12月11日@温哥华
报名截止时间:午夜12点6分
正文来了!

本文授权转载自微信官方账号:清华四科
刘知远,清华大学计算机系副教授、博士生导师。主要研究方向为表示学习、知识图谱和社会计算。陈慧敏,清华大学计算机科学与技术系博士生,主要研究方向为情感分析、文本生成、谣言分析。互联网的深度普及加速了“信息时代”的到来。网络中的每个人都可以以极低甚至“零”的成本创造信息,同时每个人都可以成为信息传播路径上的一个节点。这种获取、创造和传播信息的便利给社会进步和人类发展带来了好处。但是,凡事总有两面性,互联网也给人类社会带来了巨大的挑战——网络中的信息良莠不齐,虚假信息无处不在。
网络上的虚假信息有什么影响?
美国皮尤研究中心(Pew Research Center)调查了2018年美国人接触的新闻来源,发现约三分之二的美国人从社交媒体平台获取信息,但57%的人认为他们获取的新闻不准确[1]。这表明网络上的虚假信息已经广泛渗透到网民的生活中,并得到网民的广泛认可。
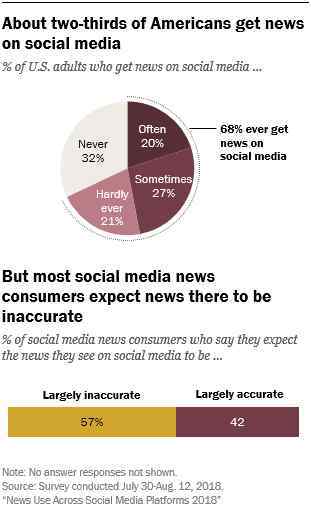
皮尤研究中心2018年美国人接触的新闻来源调查分析[1]
据统计,2016年美国总统大选期间,报道选举事件的前20名虚假新闻在Facebook上获得871.1万股赞和评论,超过前20名真实新闻获得的736.7万股赞和评论,严重误导了选举舆论。同年,“后真实”一词也被牛津词典选为年度词汇,反映了“雄辩胜于事实”的网络环境[3]。2011年,日本地震引发的核泄漏污染了海盐,中国网络媒体出现了大量“中国盐资源也被污染”等虚假信息,导致人们疯狂抢盐,引发社会恐慌。
可见,互联网上虚假信息的大规模传播给社会和个人的发展带来了严重的危害。因此,在当今互联网时代,识别和检测互联网上的虚假信息尤为重要。
网上的虚假信息有哪些类型?
根据网络虚假信息的内容,可以分为两类:基于观点的虚假信息和基于事实的虚假信息。
基于观点的虚假信息没有绝对的事实标准,一般指发表虚假的个人观点,如评论网站上的虚假评论。
基于事实的虚假信息有绝对的事实标准,一般是为了迷惑公众而伪造事实,如假新闻、Wiki骗局等。
这两种类型是我们需要关注和测试的对象。以一个当时广为流传的维基百科骗局为例。2008年7月,一名17岁的学生恶作剧地在维基百科的条目“coati(南美浣熊)”中添加了一个假名,称“coatis也被称为‘巴西土豚’”。之后这种虚假信息在维基百科上保留了六年,被数百家网站、报纸甚至一些大学出版的书籍传播。

维基词条“coati”的骗局
网络上的虚假信息有哪些特点?
目前,国外已经做了一些开创性的工作来定量分析互联网上虚假信息的统计特征。研究发现,基于视点的虚假信息在文本、情感和时间三个方面具有明显的特征:
(1)文字特征。基于观点的虚假信息往往具有很强的文本相似性,并伴随着明显的语言特征。如果用第一人称来表达个人经历,就要用感情强烈的词和修饰副词,比如“非常”“非常”。
(2)情感特征。虚假评论的情感存在强烈的“两极分化”现象,“满分评论”和“最低分评论”占据主导地位[4]。
(3)时间特性。虚假评论一般比真实评论更“突然”,虚假信息提供者发起连续评论的时间间隔更短[5]。

基于事实的虚假信息在语言、评论和沟通方式上具有突出的特点:
(1)语言特点。基于事实的虚假信息,为了增强关注度和吸引流量,往往在标题中提供大量信息,并表现出强烈的无关性特征,即所谓的“标题方”。

“标题党”新闻
(2)评论的特点。虚假信息因其新颖性会在评论中引起更多的“惊讶”、“厌恶”等情绪[6]。

在虚假信息的评论中,“惊讶”和“厌恶”的情绪激增(红色是虚假信息)[6]
(3)沟通特点。虚假信息呈现出一种“病毒式”传播模式,往往比真实信息更远、更快、更深、更广[7]。

虚假信息比真实信息传播得更远、更快、更深、更广[7]
为什么网上的虚假信息可以欺骗大众?
有研究定量分析了为什么网络上的虚假信息可以欺骗公众,主要从虚假信息本身、网民个人和网民群体三个角度进行分析。
好奇的心态。如前所述,互联网上的虚假信息本身在语言上具有鲜明的特点。为了吸引注意力,他们往往会提供更多新颖的观点,展示更多独特的信息[8],而公众则会因为“好奇”心态而更倾向于传播这类信息。

