深度信念网络,DBN)是杰弗里·辛顿在2006年提出的。是一代模式。通过训练神经元之间的权重,可以使整个神经网络按照最大概率生成训练数据。
我们不仅可以使用DBN来识别特征和分类数据,还可以使用它来生成数据。下图显示了用DBN识别手写数字:
此时,计算每个隐藏元素hj的打开概率。它处于闭合状态的概率自然是
所以不管这个元素是打开还是关闭,我们需要比较打开的概率和从0,1均匀分布中提取的随机值
进行以下比较
然后打开或关闭相应的隐藏元素。
给定隐藏层,计算显式层的方法是相同的。
训练RBM
实际上,RBM的训练过程就是寻找一个最能产生训练样本的概率分布。也就是说需要一个分布,其中训练样本的概率最高。
既然这个分布的决定性因素在于权重W,那么训练RBM的目标就是找到最佳权重。为了保持读者的兴趣,这里不给出最大对数似然函数的推导过程,直接说明如何训练RBM。
G.辛顿提出了一种叫做对比发散的学习算法。下面我们来详细描述一下它的具体流程。
我们使用上面提到的符号表示法。
算法1。对比度发散
对于训练集中的每条记录

经过这种训练,RBM可以准确地提取出显性层的特征,或者根据隐性层
恢复层的特征。
深度信念网络
我们已经介绍了RBM的基本结构及其培训和使用过程,然后我们将介绍DBN的相关内容。
DBN是一个由多层RBM构成的神经网络,既可以看作是一个生成模型,也可以看作是一个判别模型。其训练过程是利用无监督的贪婪逐层方法进行预训练,获取权重。
培训流程:
1.首先,全面培养第一个RBM;;
2.固定第一个RBM的权重和偏移量,然后用其隐性神经元的状态作为第二个RBM的输入向量;
3.经过充分训练的第二个RBM,将第二个RBM叠加在第一个RBM之上;
4.重复以上三个步骤任意多次;
5.如果训练集中的数据有标签,那么在顶RBM训练中,除了优势神经元,代表分类标签的神经元需要一起训练:
a)假设顶RBM的外显层有500个优势神经元,训练数据的分类分为10类;
b)顶RBM外显层有510个优势神经元。对于每个训练数据,相应的标签神经元被打开并设置为1,而其他的被关闭并设置为0。
6.DBN经过训练,如下:
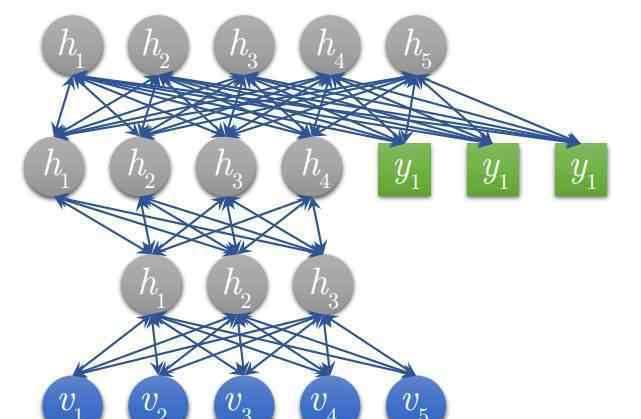
图3训练的深度信念网络。图中绿色部分是参加顶级RBM训练的标签。请注意,微调过程是一个判别模型
此外:
调整过程:
生成的模型通过对比唤醒-睡眠算法进行优化,算法流程如下:
1.除了顶级RBM,其他RBM层的权重分为向上认知权重和向下世代权重;
2.唤醒阶段:认知过程,其中每一层的抽象表示由外部特征和向上权重生成,层间向下权重由梯度下降修正。也就是“如果现实和我想象的不一样,改变体重让我思考。”
好像事情是这样的。".
3.睡眠阶段:生成过程,通过顶层表示和向下权重生成底层状态,修改层间向上权重。也就是“如果梦里的场景不是我脑海中对应的概念,那么改变我的认知权重,在我看来就让这个场景变成这样。”
阅读”。
使用过程:
1.使用随机隐性神经元状态值,并在顶部RBM进行足够次数的吉布斯采样;
2.向下展开以获取每一层的状态。
以下是对前一条的补充
深度信任网络
数据库网络是一种概率生成模型。与传统判别模型的神经网络相比,生成模型建立了观测数据和标签的联合分布,同时对P和P进行评价,而判别模型只对后者进行评价,即P。
将传统的BP算法应用于深度神经网络时,数据库网络会遇到以下问题:
需要提供有标签的样本集进行训练;
学习过程缓慢;
参数选择不当会导致学习收敛到局部最优解。
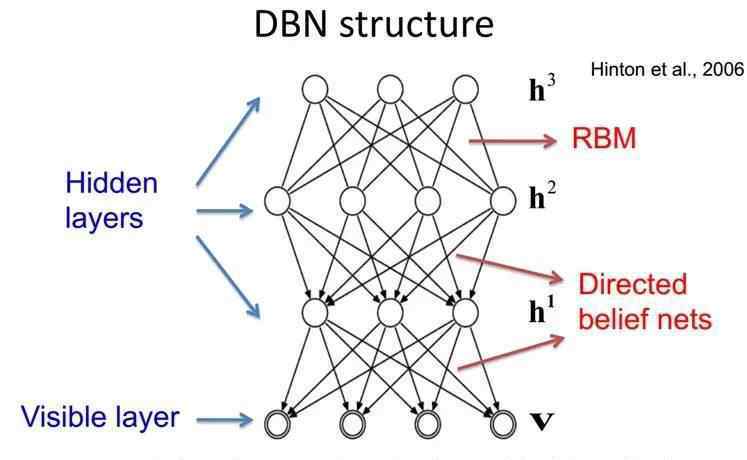
