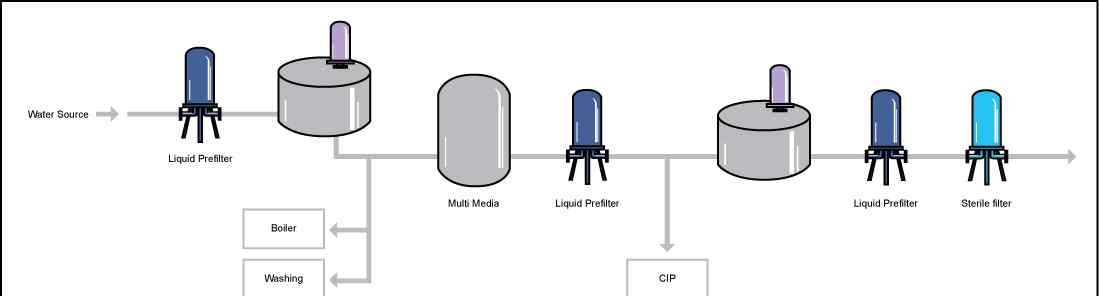
墨墨入门:我们分享了弹性搜索最全面最详细的教程:简介,索引管理,映射细节。本文详细介绍了弹性搜索的索引别名、单词分隔符、文档管理、路由和搜索细节。
I .索引别名

1.别名的用途
如果要一次查询,可以查询多个索引。
如果您想通过索引视图来操作索引,就像数据库中的视图一样。
索引的别名机制是我们可以在一个视图中操作集群中的索引,可以是多个索引,一个索引,也可以是一个索引的一部分。
2.创建新索引时定义别名
PUT /logs_20162801 { "mappings": { "type": { "properties": { "year": {"type": "integer"} } } }, <!-- 定义了两个别名 --> "aliases": { "current_day": {}, "2016": { "filter": { "term": {"year": 2016} } } } }3.创建别名/_别名
为索引测试1创建别名alias1
POST /_aliases { "actions": [ { "add": { "index": "test1", "alias": "alias1"} } ] }4.删除别名
POST /_aliases { "actions": [ { "remove": { "index": "test1", "alias": "alias1"} } ] }也可以这样写
DELETE/{index}/_alias/{name}5.批量操作别名
删除索引测试1的别名alias1,同时添加索引测试2的别名alias1
POST /_aliases { "actions": [ { "remove": { "index": "test1", "alias": "alias1"} }, { "add": { "index": "test2", "alias": "alias1"} } ] }6.为多个索引定义相同的别名
模式1:
POST /_aliases { "actions": [ { "add": { "index": "test1", "alias": "alias1"} }, { "add": { "index": "test2", "alias": "alias1"} } ] }模式2:
POST /_aliases { "actions": [ { "add": { "indices": ["test1", "test2"], "alias": "alias1"} } ] }注意:只能按多索引别名搜索,不能按id索引文档和获取文档。
模式3:通过通配符*模式指定要别名的索引
POST /_aliases { "actions": [ { "add": { "index": "test*", "alias": "all_test_indices"} } ] }注意:在这种情况下,别名是一个时间点别名,它别名所有匹配的当前索引,并且在添加/删除与此模式匹配的新索引时,它不会自动更新。
7.带过滤器的别名
索引中需要字段
PUT /test1 { "mappings": { "type1": { "properties": { "user": { "type": "keyword" } } } } }过滤器由查询DSL定义,将对所有搜索、计数,
DeleteByQueryandMore LikeThis 操作。POST /_aliases{"actions": [{"add": {"index": "test1","alias": "alias2","filter": { "term": { "user": "kimchy"} }}}]}8.路由别名
路由值可以在别名定义中指定,别名定义可以与筛选器一起使用,以限制操作的碎片并避免其他不必要的碎片操作。
POST /_aliases{"actions": [{"add": {"index": "test","alias": "alias1","routing "/>1.知道单词分隔符1.1分析仪
在专家系统中,分析器由以下三个组件组成:
字符过滤器:字符过滤器,对文本进行字符过滤处理,如处理文本中的html标签字符。处理后交给分词器分词。一个分析器可以包含0个或更多的字符过滤器,其中许多是按配置顺序处理的。