虚假信息(红色)与真实信息(绿色)在信息唯一性(IU)和差异性(KL)上的比较[8]
歧视性差。由于知识水平参差不齐,许多互联网用户往往没有足够的能力来区分信息的真实性。斯坦福大学的库马尔团队曾经做过一个实验。他们雇佣了亚马逊机械土耳其人的注释者来区分320对真假文章,每对都展示给五个不同的注释者。实验表明,人们成功识别虚假文章的概率只有66%(略高于50%的随机猜测)。再者,他们对容易识别和难以识别的虚假信息进行统计比较,发现虚假信息的长度越长,链接和标签越多,越容易被识别为真实信息[9]。可以想象,如果虚假信息在长度、链接、标记等方面刻意模仿真实信息。,那就更难分辨了!
回音室效应。互联网形成了大大小小的网民网络社区,回音室效应会进一步诱导公众被虚假信息所欺骗。回音室效应是指,在一个相对封闭的环境中,类似观点的声音以夸张或其他扭曲的形式反复出现,使得这个相对封闭的环境中的大多数人认为这些扭曲的故事都是事实。如今在线社交媒体的个性化推荐算法不断完善,不断向用户推荐内容和兴趣相近的人,进一步放大了互联网社区的回音室效应。在回音室效应下,网民倾向于坚守与自己喜好和观点一致的社交圈,切断来自其他社交圈的信息输入。
下图反映了推特上关于#牛肉班(印度禁止吃牛肉)[9]的转发网络,红蓝点代表观点相反的网友。可以看出,与组内频繁的互动相比,两组之间的信息交流很少。

推特上转发网络关于#牛肉班的话题[9]
如何自动检测虚假信息?
基于以上分析,我们可以发现,稍加包装,虚假信息就很容易“蒙混过关”,在互联网上大规模传播。面对复杂的互联网信息,人工专家检测费时费力,与呈指数级增长的信息相比,这是一项不可能完成的任务。
好消息是,互联网技术与计算机和人工智能技术齐头并进。先进的人工智能技术为我们提供了自动检测虚假信息的可能性。目前,国外许多研究者正在探索如何自动检测虚假信息,并取得了一定的进展。
对特色工程的思考。一些研究者采用了特征提取的思想。根据总结出的虚假信息特征,如前面提到的语言特征和交流特征,他们使用支持向量机、随机森林等机器学习方法将信息分类为真或假[10,11,12],如下图所示。这种基于特征提取的方法可以充分利用专家总结的经验和知识,但美中不足的是需要手动提取特征,无法从大规模互联网数据中自动挖掘特征。但网络虚假信息类似于垃圾邮件或广告,其技术、手段和形式都在不断更新。很难与时俱进,及时应对新的虚假信息形式。

基于特征提取的传统方法
对深度学习的思考。近年来,深度学习引发了全球人工智能发展的浪潮。深度学习的核心思想之一是采用分布式表示方案从大规模文本中自动学习和提取语义特征。分布式表示学习是指通过大规模数据集自动学习信息的低维特征向量表示。这些向量反映了我们所关心的对象(如单词、句子、文档、用户、文章等)的位置信息。)在低维向量空中,它们之间的相对距离和位置反映了语义相关性。
下图是从大规模文本语料库中自动学习的一些单词的二维向量表示[13]。可见深度学习技术可以自动学习单词的语义相似度,即国名会聚在一起,而城市名会聚在一起。同时,该技术还可以找到“中国”—“北京”、“日本”—“东京”的语义关系,即可以自动挖掘出“国家首都”的隐含语义关系。

分布式表示学习[13]
分布式表示学习可以很好地解决社交计算中对象间的语义计算问题,将文本、用户和对象映射到统一的低维向量语义空。这样,专家就不再需要总结自己的特征,而是从海量的互联网数据中自动挖掘特征,进而预测信息的真假[14,15,16]。

基于分布式表示的学习方法[13]
下面是利用深度学习技术自动从原文和评论文本中学习特征,自动检测社交媒体平台早期谣言的典型案例[17]。如上所述,社交媒体平台中的评论文本包含丰富的反馈信息,以识别原始发布信息的真实性。如果能够充分挖掘评论文本信息,可以大大提高信息检测的及时性和准确性,实现谣言的早期自动检测。

