计量服务中心综合安排,如有转载请联系
一.导言
在(0,1)区间内均匀分布的随机变量的样本值称为“均匀分布的随机数”,简称“随机数”。
有了均匀分布的随机数,几乎可以生成任何随机数。而计算机生成的所谓“随机数”,因为还是递归公式生成的,所以只是“伪随机数”。尽管如此,这些“伪随机数”能够通过独立性和均匀分布的统计检验,因此可以作为“随机数”使用。
“随机数”的初始值称为“种子”(sed)。为了使随机样本具有可重复性,并保证采样后或由他人获得相同的样本,通常需要在生成随机数时设置“种子”。如果没有给出“种子”,Stata会根据“计算机时钟”自动选择“种子”,这样每次采样的样本会有所不同,模拟结果无法完全复制。
二.操作应用
最基本最常用的随机数序列是均匀分布的随机数序列。
生成均匀分布随机数序列的基本命令如下:
generate newar=runiform()
其中newar是一个新变量的名字,uniform()是一个生成在区间[0.1]内均匀分布的随机数的函数。需要注意的是runiform中没有参数,但是括号是必须的。
如果我们想在其他区间生成一个均匀分布,我们可以简单地对其进行变形。例如,要生成在区间[a,b]内均匀分布的随机数,对应的函数是:
a+(b-a)* run form
产生标准正态分布随机数的作用是:
invnorm(uniform())
函数:m+s * invnorm(run form())可以用来生成均值为m、标准差为s的正态随机数。
三.种子数量
命令是:
设定种子#
例如
设定种子123456789
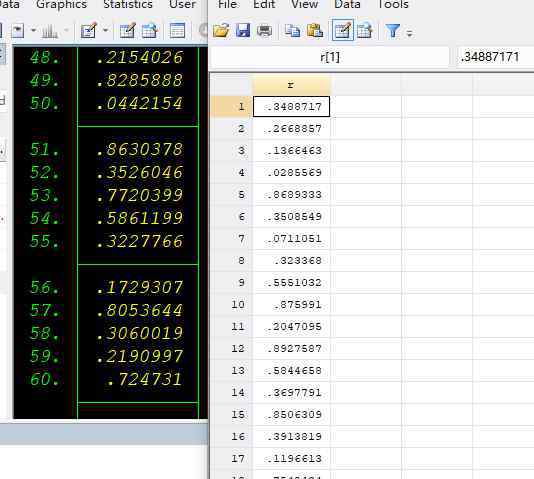
设置obs 100
gene r=runiform()
意味着种子数设为123456789,观察值设为100,生成[0.1]处的随机数。
1.《数的产生 一文读懂随机数的生成》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《数的产生 一文读懂随机数的生成》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1044017.html

 影猫 http://www.mvcat.com/
影猫 http://www.mvcat.com/