沈剑技术发明的人工智能芯片结合了神经网络专用处理器和通用处理器的芯片结构,不仅可以提供灵活的系统,而且适用于复杂的神经网络。
近年来,随着人工智能的兴起,越来越多的AI芯片公司出现在人们的视野中,AI芯片广泛应用于金融、购物、安防、早教、无人驾驶等领域。其中,沈剑科技也以先进的技术出现在市场上。
沈剑科技的AI芯片是基于FPGA设计的,其Aristotle架构是为卷积神经网络设计的,其Cartesian架构是为处理DNN/RNN网络设计的,能够极其高效地加速结构压缩后的稀疏神经网络硬件。
卷积神经网络广泛应用于人工智能领域,尤其是图像处理领域。然而,神经网络具有大量的存储和计算量。工程师试图在FPGA上搭建或直接设计专用芯片,实现人工智能芯片。但是这种特殊的神经网络加速器硬件不够灵活,能完成的任务也比较单一。
为了解决这个问题,沈剑科技于2016年8月19日申请了一项名为“通用处理器与神经网络处理器协同系统设计”的发明专利。申请人是北京沈剑科技有限公司..
根据这个专利公开的信息,我们来看看人工智能芯片这个专利。
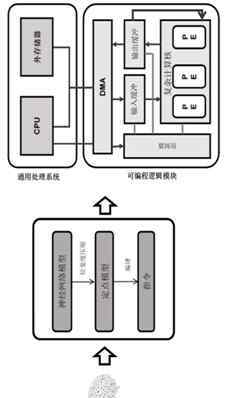
如上图,是在专用硬件上部署人工神经网络模型的流程图。这是为了加快神经网络训练过程,从优化过程硬件架构的角度出发的一套技术解决方案。它展示了如何压缩CNN模型,以减少内存占用和操作次数,同时最小化准确性的损失。
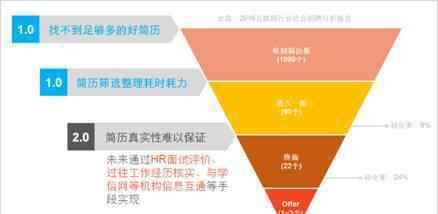
这个硬件架构包括两个模块:PS和PL,其中PS是通用处理系统,包含CPU和外部内存;PL是一个可编程逻辑模块,包括DMA、计算核心、I/O缓冲和控制器。计算核心包括多个处理单元,负责人工智能网络卷积层和全连接层的大部分计算任务,是实现人工智能芯片的核心部件。
值得一提的是,在这种架构下,虽然DMA分布在PL端,但直接由CPU控制,将数据从外部存储区携带到PL。同时这种硬件架构只是功能上的划分,PL和PS的界限并不是绝对的。比如说PL和CPU只能在SOC上实现,而外部存储器可以通过另一个内存芯片实现,在SOC芯片中与CPU相连。
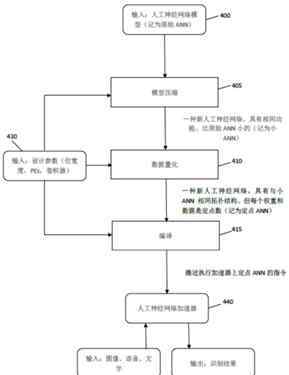
上图是优化人工神经网络的总体流程图。首先,模型应该被压缩。压缩可以修剪CNN模型,网络修剪是一种有效的方法,可以降低网络的复杂度和过拟合。其次,数据的定点量化旨在将浮点数转换为定点数,获得最高的精度。
之后通过编译,通过这样的结构设计得到人工神经网络加速器,可以输入图像、语音、文字,输出识别结果。这样,简化的结构有利于硬件设计,同时省略了复杂的操作,进一步提高了人工智能芯片的运行效率。
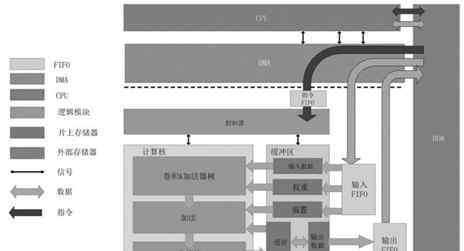
如上图所示,人工神经网络的硬件架构是通过CPU和专用加速器的协同设计实现的。在这种硬件架构中,CPU控制着负责调度数据的DMA。具体来说,CPU可以控制DMA将外部存储器中的指令携带到FIFO中,然后这个为神经网络设计的加速器从FIFO中取出指令并执行。
CPU在运行时需要时刻监控DMA的状态:当输入缓冲区中的数据未满时,需要将数据从DDR传输到输入缓冲区;当输出缓冲区不是空时,需要将数据从输出缓冲区带回DDR。
此外,该结构中使用的专用加速器包括控制器、计算核心和缓冲器。计算核心包括涡旋机、加法器树和非线性模块。这些结构保证了人工智能芯片能够完成深层神经网络的操作,从而能够完成不同的复杂人工智能任务。
以上是沈剑科技发明的人工智能芯片。这种神经网络专用处理器和通用处理器相结合的芯片结构可以为人工智能应用提供一个灵活的系统,并可以应用于复杂的神经网络。此外,该方案实现了控制器和存储器的分离,可以使用不同的SOC芯片来完成,从而保证了系统的稳定性。
1.《深鉴科技 【专利解密】深鉴科技结合神经网络处理器与通用处理器的AI芯片》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《深鉴科技 【专利解密】深鉴科技结合神经网络处理器与通用处理器的AI芯片》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/keji/727125.html