 资料图
资料图
文章来源:量子位
仅剩0.2%的星际2玩家,还没有被AI碾压。
这是匿名混入天梯的AlphaStar,交出的最新成绩单。
同时,DeepMind也在Nature上完整披露了AlphaStar的当前战力和全套技术:
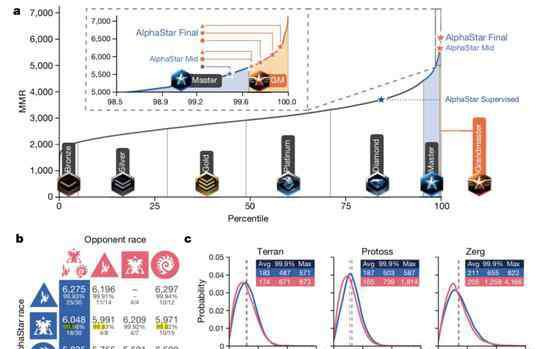
AlphaStar,已经超越了99.8%的人类玩家,在神族、人族和虫族三个种族上都达到了宗师级别。
在论文里,我们还发现了特别的训练姿势:
不是所有智能体都为了赢
DeepMind在博客里说,发表在Nature上的AlphaStar有四大主要更新:
一是约束:现在AI视角和人类一样,动作频率的限制也更严了。
二是人族神族虫族都能1v1了,每个种族都是一个自己的神经网络。
三是联赛训练完全是自动的,是从监督学习的智能体开始训练的,不是从已经强化学习过的智能体开始的。
四是战网成绩,AlphaStar在三个种族中都达到了宗师水平,用的是和人类选手一样的地图,所有比赛都有回放可看。
具体到AI的学习过程,DeepMind强调了特别的训练目标设定:
不是每个智能体都追求赢面的最大化。
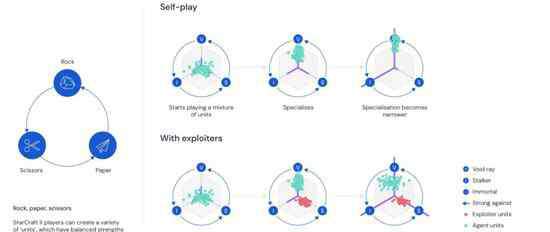
因为那样智能体在自我对战 过程中,很容易陷入某种特定的策略,只在特定的情况下有效,那面对复杂的游戏环境时,表现就会不稳定了。
于是,团队参考了人类选手的训练方法,就是和其他玩家一起做针对性训练:一只智能体可以通过自身的操作,把另一只智能体的缺陷暴露出来,这样便能帮对方练出某些想要的技能。
这样便有了目标不同的智能体:第一种是主要智能体,目标就是赢,第二种负责挖掘主要智能体的不足,帮它们变得更强,而不专注于提升自己的赢率。DeepMind把第二种称作“剥削者 ”,我们索性叫它“陪练”。
AlphaStar学到的各种复杂策略,都是在这样的过程中修炼得来的。
比如,蓝色是主要玩家,负责赢,红色是帮它成长的陪练。小红发现了一种cannon rush技能,小蓝没能抵挡住:

然后,一只新的主要玩家 就学到了,怎样才能成功抵御小红的cannon rush技能:

同时,小绿也能打败之前的主要玩家小蓝了,是通过经济优势,以及单位组合与控制来达成的:

后面,又来了另一只新的陪练 ,找到了主要玩家小绿的新弱点,用隐刀打败了它:

