
本文转自微信官方账号数据森林
前言
搬到Python半年,接触爬虫两个月,看了10本相关的书,完成了这项工作,这是对我过去学习和实践的回顾。也希望能和更多的python和爬虫爱好者交流成长。
选择这个题目,首先是把豆瓣作为爬虫引入,对各种大牛的深入分析变得完善;另一方面,随着中国电影业的发展,我们需要将视角转向国际市场,通过数据分析找出外国人感兴趣的电影。
数据抓取
网页分析
IMDBtop250主页
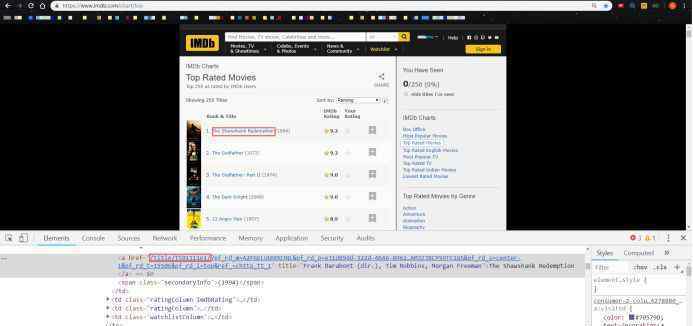
IMDB电影详细信息页面(1)
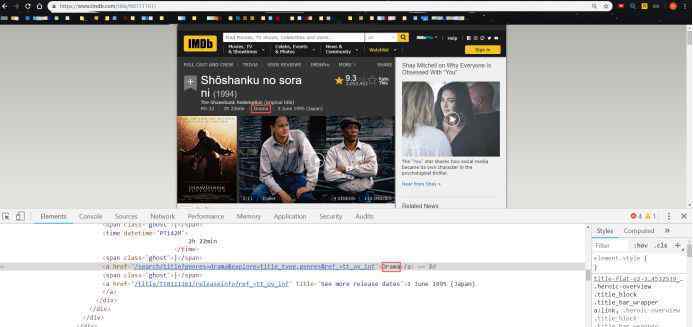
IMDB电影详细信息页面(2)
基于上面的网页结构,我们发现我们只需要得到每部电影的详细页面代码(唯一),实现详细页面(1)(2)导出国家&:类型,分数&:获取人数信息。简单易懂,抓取思维导图如下:

