群增加了一组副本,扩展了机器容量,增加了集群的吞吐量,从而提高了整个集群的查询性能。下图是订单中心各阶段ES集群性能示意图,直观展示了各阶段优化后ES集群性能的显著提升。

当然,切片的数量和切片的份数都不是尽可能的好。现阶段,我们对选择合适的切片数量进行了进一步的探索。片数可以理解为Mysql中的子数据库和子表,而目前订单中心的es查询主要分为单ID查询和分页查询两类。碎片数量越大,簇水平扩展的规模越大,基于碎片路由的单ID查询的吞吐量可以大大提高,但聚合分页查询的性能会降低。碎片数量越少,簇水平扩展的规模越小,单ID的查询性能也会下降,但对于分页查询,性能会有所提高。因此,如何平衡碎片数量与现有的查询服务,我们做了很多调整和压力测试,最终选择了聚类性能更好的碎片数量。
4.主从集群调整阶段:
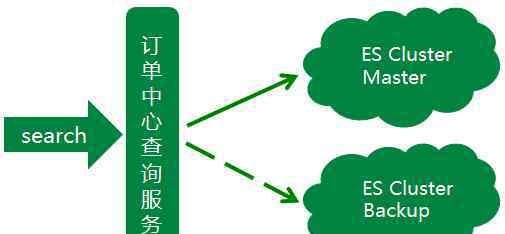
至此,订单中心的ES集群已经初具规模。但是由于订单中心业务的时效性要求较高,对ES查询的稳定性要求也较高。如果集群中有异常的节点,查询服务会受到影响,从而影响整个订单生产流程。显然,这种异常情况是致命的,所以为了应对这种情况,我们最初假设会增加一个备用集群,当主集群出现异常时,可以实时将查询流量降级到备用集群。
备用集群应该如何构建?主备数据如何同步?备用集群应该存储什么样的数据?考虑到ES集群暂时没有好的主备方案,为了更好的控制ES数据的写入,我们采用业务双写的方式构建主备集群。每次业务操作需要写ES数据时,同步写主集群数据,然后异步写备用集群数据。同时,由于ES查询流量大部分来自最近几天的订单,而且订单中心数据库中的数据有一套归档机制,所以在指定天数之前已经关闭的订单会被转移到历史订单库中。因此,在归档机制中增加了删除备份集群文档的逻辑,使得新建备份集群中存储的订单数据与订单中心在线数据库中的数据量一致。同时,ZK被用作查询服务中的流量控制开关,以确保查询流可以实时降级到备份集群。这里完成了订单中心的主从集群,ES查询服务的稳定性大大提高。
5.今天:实时相互备份双集群阶段:
在此期间,由于主集群的ES版本低于1.7,但是现在稳定版的ES已经迭代到6.x,新版本的ES不仅大大优化了性能,还提供了一些新的、易用的功能,所以我们对主集群进行了一次升级,直接从原来的1.7升级到6.x,集群升级的过程繁琐而漫长,不仅需要保证在线业务没有影响,还需要在没有感知的情况下顺利升级。同时,由于ES集群暂时不支持跨多个版本从1.7到6.x的数据迁移,所以需要通过重建索引来升级主集群,具体的升级过程在此不再赘述。
升级时不可避免会出现主集群不可用的情况,但订单中心的ES查询服务不允许出现这种情况。因此,在升级阶段,备用群集暂时充当主群集,以支持所有在线ES查询,并确保升级过程不会影响正常的在线服务。同时,针对在线业务,重新定义了两个聚类,并对在线查询流量进行了重新划分。
备用集群存储最近几天的热数据,数据规模比主集群小很多,大约是主集群文档的十分之一。集群数据量小。在相同的集群部署规模下,备用集群的性能优于主集群。但是在真实的在线场景中,大部分的在线查询流量也来自于热数据,所以用备用簇来承载这些热数据的查询,备用簇慢慢演变成热数据簇。前一个主集群存储全部数据,用于支持剩余的一小部分查询流量。这部分查询主要是需要搜索订单全额的特殊场景查询和订单中心系统内部查询等。,主集群慢慢演变成冷数据集群。
同时,备用集群增加了一键降级到主集群的功能。这两个集群同等重要,但每个集群都可以降级为另一个集群。双写策略也优化如下:假设有A B簇,正常同步模式下写主(A簇),异步模式下写备用(B簇)。集群a出现异常时,同步写入集群b(主),异步写入集群a(备用)。
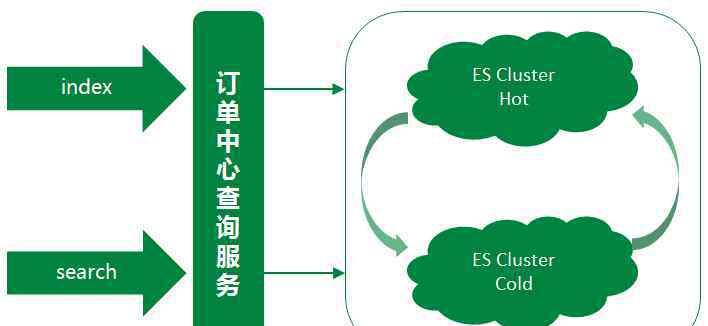
专家系统订单数据同步方案:
