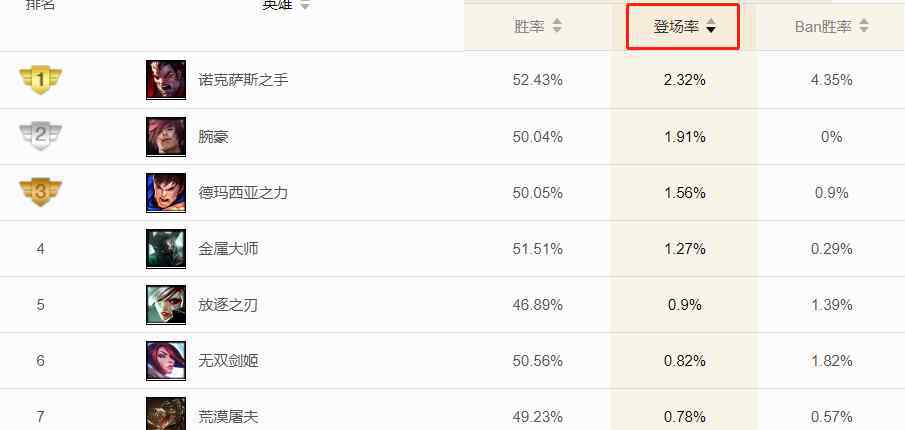
随着大数据时代的到来,如何帮助用户从大量的信息中快速获取有用的信息成为许多企业的重要任务,个性化推荐系统应运而生。基于海量数据挖掘的个性化推荐系统,引导用户发现自己的信息需求,已经在很多领域得到了广泛的应用。传统的个性化推荐系统通过定期分析数据来更新模型。由于定期更新,推荐模型不能保持实时性,对于用户当前行为的推荐结果可能不太准确。实时个性化推荐对用户实时生成的数据进行分析,可以更准确地为用户做出推荐,并根据实时推荐结果进行反馈,从而更好地改进推荐模型。
腾讯大数据平台部和北京大学网络学院崔斌教授的研究团队于2014年开始进行大数据实时推荐的研究。双方合作的论文连续两年在国际顶级会议SIGMOD2015和2016上发表:腾讯REC:实时流推荐在实践SIGMOD 2015,实时视频推荐探索SIGMOD 2016。研究工作的重点是解决实际应用中的问题。针对大数据实时推荐在准确性、实时性和海量性方面的挑战,提出了一种分布式、可扩展的实时增量更新推荐算法,显著提高了推荐效果。该研究方法已应用于包括视频、新闻在内的多个业务,推荐效果得到了显著提高。实时推荐系统现在每天处理数十亿的用户行为,支持数十亿的用户请求。
1.大数据实时计算平台
腾讯大数据实时计算平台TRC[1]由实时数据访问TDBank、实时数据处理TDProcess、分布式K-V存储TDEngine组成,其中TDBank主要负责从业务端访问实时数据,如用户行为数据、物品信息数据等。;TDProcess基于Storm计算实时流入数据,并使用TDEngine存储计算结果供推荐引擎使用。
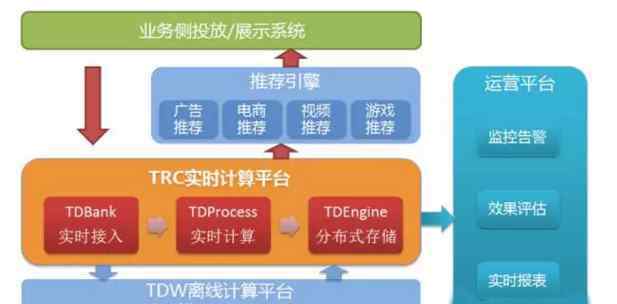
TRC的主要框架如上图所示。关于TRC的文章很多,这里不详细介绍。感兴趣的读者可以参考第[1]条进行详细描述。
2.实时推荐算法
基于Storm的实时计算可以有效地统计处理海量流数据。然而,流计算在机器学习算法中有一个自然的缺点。要完成大数据的实时推荐,实时统计显然不够。我们希望实现推荐算法的实时更新计算。
机器学习中流式实时计算的局限性主要表现在两个方面:一是因为数据以流的形式进入Storm平台,任何时候我们只有当前的流入数据,而没有传统的全局数据的概念,对全局数据的迭代计算正是很多机器学习算法所需要的;其次,Storm平台在计算数据上是不稳定的。在海量数据的背景下,如何保证模型的有效存储、更新和维护成为一个挑战。
对于上面提到的第二个缺陷,我们使用TDE作为解决方案。TDE作为一个高容错、高可用的分布式K-V存储,很好地满足了我们对计算数据的存储要求。对于第一个不足,我们通过精心设计,将原来的离线计算转化为增量计算,实现了几个经典算法:
CF算法:协同过滤算法,根据当前用户对项目的行为,实时更新项目间的共现数据和用户的兴趣分布数据,从而计算项目与用户之间的相似度,基于项目或用户进行协同推荐。
CB算法:通过分析用户的实时行为数据,更新计算用户与不同项目的内容相似度,从而推荐用户。
热点算法:通过接收所有用户的实时行为数据,实时更新热点项目,分析当前热点项目,如实时热点新闻,实时推荐用户。
MF算法:协同过滤矩阵分解算法,根据用户对物品行为的评分矩阵,将矩阵分解为用户和物品的特征向量,从而预测用户对物品的偏好并做出推荐。
实施框架
下图是基于Storm的框架图。系统可分为五层:数据访问层、数据预处理层、算法处理层、商品信息补充层和存储层。数据访问层负责接收数据,预处理层负责根据历史数据完成或过滤数据。算法处理层是系统的主体部分,负责对数据进行分析处理,实现相关推荐算法的计算,并将算法结果传递给下一层。商品信息补充层负责完成算法结果的商品信息,其中完成是结合离线模型或推荐给用户时进一步过滤推荐结果。最后一层是存储层,负责将结果存储在存储部分供使用。