数据库网络由几层受限玻尔兹曼机器组成,典型的神经网络类型如图3所示。
这些网络“限于”一个可见层和一个隐藏层,层与层之间有联系,但层内单元之间没有联系。隐藏层单元被训练来捕捉视觉层中呈现的高阶数据的相关性。
首先,不考虑组成关联存储器的顶部两层,DBN的连接是通过从顶部到底部生成权重来确定的。RBMs就像一个积木,比传统的深层sigmoid信念网络更容易学习连接权重。
首先,采用无监督的贪婪逐层方法对生成的模型进行预训练并获取权重。辛顿证明了无监督逐层贪婪方法的有效性,称之为对比发散。
在这个训练阶段,在视觉层生成一个向量V,通过它将值传输到隐藏层。相反,视觉层的输入将被随机选择,以尝试重建原始输入信号。最后,这些新的视觉神经元激活单元通过前向传输重构隐藏层激活单元,得到h。
这些后向和前向步骤称为吉布斯采样,隐藏层激活单元与可见层输入的相关性差异是更新权重的主要依据。
训练时间将大大减少,因为只需要一个步骤就可以实现最大似然学习。加入到网络的每一层都会提高训练数据的对数概率,可以理解为越来越接近能量的真实表达。这种有意义的扩展和未标记数据的使用是任何深度学习应用的决定性因素。
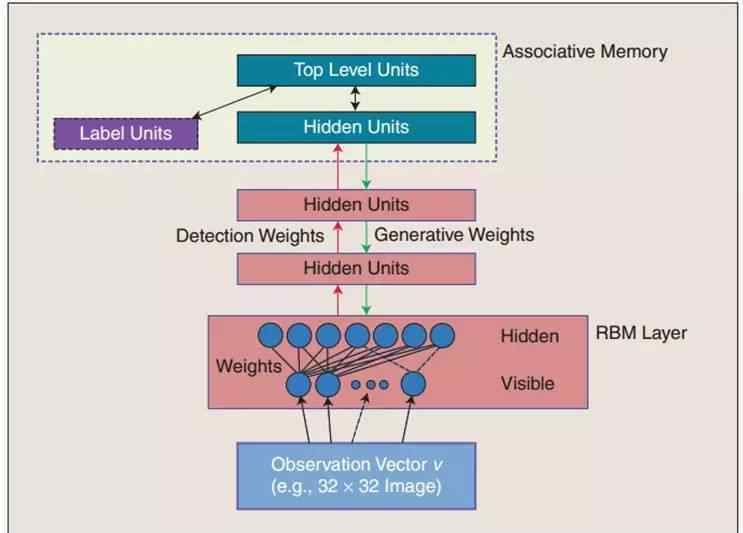
在上面两层,权重连接在一起,这样下层的输出会提供一个参考线索或者与上层相关联,这样上层会将其与其内存内容相关联。我们最后最关心和最想要的是判别性能,比如分类任务。
经过预训练后,DBN可以使用BP算法,通过使用标记数据来调整识别性能。这里,标签集将被附加到顶层,并且网络的分类表面将通过自下而上的学习识别权重来获得。
这种性能会优于简单BP算法训练的网络。这个可以直观解释。DBNs的BP算法只需要在权重参数空之间进行局部搜索。与前馈神经网络相比,训练速度更快,收敛时间更短。
DBNs的灵活性使其更容易扩展。一个扩展是卷积深信念网络。
DBNs不考虑图像的二维结构信息,因为输入是从一维图像矩阵简单矢量化而来的。CDBNs考虑了这个问题。它利用相邻像素的空域关系,通过一个称为卷积RBMs的模型区域来实现生成模型的变换不变性,可以很容易地变换到高维图像。
数据库网络并不明确处理观察变量的时间关系的研究,尽管在这一领域已经有过研究,如叠加时间径向基函数,它是顺序学习的推广和称呼
时间卷积机是序列学习的应用,为语音信号处理带来了一个令人振奋的未来研究方向。
目前,与数据库网络相关的研究包括堆叠式自动编码器,它用堆叠式自动编码器取代了传统数据库网络中的RBMs。
这使得通过相同的规则训练和产生深层多层神经网络体系结构成为可能,但是它缺乏对层的参数化的严格要求。与DBNs不同,自动编码器使用判别模型,因此这种结构很难对输入样本空进行采样,这使得网络更难捕捉其内部表达式。
而降噪自动编码器可以很好的避免这个问题,比传统的DBNs要好。它通过添加随机污染并在训练过程中叠加来产生场泛化性能。训练单个去噪自动编码器的过程与生成RBMs训练模型的过程相同。
个人理解:
在DBNs网络中,它的训练是逐层进行的,每一层训练完后叠加下一层,计算这一层的参数。
另外,DBNs可以看作一个无监督的自编码过程,最后一层可以通过加入分类成分来训练。SAE,SDAE,DBN可以算大型,缺点是只能是一维数据。
1.《深信网络 深度信念网络》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《深信网络 深度信念网络》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/jiaoyu/1733080.html