Mysql数据同步到ES,大致可以概括为两种方案:
方案一:听mysql的binlog,分析binlog,同步数据到ES集群
优点:业务与es数据耦合度低,ES数据的写入不需要业务逻辑上的关注
缺点:binglog模式只能使用ROW模式,并且引入了新的同步服务,增加了开发量和维护成本,同时也增加了es同步的风险
方案二:通过ES API直接将数据写入ES集群
优点:简洁明了,数据写入控制灵活
缺点:与业务耦合严重,强烈依赖业务系统的编写模式
考虑到订单系统中ES服务的业务特殊性,订单数据的实时性较高。显然,监控binlog的方式相当于异步同步,可能会导致更大的延迟。方案1与方案2基本相似,但引入了新系统,维护成本也增加了。因此,订单中心ES采用直接通过ES API写入订单数据的方式,简单灵活,能够很好的满足订单中心数据同步到ES的需求。
由于ES订单数据同步是在业务中写入的,如果在创建或更新单据时出现异常,重试会影响正常业务操作的响应时间。所以每个业务操作只更新es一次。如果出现错误或异常,向数据库中插入一个补救任务,一个工作任务将实时扫描数据,并根据数据库订单数据再次更新ES数据。通过这种补偿机制,可以保证ES数据和数据库订单数据的最终一致性。
遇到一些坑:
1.对实时性要求高的查询转到数据库
如果你知道ES的写入机制,你可能知道新添加的文档会被收集到索引缓冲区,然后写入文件系统缓存,在那里它们可以像其他文件一样被索引。但是默认情况下,从索引缓冲区到文件系统缓存的文档(即刷新操作)是每秒自动按片刷新的,所以这就是为什么我们说es是接近实时搜索而不是实时的原因:文档的变化对于搜索来说不是立即可见的,而是会在一秒钟内变得可见。目前订单系统ES采用默认刷新配置,所以对于那些实时订单数据较高的业务,直接使用数据库查询来保证数据的准确性。

2.避免深度分页查询
ES集群的分页查询支持from和size参数。查询时,每个片段必须构造一个长度为from+size的优先级队列,然后将其发送回网关节点,网关节点再对这些优先级队列进行排序,找到大小正确的文档。假设在一个有6个主片的索引中,from为10000,size为10,每个片必须产生10010个结果,在网关节点中合并60060个结果,最终找到10个满足要求的文档。可以看出,当from足够大时,即使OOM不发生,也会影响CPU和带宽,从而影响整个集群的性能。所以要避免深度分页查询,尽量不要使用。
3.字段数据和文档值
字段数据:在线查询偶尔超时。通过调试查询语句,发现与排序有关。在es 1.x版本中,排序使用fielddata结构,占用jvm堆内存,jvm内存有限,所以会为fielddata cache设置一个阈值。如果空不足,则使用LRU算法删除字段数据,同时加载新的字段数据缓存,这将消耗系统资源并花费大量时间。因此,这个查询的响应时间飙升,甚至影响了整个集群的性能。为了解决这个问题,采用了doc值。
DOCVALUES: DOCVALUES是一种列数据存储结构,类似于fieldata,但是存储位置在Lucene文件中,也就是不占用JVM堆。随着ES版本的迭代,doc值比fielddata更稳定,doc值是从2开始的默认设置。x.
总结:
架构的快速迭代源于业务的快速发展,也正是因为近年来家庭业务的快速发展,订单中心的架构不断优化升级。但是架构方案不是最好的,只有最适合的。相信几年后,订单中心的架构会是另一张脸,但订单中心系统永远追求更大的吞吐量,更好的性能,更强的稳定性。
1.《京东订单查询 京东到家订单订单查询服务演进》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《京东订单查询 京东到家订单订单查询服务演进》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/caijing/974101.html