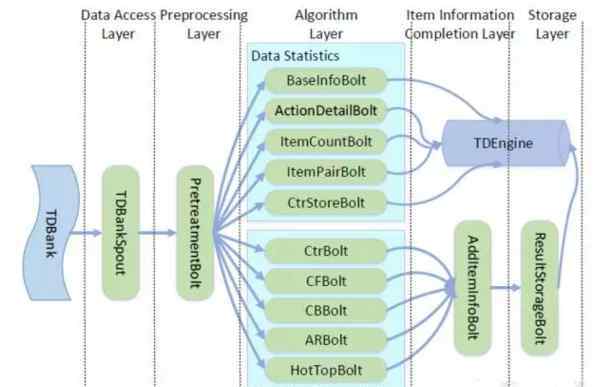
数据访问层
数据访问层负责访问数据,并做简单的检查,对应于TdbankSpout。一般推荐平台接收的数据有五种类型,包括类别数据、行为权重数据、商品属性、用户属性和用户行为数据。
类别数据:每个商品类别的描述和等级,用于基础数据统计
行为权重数据:每个行为的权重,用于基本数据统计
商品属性:每种商品的基本属性和基本数据统计
用户属性:用户的基本属性和基本数据统计
用户行为数据:记录用户的行为,是系统要分析的主要数据。
数据预处理层
包括两个部分,一个是基础信息构建,对应的螺栓是BaseInfoBolt,另一个是用户行为数据的预处理,以及对应的预处理螺栓。基础信息构造接受类别、行为权重、商品属性、用户属性四种数据,存储在对应的表中。预处理螺栓接受用户行为数据,根据用户组信息和历史数据完成或过滤用户行为记录。
算法处理层
算法处理层是系统的主体部分,分为数据统计部分和算法计算部分。数据统计包括用户详细信息统计、最近访问商品统计、人群行为数据统计、人群商品共现数据统计、场景Ctr统计等。
算法计算部分实现了CF、MF、Hot、CB等算法。算法描述如下。
商品信息完成层
商品信息补充层负责完成算法结果的商品信息。这里的完成是根据商品信息过滤算法推荐结果,然后在结合离线模型或者推荐给用户的时候推荐给相应的用户。比如根据离线模型分析的商品价格和用户财富水平过滤推荐结果。有些产品是vip免费的,可以推荐给vip用户,但对于普通用户应该慎重考虑。
存储层
存储层是系统的最后一层,负责在tde中存储推荐结果。tde是腾讯打造的内存k-v存储。在线推荐用户时,从tde中取出推荐结果,结合离线模型,进一步处理后推荐给用户。
2.2实现优化策略
针对实施过程中遇到的问题和挑战,提出了几种优化策略,以优化资源利用,提高效果。
分组计算:在实际计算过程中,我们根据不同的用户群体对数据进行划分,并对划分后的数据集进行计算。用户组可以根据用户的年龄、性别等进行划分。,也可以根据职业、活动等其他信息进行划分。因为不同组中的用户行为模式可能不同,所以可以通过对划分的数据集进行计算来获得更准确的用户行为模式。
滑动窗口:为了保证数据模型的实时性,有些情况下需要“忘记”历史数据,也就是说只有最新的数据用于计算。为此,我们实现了滑动窗口。对于某个时间单位,我们维护了近N个时间窗的数据信息,这些时间窗会实时滑动,丢失最远的数据,保留最新的实时数据信息进行计算。
局部集成:为了有效维护计算数据,我们使用TDE作为数据的外部存储,计算过程中与TDE的交互已经成为不可忽视的计算开销的一部分。为了减少与TDE的互动,减少资源的使用,我们采用了当地融合战略。根据不同的计算特点,我们先在工作人员中整合数据,然后将本地整合结果合并到TDE。实践证明,这种策略有效地减少了与TDE的互动,减少了资源的使用。
多层Hash:在计算过程中,会出现很多工作者需要写相同的Key-Value值的情况,称为写冲突。为了保证TDE的高可用性,我们采用多层哈希策略来解决写冲突问题,减轻了TDE对数据一致性的负担。通过多层哈希策略,对同一密钥的写操作将只发生在同一工作机上。
实时可扩展的基于项目的CF
[2](基于项目的CF是亚马逊2003年发布的推荐算法。由于其推荐效果好,易于实现,在行业内得到了广泛的应用。这里我们以基于项目的dCF算法为例说明实时推荐算法[3]的实现,其他算法的具体描述可以参考文献[3]和[4]。