分词器:分词器,用于对文本进行分词。分析器是必需的,并且只能包含一个标记器。
标记过滤器:一个术语过滤器,它过滤由标记器分隔的单词。如小写转换、停用词处理、同义词处理等。一个分析器可以包含0个或多个术语过滤器,这些过滤器按照配置的顺序进行过滤。
1.2如何测试单词分隔符
POST _analyze{"analyzer": "whitespace","text": "The quick brown fox."}POST _analyze{"tokenizer": "standard","filter": [ "lowercase", "asciifolding "/>立场:是什么字偏移:单词的偏移位置
2.内置字符过滤器
带字符过滤器
Html_strip:过滤Html标记并解码html实体,如&:。
映射字符过滤器
映射:用指定的字符串替换文本中的字符串。
模式替换字符过滤器
Pattern_replace:执行正则表达式替换。
2.1超文本标记语言带字符过滤器
POST _analyze{"tokenizer": "keyword","char_filter": [ "html_strip"],"text": "<p>I'm so <b>happy</b>!</p>"}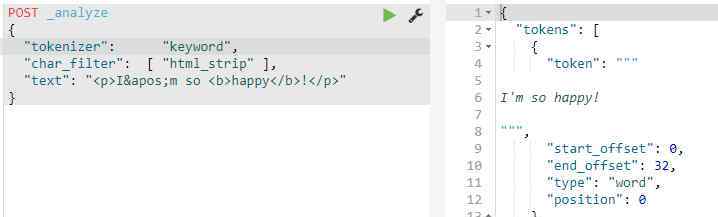
在索引中配置:
PUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "keyword","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "html_strip","escaped_tags": ["b"]}}}}}转义标记用于指定异常的标记。如果没有异常标签需要配置,这里就不用定制了,html_strip直接用在上面的my_analyzer中
测试:
POST my_index/_analyze{"analyzer": "my_analyzer","text": "<p>I'm so <b>happy</b>!</p>"}2.2映射字符过滤器
官网链接:https://www.elastic.co/guide/en/elastic搜索/参考/当前/分析-映射-charfilter.html
PUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "keyword","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "mapping "/>2.3模式替换字符过滤器官网链接:https://www.elastic.co/guide/en/elastic搜索/参考/当前/分析-模式-替换-charfilter.html
PUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "standard","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "pattern_replace","pattern": "(d+)-(?=d)","replacement": "$1_"}}}}}测试
POST my_index/_analyze{"analyzer": "my_analyzer","text": "My credit card is 123-456-789"}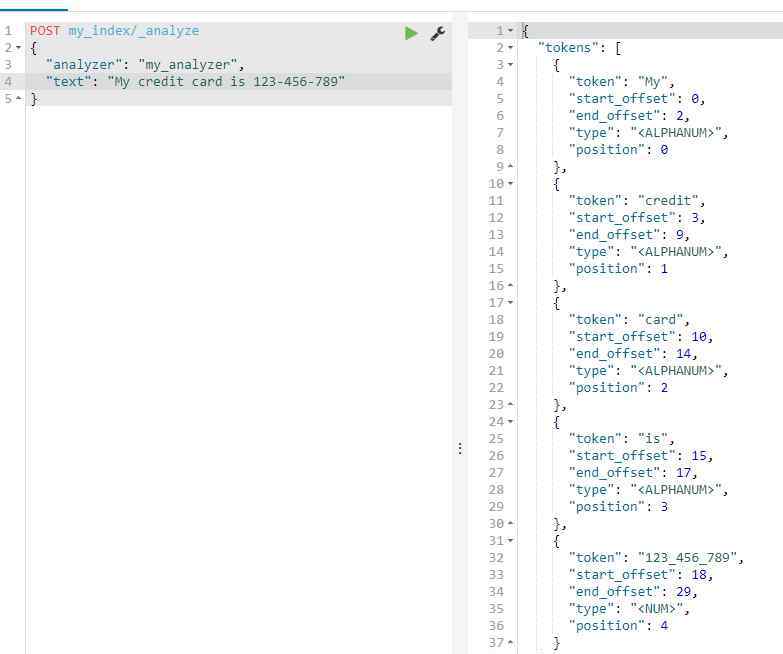
3.内置标记器
官方网站链接:https://www.elastic.co/guide/en/elastic搜索/参考/当前/分析-令牌化器
StandardTokenizerLetterTokenizerLowercaseTokenizerWhitespaceTokenizerUAXURL Email TokenizerClassicTokenizerThaiTokenizerNGramTokenizerEdgeNGram TokenizerKeywordTokenizerPatternTokenizerSimplePattern TokenizerSimplePattern Split TokenizerPathHierarchy Tokenizer分词器:ik _ smart,ik_max_word在集成中文分词器Ikanalyzer中提供