使用“可信检测点”早期检测谣言的示例[18]
如上图所示,我们画出了一个谣言转贴序列和一条随时间变化的预测概率曲线。因为转帖中对原始信息有很多质疑和反驳,不需要看全部评论就可以做出可信的预测。基于这一观察,我们引入了“可信检测点”的概念,并提出了一个谣言早期检测模型。通过深度神经网络,不断整合序列前评论的表达方式,自动学习如何确定每个转发序列的“可信检测点”,从而保证该时间点预测结果的可靠性,使得事后不会出现结果反转。基于深度学习方法,在新浪微博真实数据集上的实验结果表明,与传统模型相比,该谣言早期检测模型的预测时间缩短了85%,检测准确率更高。
总结与展望
在“后真实时代”,互联网上虚假信息的定量分析和自动检测是一个亟待解决的问题。基于深度学习的自动检测方法将是未来的主流趋势,但该方法仍然存在准确率低、可解释性和鲁棒性差的问题。这是一个高度跨学科的方向,需要计算机科学、语言学、社会学、心理学、法学甚至脑科学等各个角度的综合研究,才能实现对互联网上虚假信息的“围剿”。
从技术角度来说,现有的知识库,如wiki数据、知网等,包含了丰富的群体智慧和人类知识。如果能将这些结构化知识与深度学习技术相结合,引入虚假信息检测模型,有望显著提高信息检测的准确率。如何提取复杂的网络信息并将其与知识库中的信息进行匹配将是挑战和难点之一,也是一个值得今后进一步探索的问题。
此外,目前对网络虚假信息的定量研究大多基于英文数据,而中文相关研究较少,这与中文网络世界获取相关数据困难以及缺乏标注数据有关。因此,如何在中文互联网上建立一个相对大规模的虚假信息语料库,如何在少量中文语料库的基础上建立一个有效的虚假信息自动挖掘和检测能力是值得研究的。
本文结合以往的研究工作,对互联网上虚假信息的影响、特点、成因、检测等进行了简要的总结和梳理,不涉及太多技术细节,旨在起到科普介绍的作用,希望能有利于大家对这个方向的初步认识和探索。限于作者水平,难免会有错误,欢迎批评指正。
参考数据
[1] Elisa Shearer,Katerina Eva Matsa。2018年跨社交媒体平台的新闻使用。皮尤研究中心,2018
[2]克雷格·西尔弗曼。这一分析显示了脸谱网上的虚假选举新闻如何胜过真实新闻。Buzzfeed新闻。2016.
[3]“2016年度词汇是……”牛津词典。2016.
[4]库马尔、斯里扬和尼尔·沙阿。"网络和社交媒体上的虚假信息:一项调查."arXiv预印本arXiv:1804.08559 (2018)。
[5] Shah,Neil,等,“边缘中心:边缘属性网络中的异常检测”2016 IEEE第16届国际数据挖掘研讨会会议(ICDMW)。IEEE,2016。
[6] Hooi,Bryan,等,“鸟巢:用于收视率的贝叶斯推断-欺诈检测。”2016 SIAM国际数据挖掘会议录。工业与应用数学学会,2016。
[7]沃索利、索罗什、黛比·罗伊和西南·阿拉尔。"真假消息在网上的传播."理科359.6380 (2018): 1146-1151。
[8]库马尔、斯利扬、罗伯特·韦斯特和朱尔·莱斯科维奇。"网络虚假信息:维基百科骗局的影响、特征和检测."第25届万维网国际会议录。国际万维网会议指导委员会,2016年。
[9] Garimella,Kiran等,“平衡对立观点以减少争议。”arXiv预印本arXiv:1611.00172 (2016): 4。
[10]库马尔、斯里扬、罗伯特·韦斯特和朱尔·莱斯科维奇。"网络虚假信息:维基百科骗局的影响、特征和检测."第25届万维网国际会议录。国际万维网会议指导委员会,2016年。
[11]金达尔、尼廷、刘兵。"垃圾观点和分析."2008年国际网络搜索和数据挖掘会议录。ACM,2008年。
[12] Kumar,Srijan等,“FairJudge:评级平台中值得信赖的用户预测。”arXiv预印本arXiv:1703.10545 (2017)。
[13]米科洛夫,托马斯,等,“单词和短语的分布式表示及其组成。”神经信息处理系统的进展。2013.
[14]卡利米、哈米德和汤佶靓。"学习虚假新闻检测的层次语篇结构."arXiv预印本arXiv:1903.07389 (2019)。
[15]宋,昌河,等.《CED:可信的社交媒体谣言早期发现》arXiv预印本arXiv:1811.04175 (2018)。
[16]舒、凯、、王、。"超越新闻内容:社会语境对虚假新闻检测的作用."第十二届美国计算机学会网络搜索和数据挖掘国际会议录。ACM,2019。
[17]假新闻:基础理论、检测策略与挑战,周心怡、礼萨·扎法拉尼、凯舒、刘欢,WSDM,2019。
[18]刘致远,宋长河,杨成。社交媒体平台谣言的早期自动检测。《全球媒体杂志》5.4 (2018): 65-80。英文技术版:长河歌、村潮图、程洋、刘志远、孙茂松。CED:可信的社交媒体谣言早期检测。arXiv预印本arXiv:1811.04175。

1.《coati 清华刘知远+陈慧敏:流言止于“智”者——网络虚假信息的特征与检测》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《coati 清华刘知远+陈慧敏:流言止于“智”者——网络虚假信息的特征与检测》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1089767.html