3.1基于项目的原始数据格式
基于项目的CF的基本思想是用户会喜欢和以前喜欢的项目相似的项目。其计算分为相似项计算和用户偏好预测两部分。相似项目计算是整个算法的关键部分,用户偏好预测根据项目的相似度预测用户对新项目的评分。


3.2基于实时项目的dCF
在传统的推荐算法中,用户的偏好评分是由用户的评分决定的,但在现实世界中,用户的评分数据较少,大部分数据是用户的行为数据,如浏览、点击等。这些用户行为是不确定的。例如,如果用户单击某个项目详细信息页面并关闭它,这可能意味着用户喜欢该项目是因为用户单击了详细信息页面,也可能意味着用户不喜欢该项目是因为用户关闭了详细信息页面。在这种情况下,我们只能从用户行为数据中猜测用户的偏好。
为了减少因误解用户行为数据而造成的损失,我们对原有的基于项目的dCF算法进行了改进。具体来说,我们为每个用户行为类型设置评分权重,以衡量不同行为所表达的用户偏好的可靠性。例如,我们将点击行为的评分权重设置为1分,而将购买行为的评分权重设置为3分,因为用户的购买更有可能表明用户喜欢该项目,而不是点击。对于一个项目,用户可能有许多行为,如点击、购买、评论等。此时,我们将权重最高的用户行为得分作为用户对该项目的偏好。
我们定义用户对两个项目的共同评分,以计算项目的相似性,如下所示:
通过将项目的共同得分设置为两个项目中较低的一个,我们将行为误差估计的损失限制在两者中较小的值。因此,两个项目的相似度计算如下:
为了实现流式实时计算和实时更新项目的相似度,我们将上述计算分为三个部分,如下:
其中,,


3.3实时修剪策略
在实际计算过程中,我们发现由于数据量较大,用户的某种行为会带来大量需要重新计算的项目。具体来说,我们一般认为用户在某段时间内交互的项目是相互关联的,也就是说可能是相似的。这段时间可能是一天,也可能是一个月,所以用户行为带来的项目分值的更新,可能会导致几十个甚至几百个项目对的相似度被重新计算,而这些项目可能没有那么多相似,也就是说,
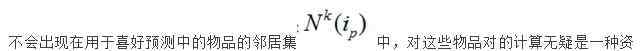

4总结
随着近年来个性化服务的发展,推荐系统在实际应用中的价值越来越得到认可。大数据实时推荐在推荐效果上的优异表现及其大发展空备受关注。大数据实时推荐还有很多值得探索的地方,比如实时矩阵分解、实时LR、实时深度学习等在线学习算法。
[1]“腾讯实时计算平台(TRC)系列:首次会议TRC”
[2]林登、史密斯和约克。Amazon.com推荐:逐项协同过滤。《电子互联网计算》,7(1):76–80,2003年1月
[3]、黄、、、、。腾讯网:实践中的实时流推荐。[C]//2015年ACM SIGMOD会议纪要。ACM,2015: 227-238
[4]黄,,,,洪,,,谢。实时视频推荐。SIGMOD 2016年
文章来自www.36dsj.com 36大数据,微信号大树巨36,36大数据是一个专注于大数据创业、大数据技术与分析、大数据业务与应用的网站。分享大数据干货教程和大数据应用案例,提供大数据分析工具和数据下载,解决大数据产业链中的创业、技术、分析、商务、应用等问题,为大数据产业链中的数据行业公司和员工提供支持和服务。
结束。
1.《数据统计平台 大数据实时推荐-不只是统计》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《数据统计平台 大数据实时推荐-不只是统计》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/1650524.html