测试标记器
POST _analyze{"tokenizer": "standard","text": "张三说的确实在理"}POST _analyze{"tokenizer": "ik_smart","text": "张三说的确实在理"}4.内置令牌过滤器
ES内置了很多tokenfilters,详情:https://www . elastic . co/guide/en/elastosearch/reference/current/analysis-tokenizers . html。
小写令牌过滤器:小写到小写
停止令牌过滤器:停止单词过滤器
同义词标记过滤器:同义词过滤器
描述:中文分词器Ikanalyzer有自己的停用词过滤功能。
4.1同义词标记过滤器同义词过滤器
PUT /test_index{"settings": {"index": {"analysis": {"analyzer": {"my_ik_synonym": {"tokenizer": "ik_smart","filter": ["synonym"]}},"filter": {"synonym": {"type": "synonym",<!-- synonyms_path:指定同义词文件(相对config的位置)-->"synonyms_path": "analysis/synonym.txt"}}}}}}同义词定义格式
ES同义词格式支持solr和WordNet。
在analysis/同义词. txt中,以下同义词是以solr格式定义的
张三和李四
电饭锅,电饭锅= >;电饭煲
电脑= >:电脑,电脑
注意:
该文件必须是UTF 8编码
一行同义词,= >:表示形式标准化为
测试:通过例子的结果了解同义词的加工行为
POST test_index/_analyze{"analyzer": "my_ik_synonym","text": "张三说的确实在理"}POST test_index/_analyze{"analyzer": "my_ik_synonym","text": "我想买个电饭锅和一个电脑"}5.内置分析仪
官网链接:https://www.elastic.co/guide/en/elastic搜索/参考/当前/分析-分析师. html
StandardAnalyzerSimpleAnalyzerWhitespaceAnalyzerStopAnalyzerKeywordAnalyzerPatternAnalyzerLanguageAnalyzersFingerprintAnalyzer分析器:集成中文分词器中提供的IK _ SMART Ikanalyzer:IK _ SMART,ik_max_word
内置集成分析仪可以直接使用。如果它们不能满足我们的需求,我们可以结合字符过滤器、单词分隔符和术语过滤器来定义一个自定义分析器
5.1定制分析仪
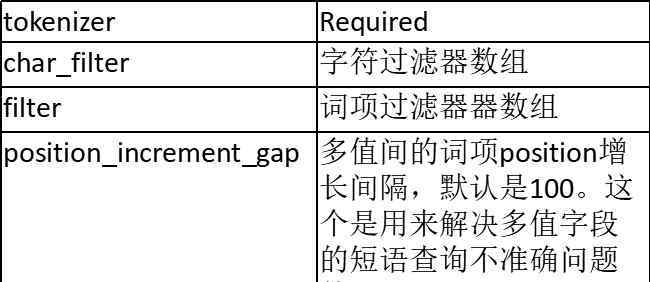
配置参数:
5.2为字段指定断字符
PUT my_index8/_mapping/_doc{"properties": {"title": {"type": "text","analyzer": "my_ik_analyzer"}}}如果该字段的查询需要使用不同的分析器,
PUT my_index8/_mapping/_doc{"properties": {"title": {"type": "text","analyzer": "my_ik_analyzer","search_analyzer": "other_analyzer"}}}测试结果
PUT my_index8/_doc/1{"title": "张三说的确实在理"}GET /my_index8/_search{"query": {"term": {"title": "张三"}}}5.3为索引定义默认单词分隔符