爬虫代码
01
IMDB top250主页
#导入库-导入库-导入库
fromurllib importrequest
fromchardet importdetect
来自bs4导入美化组
进口熊猫aspd
importtime
importrandom
#获取网页的源代码并生成soup对象。
定义汤(url):
withrequest.urlopen(url) asfp:
byt = fp.read()
det =检测(字节)
time.sleep(random.randrange( 1,5))
return美化组(byt.decode(det[ 'encoding']),' lxml ')
#解析数据-。
定义数据(汤):
#获得评分
ol = soup.find( 'tbody ',attrs = { 'class': 'lister-list'})
score_info = ol.find_all( 'td ',attrs={ 'class': 'imdbRating'})
film_scores = [k.text.replace( 'n ',' ')fork inscore_info]
#获取分数、电影名称、导演和演员、发行年份和详细信息链接
film_info = ol.find_all( 'td ',attrs={ 'class': 'titleColumn'})
film _ name =[k . find(' a ')。文本叉infilm_info]
film_actors = [k.find( 'a ')。attrs[ 'title'] fork infilm_info]
film_years = [k.find( 'span ')。text[ 1: 5] fork infilm_info]
next_nurl = [url2 + k.find( 'a ')。attrs[' href '][0:17]fork in film _ info]
数据=pd。data frame({ ' name ':film _ name,' year':film_years,' score':film_scores,' actors':film_actors,' newurl':next_nurl})
returndata
02
IMDB top250电影详细信息页面
#获取详细的页面数据-。
定义下一个网址(详细信息,详细信息1):
#得到电影国家
detail_list = detail.find( 'div ',attrs={ 'id':'titleDetails'})。find_all( 'div ',attrs={ 'class':'txt-block'})
detail_str = [k.text.replace( 'n ',' ')fork indetail_list]
detail _ str =[k fork Inde tail _ str ifk . find(':')& gt;= 0]
detail _ dict = { k . split(':')[0]:k . split(':')[1]fork Inde tail _ str }
country = detail_dict[ 'Country']
#获取电影类型
detail_list1 = detail.find( 'div ',attrs = { ' class ':' title _ wrapper ' })。find_all( 'div ',attr = { ' class ':' subtext ' })
detail_str1 = [k.find( 'a ')。indetail_list1]中的文本分叉
movie_type=pd。数据帧({“类型”:detail_str1})
#按组获取电影的详细分数和数量
div_list = detail1.find_all( 'td ',attrs= { 'align': 'center'})
value = [k.find( 'div ',attrs = { ' class ':' big cell ' }). text . strip()fork indiv _ list]
num = [k.find( 'div ',attrs = { ' class ':' small cell ' }). text . strip()fork indiv _ list]
分数=pd。DataFrame({ 'value':value,' num':num})
返回国家,电影类型,分数
数据显示
最后,我们获得了以下数据,并将其存储起来供后续分析使用:
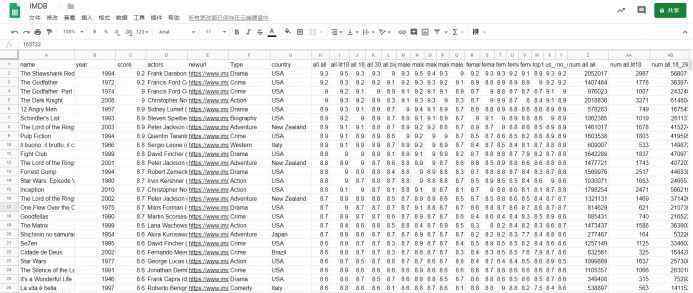
数据分析
01
电影类型比较
首先,让我们看看每种类型的电影所占的比例:
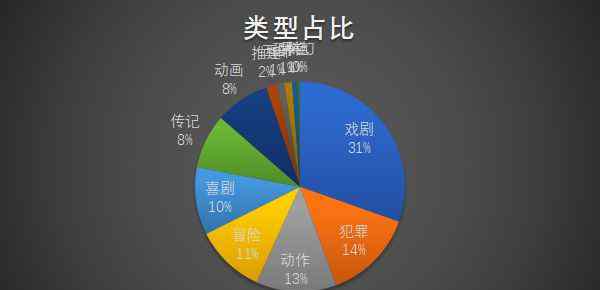
前250名电影的前三种类型是喜剧、犯罪和动作片。
激动的情绪和轻松的剧情可以给粉丝带来难忘的观影体验。
我们来看看各种类型电影的评分对比:
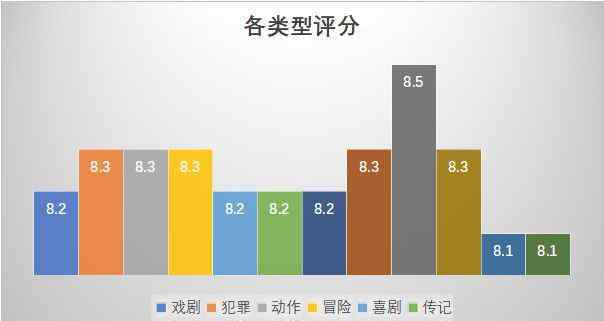
从类型来看,西方电影之所以骑在尘埃上,可能与观众少、狂放的粉丝分数高有关。其次,犯罪、动作、冒险、推理和恐怖题材也容易得分较高
02
年份比较
首先,我们来看看250强电影的年份:

在前250部电影中,1957年、1995年和2014年的电影较多,但1975年后,上榜电影数量明显增加,这可能与电影行业日益成熟有关。
至于1995年,熟悉电影的朋友可能都知道,1995年是世界电影百年,无数电影天才在这一年里诞生了他们的伟大作品。我们熟悉《肖申克的救赎》《阿甘正传》《低俗小说》《四婚礼一葬礼》《七宗罪》《狮子王》等等
同时,我们来看看各个年代电影的评价分数:
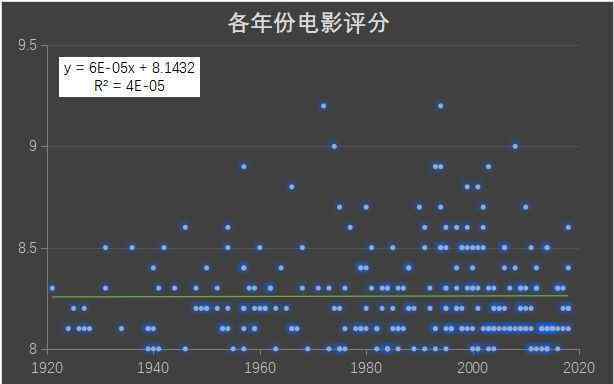
对比电影时代评分,没有明显的上升或下降趋势,说明电影艺术不会随着时间而失去自身的价值。对于电影来说,技术不是第一位的,情感共鸣因素占的权重更大;哪部电影最好看?答案在于我们每个人。
03
国家比较
让我们来看看来自各个国家的电影在250部电影中所占的比例:
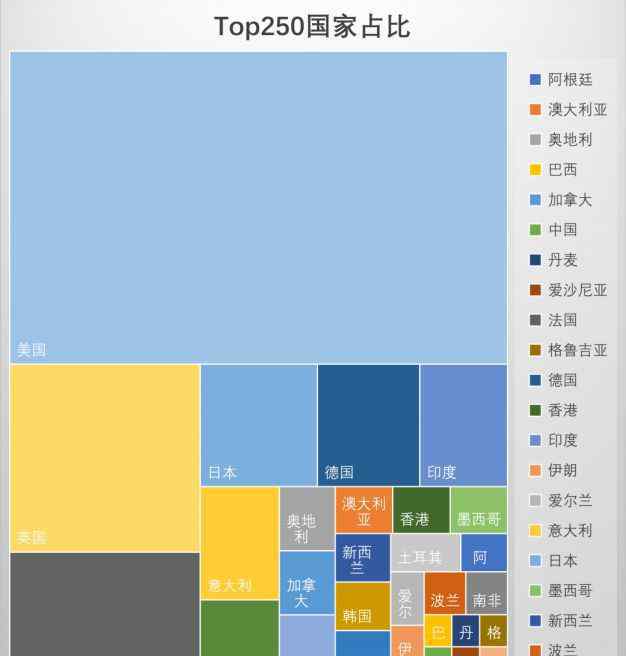
这个数字很有意思。有点像诺贝尔奖。美国电影占据半个国家,其他国家瓜分剩下的蛋糕。排名靠前的是英国、法国、日本和德国。在中国,唯一上榜的电影是《花样年华》。
如果是由于西方主流价值观,同样是东方文化代表的邻国日本有16部电影上榜,说明西方价值观不能成为中国电影缺失的主要原因。近年来,国内出现了很多高质量的作品,如《大鱼海棠》和新上映的《流浪地球》,但在国际市场的反响依然平平。我相信电影有共同语言,真的有普世价值这种东西。如何打造一个国际化的电影产业,给全世界的人讲故事,是中国电影人接下来需要探索的话题。
04
导演比较
让我们看看最常出现在250强名单中的导演:
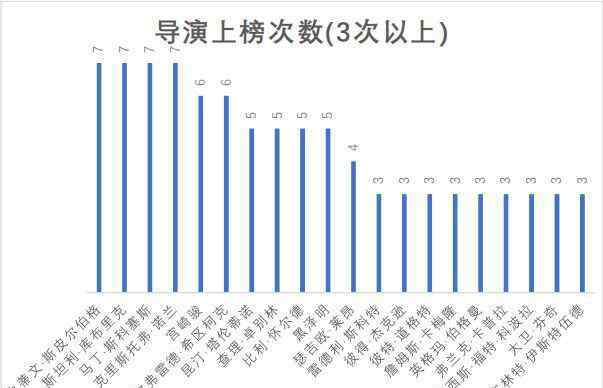
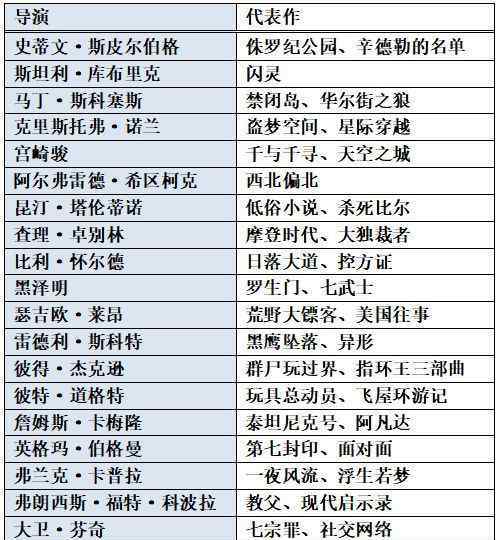
我们来看看名单上有哪些作者。鉴于可能大家都不太熟悉外国董事的名字,这里做一个董事代表对照表。值得注意的是,雷德利·斯科特(Redley Scott)、詹姆斯·卡梅隆(James Cameron)和大卫·芬奇(David Finch)分别执导了《异形1》、《异形2》和《异形3》,其中一部《异形》有三位导演上榜,可见其系列影响力。没看过的小伙伴强烈建议去看一看,虽然味道可能比较重。
05
人口比较
首先,我们来看看不同人的分数:
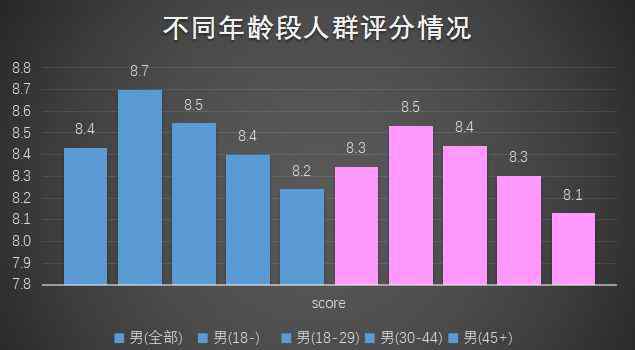
