分布式存储的出现是因为单机存储资源有限且难以扩展,分布式计算的出现也是因为单机计算资源有限且难以扩展。存储资源一般指磁盘容量,计算资源一般指内存和CPU。
我们引用中科院的定义来详细了解什么是分布式计算:
分布式计算是一种新的计算方法。所谓分布式计算,就是两个或两个以上的软件互相共享信息,这些软件可以在同一台计算机上运行,也可以在通过网络连接的多台计算机上运行。
与其他算法相比,分布式计算具有以下优势:
1.稀有资源可以共享。
2.分布式计算可以平衡多台计算机上的计算负载。
3.你可以把程序放在最适合运行它的电脑上。
这个定义真的很精辟,既指出了分布式计算的内涵,也指出了分布式计算存在的问题。我们来分解一下这个定义。
首先,我们标记一些关键词:软件、网络、运营、资源、共享、平衡、负载和适用性。
我们不看上面的定义,只看这些关键词,就可以勾勒出分布式计算所需的子系统:
1.调度系统:对应的关键词是均衡、合适、负载-->:如果你想活得井井有条,最好有人给你安排。
2.交流系统:对应关键词网络,分享->:如果想交流,一起玩,至少有一个电话。
3.计算系统:软件、资源、运营对应关键词->:想吃饭,至少有个活厨子。
同样,我们可以先列出这些关键词的对立面:网络不可靠、运行问题、资源不足、共享性差、分布不均衡、负载过大,不适合根据这些反向关键词来勾勒分布式系统可能出现的问题:
1.资源调度不合理导致负载不均衡,无法充分利用集群资源:对应的关键字资源不足,分配不均衡,负载过大不适合。
2.计算的可靠性低导致结果错误或计算失败:对应的关键字网络不可靠,操作失常。
调度问题占4个关键词,占总关键词的67%,说明中科院认为调度问题是分布式计算中最关键的因素。是的,我们也这样认为。因此,我们将首先介绍spark的调度系统,然后提出另外两个系统,顺便提出spark对这两个问题的解决方案。
Spark框架
Spark的调度系统自上而下由DAGScheduler(作业级调度器)、TaskScheduler(任务级调度器)和SchedulerBackend(调度资源管理器)组成,它们的关系如下图所示:
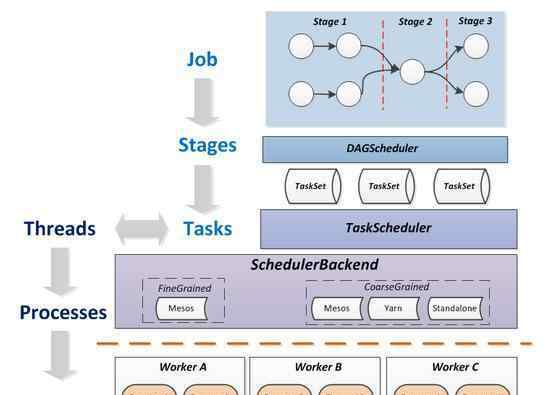
为了让大家快速对这个过程有一个直观的认识,我们参考例子来解释一下:
新来的校长(DAGScheduler)决定整理一下学校的现状,统计一下学校的男女生人数,并制作一份报告(Job-output report on the number of男女生),并决定让秘书先找人按班级统计男女生人数,每个班级会制作一份报告,然后让男女生人数合并(两个Stage-class报告,报告合并)。同时校长规定了做这个的最大组数(Executor-实际工作环境,对应Java虚拟机),以及每个组的最大人数(Thread-单个Executor中最大的并行工作个体,对应CPU内核数-每个Thread只能做一个单一的工作,所以不仅要数男生的数量,还要数女生的数量)。
秘书接到指令后,根据班级数、班级数、班级位置(比如哪个小组负责哪个班最快——最近)来规划小组的具体工作。
然后秘书去外包公司组(schedulerbacknd-一个专门做外包人力的组织),外包组根据计划把人力需求分配给各个公司(Worker)。如果所有人都出动了,告诉秘书等一会儿(Spark程序启动时的接受状态)。一旦有人回来,外包组要求此人按照计划统计相应班级的男女人数(Task-人数等于班级人数* 2-因为每个班级必须统计男生女生人数),随着人员的逐步回归,派出的人数也会逐渐跟上计划。
校长将跟踪统计数据。每当一个班的男生或女生被统计出来,校长就会拿出一本小书,把这个任务从待办事项清单上抹掉,直到全部抹掉。然后,如果生成了每个类的报告,就认为完成了类统计(第一阶段)。同样,负责人将计算阶段数,以判断作业是否完成。
虽然这部作品使用Spark的框架作为杀鸡的工具,但是上面的例子应该让你对概念有一个大概的了解,下面我们会对这些概念给出一个相对严格的定义。
Job 指一次 action 操作,Spark 对数据的操作包括 transform 操作和 action 操作,action 操作指有数据输出(无论是输出到文件还是输出到控制台)的操作,spark 是懒的,一段程序只有遇到 action 操作才会真正调度执行。Spark 按照 action 操作对应用进行 Job 切分。Stage 一个 Job 会根据 Shuffle 被拆分为多个 Stage 。所谓的 shuffle 就是宽依赖。所谓的宽依赖就是父 RDD 的分区影响了多个 RDD 的分区。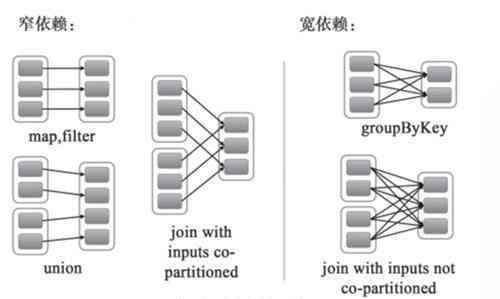
这些概念之间的关系可以从上面的例子中推导出来,官方地图更简洁:
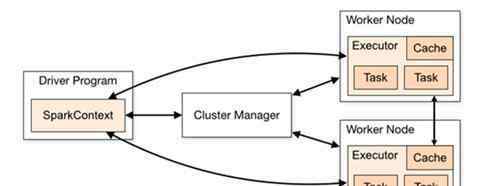
Spark虽然有自己的调度机制和逻辑,但只能在多个提交的作业中实现优化。如果要根据集群资源和负载压力做出最佳分配决策,单靠Spark是做不到的。因此,在工程应用中,Spark很少单独部署和使用,而是与纱线结合,利用纱线的资源管理和分配能力给出最优的分配策略。
其实MapReduce和Storm一般都是依靠纱线的资源管理能力。这就是上面第一个问题的答案——不要逞能,让专业的人去做专业的事。
Spark的内部沟通非常复杂。客户和主人之间,主人和工人之间,工人和工人之间都有沟通。而且整个操作非常快,资源消耗比较大。所以我不会通过阻塞I/O来在线等待,所以我选择了NIO(发送响应后立即返回,释放资源,等待回调)模式。事实上,几乎没有大数据在线系统不会采用这种方案。在1.6之前,Spark采用了基于Actor模型的Akka通信框架,但由于一些管理和依赖冲突,在1.6之后被Netty框架取代。
Spark还使用一系列超时机制来防止网络异常导致的问题。它通过累加器计数识别运行时异常,并使用阶段重新提交来解决这些异常。
1.《分布式计算 白话分布式 之 分布式计算框架——Spark》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《分布式计算 白话分布式 之 分布式计算框架——Spark》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/fangchan/895442.html
