神经网络的注意机制已经引起了广泛的关注。在本文中,我将尝试寻找不同机制的共同点和用例,并解释两种软视觉注意的原理和实现。
什么是关注?
一般来说,神经网络的注意机制是一个能聚焦于其输入(或特征)并能选择特定输入的神经网络。我们设置输入为x∈Rd,特征向量为z∈Rk,a∈[0,1]k为注意向量,fφ(x)为注意网络。一般来说,实施注意事项如下:
a=fφ(x)
或者za=a⊙z
在上式[1]中,⊙表示元素乘法的运算。这里介绍一下软注意和硬注意的概念。前者是指相乘时值的掩码是从0到1,后者是指强制将值的掩码分为0或1,即a∑{ 0,1} k,对于后者,我们可以用心伪装指数特征向量:za=z[a]。这增加了它的尺寸。
为了理解注意力的重要性,我们需要考虑神经网络的本质——它是一个函数逼近器。根据其架构,它可以近似不同类型的功能。神经网络一般用在链式矩阵乘法和对应元素的框架中,输入或特征向量只在加法时相互作用。
注意机制可用于计算可用于特征倍增的掩模。这个操作极大地扩展了神经网络逼近的函数空,使得一个新的用例成为可能。
视觉注意力
注意力可以应用于各种类型的输入,而不管它们的形状如何。在像图像这样的矩阵值输入的情况下,我们引入了视觉注意的概念。I∈RH*W和g∈Rh*w定义为惊鸿一瞥,即对图像应用注意机制。
用力注意
硬注意图像已经应用了很长时间,例如图像裁剪。它的概念很简单,只需要做索引。硬注意可以在Python和TensorFlow中实现为:
以上形式的问题是不可微。如果你想知道模型的参数,你必须借助分数函数估计器。
软注意
在注意力的最简单变体中,软注意力与公式[1]中实现的向量值特征没有什么不同。《展示、注意和讲述:视觉注意下的神经图像字幕生成》一文记录了它的早期应用。
论文地址:
https://arxiv.org/abs/1502.03044
我将这种机制应用到最近一篇关于物体跟踪的RNN注意力的论文中,这篇论文是关于HART(分层注意力重复跟踪)的。
论文地址:
https://arxiv.org/abs/1706.09262
这里举个例子,左边是输入图像,右边是关注,显示的是绿色主图像上的方框。

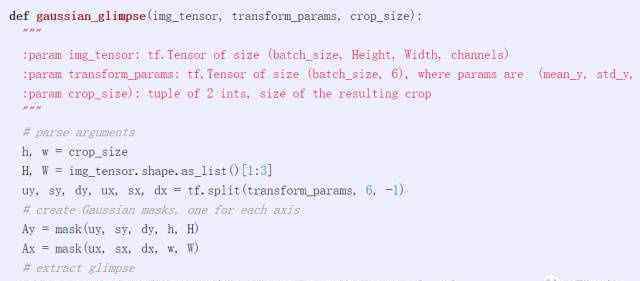
以下代码字符串允许您在TensorFlow中为小批量样本创建上述矩阵值掩码。如果要创建Ay,可以称之为Ay = gaussian_mask(u,s,d,H,H),其中u,s,d分别表示μ,σ,d,以像素为单位用这种方式指定。

我们还可以编写一个函数,直接从图像中提取图像:
空间转换器
空间转换器(STN)允许更一般的转换,并可以区分图像裁剪。图像裁剪也是可能的用例之一,由网格生成器和采样器两部分组成。网格生成器指定采样点的网格,采样器就是一个样本。TensorFlow在DeepMind最新的神经网络库Sonnet中实现非常简单。

高斯注意力与空间转换器
高斯注意和空间转换器行为相似,如何判断选择哪种实现方式?以下是一些细微的区别:
高斯注意是一种超参数裁剪机制,需要6个参数但只有4个自由度(y,x,高,宽)。STN只需要四个参数。
我还没有运行任何测试,但是STN应该会更快。它依赖于采样点的线性插值,而高斯注意需要进行两次矩阵乘法。
高斯注意力应该更容易训练。这是因为,结果是,一瞥中的每个像素可以是源图像中相对较大的像素块的凸组合,这使得更容易找到错误。另一方面,STN依赖于线性插值,每个采样点的梯度不仅仅在最近的两个像素处为零。
结论
注意机制扩展了神经网络的功能,可以逼近更复杂的函数。或者更直观的说,它可以专注于输入的特定部分,提高自然语言基准测试的性能,并带来新的功能,如图像字幕、记忆网络中的地址、神经程序等。
在我看来,注意力最重要的应用案例还没有被发现。比如我们知道视频中的物体是一致连贯的,不会一帧一帧的突然消失。注意力机制可以用来表达这种一致性。至于它的后续发展,我会留意的。
1.《attention机制 Attention!神经网络中的注意机制到底是什么?》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《attention机制 Attention!神经网络中的注意机制到底是什么?》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/caijing/796294.html