从性别维度来说,男性比女性更容易给出高分。另一方面,从年龄方面来说,无论男女,未成年人最容易给高分。随着年龄的增长,分数越来越有吸引力,45岁以上的给出的分数最低。一颗坚硬的心,过了海就很难被感动吗?又或许一部电影只有见多识广才能得到公正客观的评价?也许可以研究一下这个问题,比如《电影节评委年龄组科学分配方法》。
但是,了解评分情况,还需要了解各种人群的比例:
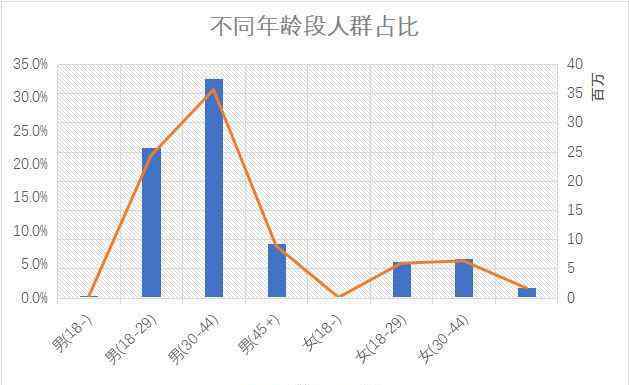
“老叔叔”“老阿姨”虽然分数低,但也没必要太担心这些人。因为数据告诉我们,要满足30-44岁和18-29岁年龄段的中青年男性的口味,电影口碑肯定不差。近年来,《狼勇士》《红海行动》等战争动作片口碑不错,评分机制我们也略知一二。
06
类型、年龄与分数的关系
首先,我们用热图来看不同人群对不同类型电影的评分:
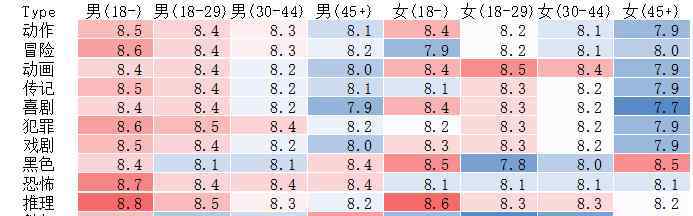
不同年龄段对电影类型有不同的偏好。例如,未成年男女对推理和西方电影表现出浓厚的兴趣,而超过45名男女分别喜欢科幻和黑色电影。
分数的高低也需要结合比例综合分析:
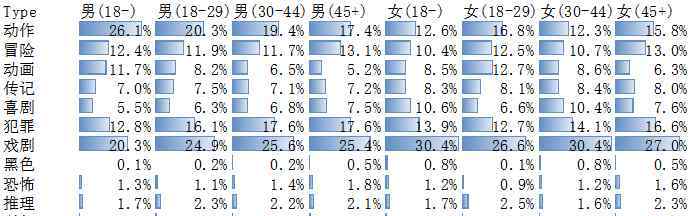
这一次,我们将数据粒度细化到各个年龄段,并结合各个年龄段的分数。下面我们给大家推荐250强榜单中各个年龄段的电影。
电影推荐
未成年男性(

18-29岁的男性

30-44岁的男性

45岁以上男性

未成年女性(

18-29岁的女性

30-44岁的女性

45岁以上女性

以上电影根据IMDBtop250数据推荐。如有不符,请在此表示歉意。毕竟美国人的喜好和中国不一样。
最后,我以《三体》中的一首诗结束:
我看到了我的爱
我飞到她身边
我给了她一份礼物
那只是凝固时间的一小部分
时间里有美丽的条纹
感觉像浅海里的泥一样柔软
她把时间涂在全身
然后拉着我飞向存在的边缘
这是一次精神飞行
我们眼中的星星就像幽灵
我们就像星星眼中的幽灵
微信官方账号后台回复“Movie”,可以得到这篇文章的源代码。
1.《源代码影评 豆瓣已玩烂,这次我们爬取了IMDB电影Top250后发现...》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《源代码影评 豆瓣已玩烂,这次我们爬取了IMDB电影Top250后发现...》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/986516.html




