
这是一个收集程序,无需登录即可根据企业名称搜索和抓取企业页面数据
注意:这是一个比较简单的爬虫,基本上只使用代理,不使用其他反爬技术。但是由于爬取的数据量较大,适合刷分析技能的熟练度,高手不宜入
Python版本:python2.7
编码工具:pycharm
数据存储:mysql
爬行动物结构:宽爬行动物
爬虫思维:

先获取需要采集信息的公司:从数据库中获取获取字段:etid,etname将获取的数据存储的状态表中从状态表中获取数据,并更新状态表拼接初始URL:将etname和初始url进行拼接,获得初始网址将初始url放到一个列表中,获取HTML的时候如何出错,将出错的url放到另一个列表中,进行循环获取请求解析初始一级页面:验证查询的公司是否正确(??)获取二级页面url将二级url放到一个列表中,获取HTML的时候如何出错,将出错的url放到另一个列表中,进行循环获取请求解析二级页面:获取的信息待定将公司的信息存储到数据库中:建表存储信息身为老司机,还是得分享些干货精品学习资料的,推荐下小编创建的Python学习交流群556370268,送给每一位小伙伴,这里是小白聚集地,每天还会直播和大家交流分享经验哦,欢迎初学和进阶中的小伙伴。
表格已创建:

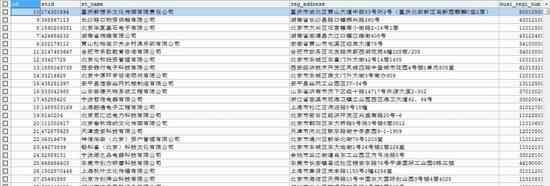
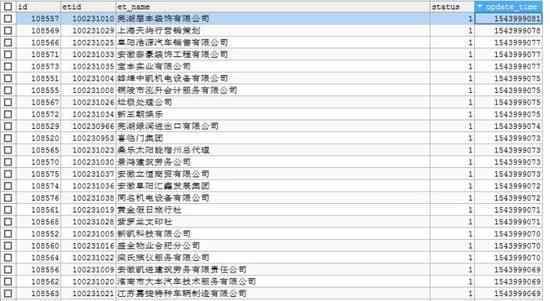
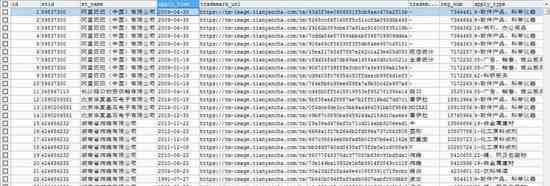
企业主要信息: et_host_info工商信息: et_busi_info分支机构信息: et_branch_office软件著作权信息: et_container_copyright_info网站备案信息: et_conrainer_icp_info对外投资信息: et_foreign_investment_info融资信息: et_rongzi_info股东信息: et_stareholder_info商标信息: et_trademark_info微信公众号信息:et_wechat_list_info状态表: et_name_status
看看一些结果:
1.《天眼查企业信息 这是一个爬虫—爬取天眼查网站的企业信息》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《天眼查企业信息 这是一个爬虫—爬取天眼查网站的企业信息》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1174275.html




