百度NLP专栏
向前
近年来,我们深入参与了神经网络模型和自然语言处理任务的集成,在句法分析、语义相似度计算和聊天生成方面取得了显著进展。在搜索引擎上,语义相似度已经成为相关性排名系统的重要特征之一。模型越来越复杂,从最初的词袋模型(BOW)到卷积神经网络(CNN)、循环神经网络(RNN)、基于词间匹配矩阵的神经网络(MM-DNN)。同时,由于语言的复杂性、多样性和广泛应用性,为了更好地解决语言学习问题,我们在DNN模型中引入了更多的自然语言处理特征,如基于T统计的二元结构特征、基于依存分析技术的词语搭配结构特征等。
模型越复杂,特征越强,数据越多,对工业应用提出了更高的要求。如何有效地控制内存、减少计算量、降低功耗是深度神经网络模型发展面临的重要问题。压缩算法的研究不仅提高了模型的扩展潜力,而且使其具有更广泛的应用场景和巨大的想象力空。
在百度中,以搜索场景为例,用于相关性排名的神经网络参数规模达到数十亿,而在线环境对计算资源要求严格,模型难以扩展。为此,我们引入了对数域量化、多级乘积量化、多种子随机哈希等模型压缩算法,通过实践,压缩比可以达到1/8。而且这些方法具有很好的通用性,可以在各种神经网络应用场景中借鉴。
对数域量化压缩
对于自然语言处理任务,现有的深度神经网络模型中经常使用数百万个字典,其中嵌入层的参数占整个模型的绝大部分,因此解决模型的内存消耗从嵌入层开始。图1是相关排序系统中使用的卷积神经网络模型的嵌入层参数的值域分布图;
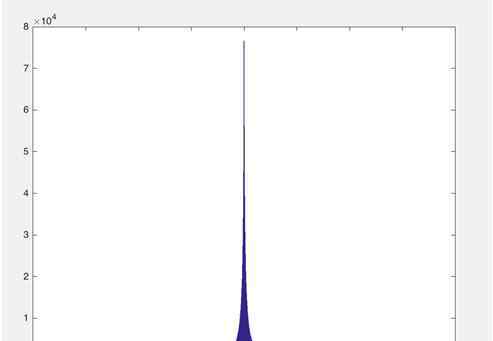
图1。嵌入层参数范围分布图
从上面的分布图可以看出数据分布的特点:
1.参数范围跨度大;
2.大部分参数集中在一个小区域,峰值的分布呈现为以0为中心。
现在,需要对图1所示的参数进行量化,以达到压缩的目的。这里的量化是指连续值(或大量可能的离散值)逼近有限数量(或更少)的离散值的过程。如果选择整个取值范围空,平均取几个量化点,那么大部分参数的取值范围内只会有几个量化点。如果量化范围缩小,一些重要的参数会丢失,对效果的影响也很大。所以需要找到这样一种选择量化点的方法:一方面保持原模型值范围空之间的上限,适当去掉0附近的参数(剪枝);另一方面,参数分布越密集,量化点的选择越密集。
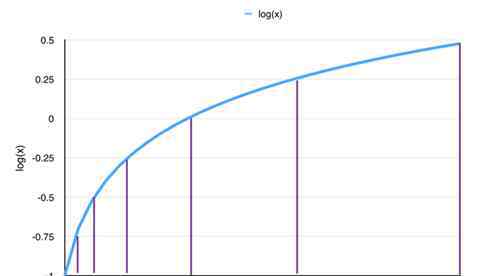
图2。对数量化曲线
我们选择在对数域选择量化点,以满足上述两个要求。从图2可以看出,量化点在Log域中被平均,并且这些点被映射到原始参数空。量化点越接近0,量化点越密集。具体算法如下:首先根据量化位数(本文用b表示量化位数,即最终量化点数为2b),从大到小取对应的量化点数;然后将上限保持在原模型的取值范围空之间,将参数修剪到0附近。Log域量化压缩非常有效,其优点是:量化比特为8时可以实现无损压缩,这意味着深度神经网络模型的嵌入空被量化为只有28=256个离散值;原始模型不需要重新训练。
该方法将百度搜索到的深度神经网络语义模型无损压缩1/4,即在在线模型表达能力不变、应用效果相当的前提下,将所有在线模型的内存占用减少75%。