循环往复,AlphaStar变得越来越强大。
至于算法细节,这次也完整展现了出来。
AlphaStar技术,最完整披露
许多现实生活中的AI应用,都涉及到多个智能体在复杂环境中的相互竞争和协调合作。
而针对星际争霸这样的即时战略游戏的研究,就是解决这个大问题过程中的一个小目标。
也就是说,星际争霸的挑战,实际上就是一种多智能体强化学习算法的挑战。
AlphaStar学会打星际,还是靠深度神经网络,这个网络从原始游戏界面接收数据 ,然后输出一系列指令,组成游戏中的某一个动作。
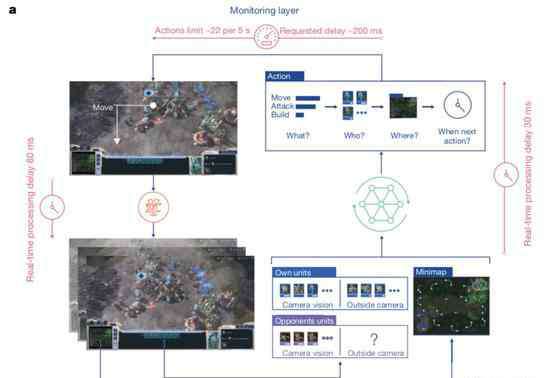
AlphaStar会通过概览地图和单位列表观察游戏。
采取行动前,智能体会输出要发出的行动类型,将该动作应用于谁,目标是什么,以及何时发出下一个行动。
动作会通过限制动作速率的监视层发送到游戏中。
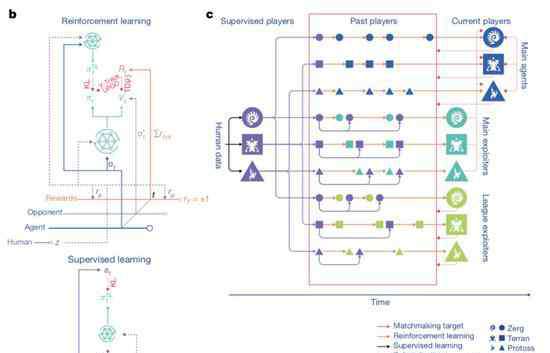
而训练,则是通过监督学习和强化学习来完成的。
最开始,训练用的是监督学习,素材来自暴雪发布的匿名人类玩家的游戏实况。
这些资料可以让AlphaStar通过模仿星际天梯选手的操作,来学习游戏的宏观和微观策略。
最初的智能体,游戏内置的精英级 AI就能击败,相当于人类的黄金段位 。
而这个早期的智能体,就是强化学习的种子。
在它的基础之上,一个连续联赛 被创建出来,相当于为智能体准备了一个竞技场,里面的智能体互为竞争对手,就好像人类在天梯上互相较量一样:
从现有的智能体上造出新的分支,就会有越来越多的选手不断加入比赛。新的智能体再从与对手的竞争中学习。
这种新的训练形式,是把从前基于种群 的强化学习思路又深化了一些,制造出一种可以对巨大的策略空间进行持续探索的过程。
这个方法,在保证智能体在策略强大的对手面前表现优秀的同时,也不忘怎样应对不那么强大的早期对手。
随着智能体联赛不断进行,新智能体的出生,就会出现新的反击策略 ,来应对早期的游戏策略。
一部分新智能体执行的策略,只是早期策略稍稍改进后的版本;而另一部分智能体,可以探索出全新的策略,完全不同的建造顺序,完全不同的单位组合,完全不同的微观微操方法。
除此之外,要鼓励联赛中智能体的多样性,所以每个智能体都有不同的学习目标:比如一个智能体的目标应该设定成打击哪些对手,比如该用哪些内部动机来影响一个智能体的偏好。
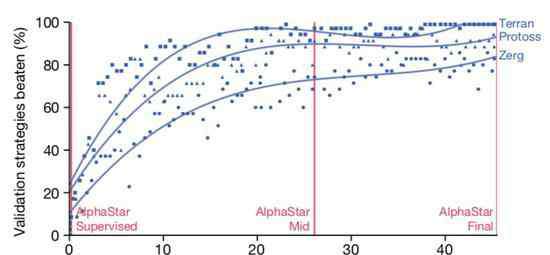
△联盟训练的鲁棒性
而且,智能体的学习目标会适应环境不断改变。
神经网络给每一个智能体的权重,也是随着强化学习过程不断变化的。而不断变化的权重,就是学习目标演化的依据。
权重更新的规则,是一个新的off-policy强化学习算法,里面包含了经验重播 ,自我模仿学习 以及策略蒸馏 等等机制。
历时15年,AI制霸星际
《星际争霸》作为最有挑战的即时战略游戏之一,游戏中不仅需要协调短期和长期目标,还要应对意外情况,很早就成为了AI研究的“试金石”。
因为其面临的是不完美信息博弈局面,挑战难度巨大,研究人员需要花费大量的时间,去克服其中的问题。
DeepMind在Twitter中表示,AlphaStar能够取得当前的成绩,研究人员已经在《星际争霸》系列游戏上工作了15年。
但DeepMind的工作真正为人所知,也就是这两年的事情。
2017年,AlphaGo打败李世石的第二年后,DeepMind与暴雪合作发布了一套名为PySC2的开源工具,在此基础上,结合工程和算法突破,进一步加速对星际游戏的研究。
之后,也有不少学者围绕星际争霸进行了不少研究。比如南京大学的俞扬团队、腾讯AI Lab、加州大学伯克利分校等等。
到今年1月,AlphaStar迎来了AlphaGo时刻。
在与星际2职业选手的比赛中,AlphaStar以总比分10-1的成绩制霸全场,人类职业选手LiquidMaNa只在它面前坚持了5分36秒,就GG了。

全能职业选手TLO在落败后感叹,和AlphaStar比赛很难,不像和人在打,有种手足无措的感觉。
半年后,AlphaStar再度迎来进化。
DeepMind将其APM 、视野都跟人类玩家保持一致的情况下,实现了对神族、人族、虫族完全驾驭,还解锁了许多地图。

与此同时,并宣布了一个最新动态:AlphaStar将登录游戏平台战网,匿名进行天梯匹配。
现在,伴随着最新论文发布,AlphaStar的最新战力也得到公布:击败了99.8%的选手,拿到了大师级称号。
DeepMind在博客中表示,这些结果提供了强有力的证据,证明了通用学习技术可以扩展人工智能系统,使之在复杂动态的、涉及多个参与者的环境中工作。
而伴随着星际2取得如此亮眼的成绩,DeepMind也开始将目光投向更加复杂的任务上了。
CEO哈萨比斯说:
星际争霸15年来一直是AI研究人员面临的巨大挑战,因此看到这项工作被《自然》杂志认可是非常令人兴奋的。
这些令人印象深刻的成果,标志着我们朝目标——创造可加速科学发现的智能系统——迈出了重要的一步。
那么,DeepMind下一步要做什么?
哈萨比斯也多次说过,星际争霸“只是”一个非常复杂的游戏,但他对AlphaStar背后的技术更感兴趣。
但也有人认为,这一技术非常适合应用到军事用途中。
不过,从谷歌与DeepMind 的态度中,这一技术更多的会聚焦在科学研究上。
其中包含的超长序列的预测,比如天气预测、气候建模。
或许对于这样的方向,最近你不会陌生。
因为谷歌刚刚实现的量子优越性,应用方向最具潜力的也是气候等大问题。
现在量子计算大突破,DeepMind AI更进一步。
未来更值得期待。你说呢?
One more thing
虽然AlphaStar战绩斐然,但有些人它还打不赢。
当时AlphaStar刚进天梯的时候,人类大魔王Serral就公开嘲讽,它就是来搞笑的。

但人家的确有实力,现在依旧能正面刚AI。
不过,敢这样说话的高手,全球就只有一个。
传送门
Nature论文:
https://doi.org/10.1038/s41586-019-1724-z
论文预印版:
https://storage.googleapis.com/deepmind-media/research/alphastar/AlphaStar_unformatted.pdf
博客文章:
https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning
对战录像:
https://deepmind.com/research/open-source/alphastar-resources
— 完 —
1.《久久棋牌游戏 碾压99.8%人类对手 星际AI登上Nature技术首披露》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《久久棋牌游戏 碾压99.8%人类对手 星际AI登上Nature技术首披露》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/tiyu/79917.html