多级乘积量化压缩
为了在量化中获得更大的压缩比,我们探索了乘积量化压缩。这里的乘积指的是笛卡儿积,也就是嵌入向量按照笛卡儿积进行分解,分解后的向量分别进行量化。与Log域量化压缩不同,乘积量化压缩主要以量化单位变化:前者是数字,后者是矢量。在图3所示的例子中,分解后的向量维数设置为4,通过K-means聚类对这些4维分解向量进行量化压缩(假设量化比特为b,K-means中的K为2b),对于这些4维向量只需要存储聚类中心ID,从而达到压缩的目的。
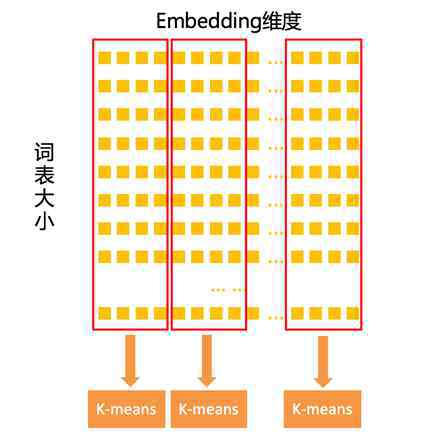
图3。产品量化压缩示意图
基于百度搜索深度神经网络模型的实验,我们分析并得出了一些结论:
1.当量化矢量的维数为1时,可以实现1/4无损压缩;
2.量化矢量维数为2时,可以实现1/5无损压缩;
3.量化的维数是固定的,量化位数越大,压缩比越低,模型效果越好;
4.固定压缩比,随着量化维数的增加,压缩效果先增大后减小,在2D效果最好。
可以看出,当单独使用乘积量化策略时,可以实现高达1/5的无损压缩,与Log域量化压缩相比并没有太大的提高。
为了进一步提高压缩效果,我们引入了多级乘积量化压缩。根据词在词库中的重要性,分别应用不同的产品量化参数。重要词压缩率较低,如使用维数为1、量化位数为8的乘积量化;不太重要的词使用压缩比较高的参数,如维数2、量化位数8;最不重要的词使用压缩比最高的参数,如维数4和量化位数12。这种多级划分是通过自动优化得到的。在百度搜索的深度神经网络语义模型的应用中,我们通过多级乘积量化实现了1/8无损压缩,原始模型无需重新训练,易于使用。
多种子随机散列压缩
到目前为止,多级乘积量化可以实现1/8无损压缩。有没有压缩比更高的压缩算法可以支持超大规模的DNN模型?多种子随机哈希就是这样一种压缩算法:它可以在无损或可接受的有损范围内任意配置压缩比,适用于不同的应用场景。图4是其示意图:
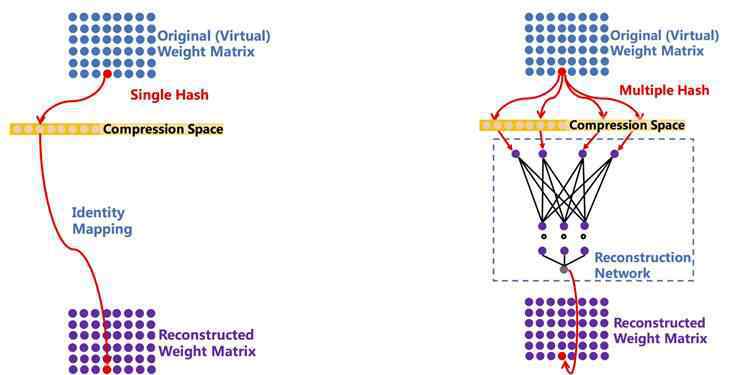
图4。a)单种子随机哈希压缩算法;b)多种子随机哈希压缩算法
图4-a)是陈文林于2015年在ICML发表的“用哈希技巧压缩神经网络”。它的主要思想是通过单个种子随机散列函数连接原始空和压缩空,并通过设置压缩空的大小来配置任意压缩比。但在这种方法中,压缩率与冲突率成正比(这里的冲突是指原始嵌入空之间不同位置的点落入压缩空之间的同一位置),如果冲突率过大,效果会受损。图4-b)是为降低碰撞率而提出的多种子随机散列压缩算法。其流程如下:对于一个待解压的参数,首先根据其位置获取多个随机哈希值,映射到用户配置的压缩空,取出对应的哈希值作为轻量级重构神经网络的输入(图4-b中的虚线框),这个网络的输出就是重构的参数值。与单种子随机哈希压缩算法相比,多种子随机哈希压缩算法具有更低的冲突率,在不损失效果的情况下,在多个任务中实现了更高的压缩率。
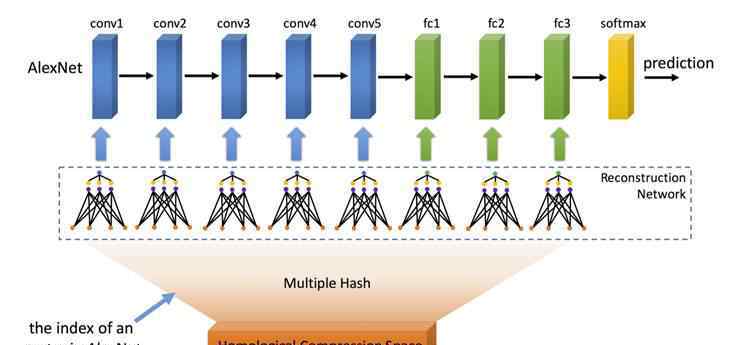
图5。同源多种子随机哈希压缩算法
此外,我们将多种子随机哈希压缩算法扩展到其他神经网络层,如卷积层和全连通层。但是这样会带来一个问题,不同层的压缩比如何设置。为了解决这个问题,我们提出了一种同源压缩算法,如图5所示,即深度神经网络的所有层共享一个压缩空,而不同层有自己的轻量级重构神经网络。这种方法不仅便于设置统一的压缩率,而且通过大量实验证明,压缩效果更好。图6显示了当网络大小固定时,不同压缩率下的错误率。可以看出,在不同数据集、不同深度模型和相同压缩率下,同源多种子随机哈希压缩算法(HMRH)的错误率低于单种子随机哈希压缩算法(HashedNets)。
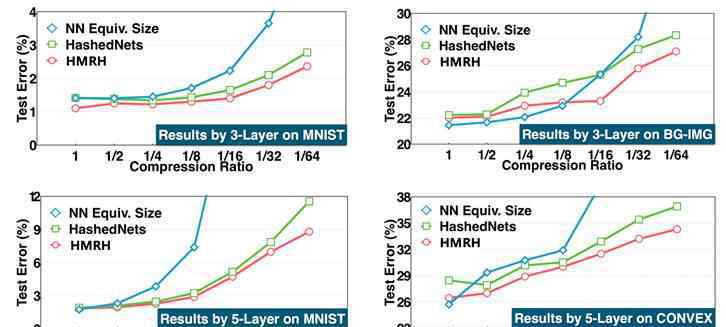
图6。网络规模固定时不同压缩率下的错误率
多种子随机哈希压缩算法可以与上述两种压缩算法一起使用,可以实现更大的无损压缩。
总结
到目前为止,我们已经介绍了三种DNN模型压缩算法,它们各有优势,适用于不同的应用场景:
对数域量化压缩算法可以实现1/4无损压缩,具有普适性,并且不需要对原始模型进行再训练,使用方便。
多级乘积量化压缩算法进一步具有1/8的无损压缩率,根据嵌入的重要性分配不同压缩率的乘积量化,因此适用于嵌入层不同的DNN模型。同样,原模型不需要重新训练,使用方便。
多种子随机哈希压缩算法可以配置任意压缩比,这需要用模型进行训练。它可以与对数域量化压缩相结合,以实现更大的压缩比,因此它可以支持超大规模的DNN模型。举一个极端的例子,如果给世界上72亿人一个128维的嵌入,浮点存储需要3.4T左右的内存,这是一个巨大的内存开销,在常见的单机环境下也很难部署。多种子随机哈希压缩算法如果设置25倍压缩率,辅以Log域量化,可以实现100倍内存压缩到34G,使得在普通单机环境下部署成为可能。即使压缩比设置在可接受的范围内更大,也可以进一步压缩到1G以下,支持嵌入式场景应用。
除了内存压缩,我们还在降低深度神经网络模型的CPU/GPU计算量方面做了大量的工作,剪枝算法就是其中之一。其思想是动态修剪不重要的连接点和边,使矩阵乘法计算稀疏,从而提高正向计算速度。由于篇幅所限,这里不详细讨论相关的优化方法,有兴趣的同学可以进一步联系我们。
百度NLP专栏扩展阅读:
“百度NLP”专栏聚焦百度自然语言处理技术的发展历程,报道前沿信息和趋势,分享技术专家的行业解读和深度思考。

此文为机心专栏,请联系本微信官方账号授权。
✄ -
加入机器的心脏(全职记者实习生):hr@jiqizhixin.com
提交或寻求报告:editor@jiqizhixin.com
广告和:商业合作:bd@jiqizhixin.com
1.《百度压缩 百度NLP | 神经网络模型压缩技术》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《百度压缩 百度NLP | 神经网络模型压缩技术》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1211397.html