PUT /my_index10{"settings": {"analysis": {"analyzer": {"default": {"tokenizer": "ik_smart","filter": ["synonym"]}},"filter": {"synonym": {"type": "synonym","synonyms_path": "analysis/synonym.txt"}}}},"mappings": {"_doc": {"properties": {"title": {"type": "text"}}}}}测试结果:
PUT my_index10/_doc/1{"title": "张三说的确实在理"}GET /my_index10/_search{"query": {"term": {"title": "张三"}}}6.分析仪的使用顺序
我们可以为每个查询、字段和索引指定分词系统。
在索引阶段,专家系统将按以下顺序选择分词:
首先,选择字段映射定义中指定的分析器
如果字段定义中未指定分析器,则选择索引设置中定义的默认分析器。
如果在索引设置中没有定义默认分词,请使用标准分析器。
在查询阶段,ES会按照以下顺序选择分词:
The analyzer definedina full-text query.The search_analyzer definedinthe field mapping.The analyzer definedinthe field mapping.An analyzer named default_search inthe index settings.An analyzer named default inthe index settings.The standard analyzer.第三,文档管理
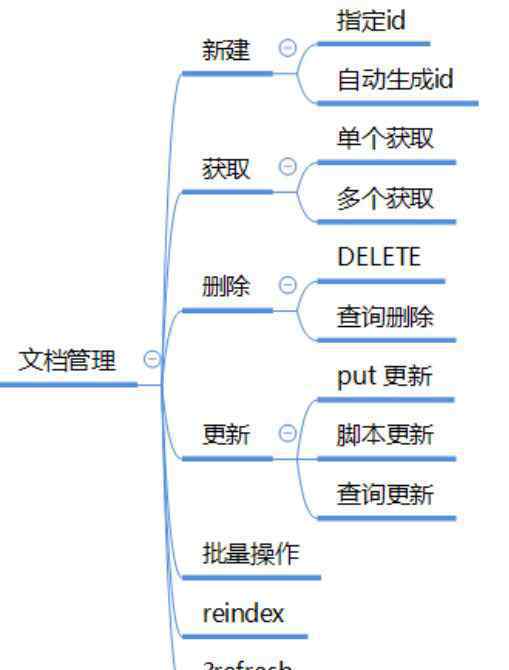
1.创建新文档
指定文档id,添加/修改
PUT twitter/_doc/1{"id": 1,"user": "kimchy","post_date": "2009-11-15T14:12:12","message": "trying out Elasticsearch"}添加,自动生成文档id
POST twitter/_doc/{"id": 1,"user": "kimchy","post_date": "2009-11-15T14:12:12","message": "trying out Elasticsearch"}返回结果描述:

2.获取单个文档
HEAD twitter/_doc/11GETtwitter/_doc/1不要获取文档的来源:
GETtwitter/_doc/1?_source=false获取文档的来源:
GET twitter/_doc/1/_source{"_index": "twitter","_type": "_doc","_id": "1","_version": 2,"found": true,"_source": {"id": 1,"user": "kimchy","post_date": "2009-11-15T14:12:12","message": "trying out Elasticsearch"}}获取存储字段
PUT twitter11{"mappings": {"_doc": {"properties": {"counter": {"type": "integer","store": false},"tags": {"type": "keyword","store": true} } } }}PUT twitter11/_doc/1{"counter": 1,"tags": ["red"]} GET twitter11/_doc/1?stored_fields=tags,counter
3.获取多个文档_管理
模式1:
GET /_mget{"docs": [{"_index": "twitter","_type": "_doc","_id": "1"},{"_index": "twitter","_type": "_doc","_id": "2""stored_fields": ["field3", "field4"]}]}模式2:
GET /twitter/_mget{"docs": [{"_type": "_doc","_id": "1"},{"_type": "_doc","_id": "2"}]}模式3:
GET /twitter/_doc/_mget{"docs": [{"_id": "1"},{"_id": "2"}]}模式4:
GET /twitter/_doc/_mget{"ids": ["1", "2"]}4.删除文档
指定要删除的文档id
DELETEtwitter/_doc/1使用版本控制删除
DELETEtwitter/_doc/1?version=1返回结果:
{"_shards": {"total": 2,"failed": 0,"successful": 2},"_index": "twitter","_type": "_doc","_id": "1","_version": 2,"_primary_term": 1,"_seq_no": 5,"result": "deleted"}查询删除
POST twitter/_delete_by_query{"query": {"match": {"message": "some message"}}}当文档中存在版本冲突时,不要放弃删除操作(记录冲突文档,继续删除其他复合查询的文档)
POST twitter/_doc/_delete_by_query?conflicts=proceed{"query": {"match_all": {}}}通过任务api查看查询删除任务
GET _tasks?detailed=true&actions=*/delete/byquery查询特定任务的状态
GET/_tasks/taskId:1取消任务
POST_tasks/task_id:1/_cancel5.更新文档
指定要修改的文档id
PUT twitter/_doc/1{"id": 1,"user": "kimchy","post_date": "2009-11-15T14:12:12","message": "trying out Elasticsearch"}乐观锁定的并发更新控制
PUT twitter/_doc/1?version=1{"id": 1,"user": "kimchy","post_date": "2009-11-15T14:12:12","message": "trying out Elasticsearch"}返回结果
{"_index": "twitter","_type": "_doc","_id": "1","_version": 3,"result": "updated","_shards": {"total": 3,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 3}6.ed update通过脚本更新文档
6.1准备文件
PUT uptest/_doc/1{"counter": 1,"tags": ["red"]}6.2文件1的计数器+4
POST uptest/_doc/1/_update{"": {"source": "ctx._source.counter += params.count","lang "/>1.集群组成第一个节点启动
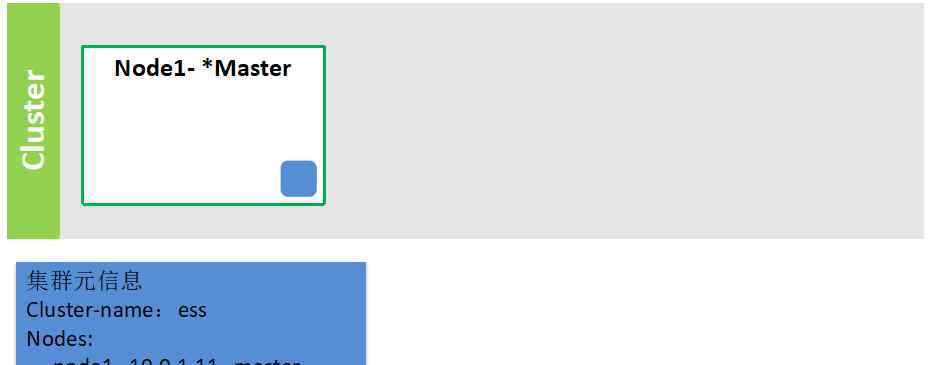
注意:必须首先启动主节点,它存储集群的元数据信息
节点2启动
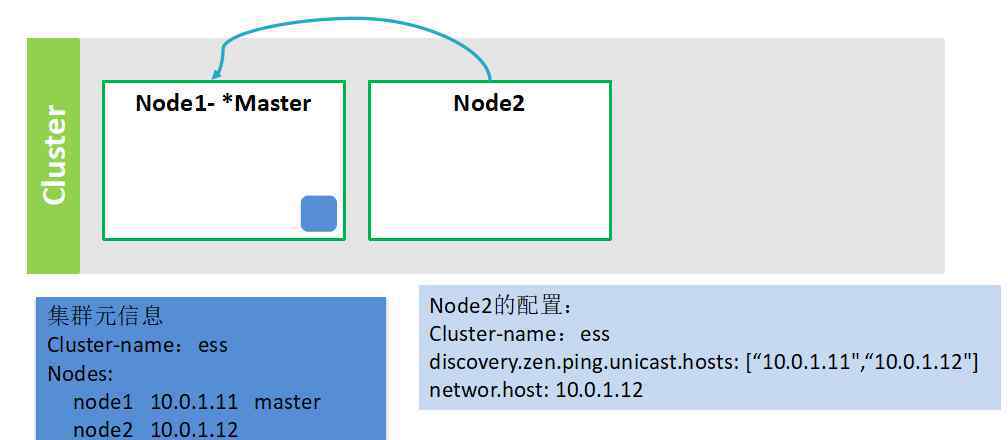
描述:
在Node2启动之前,它将配置Cluster-name:ess Cluster-name:ess,然后配置ip地址信息discovery . Zen . ping . unicast . hosts:[" 10 . 0 . 1 . 11 "、" 10.0.1.12"],并配置自己的ip地址network . host:10 . 0 . 1 . 12;
Node2启动的时候会找到主节点Node1,告诉Node1我要加入集群。主节点Node1收到请求后,会查看Node2是否满足加入集群的条件。如果是,它会将node2的ip地址添加到元信息中,然后广播给集群中的其他节点。
新节点加入并将最新的元信息发送给其他节点进行更新
节点3..NodeN连接
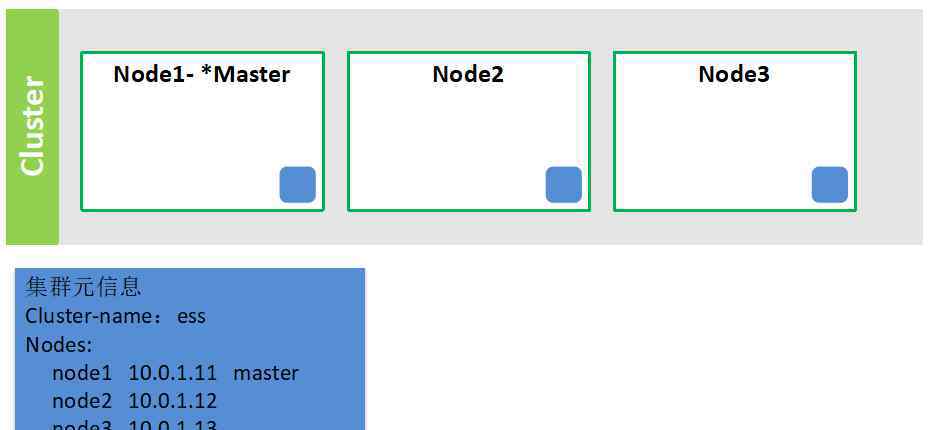
注意:集群中所有节点的元信息与主节点一致,因为一旦添加新节点,主节点将通知其他节点同步元信息。
2.在集群中创建索引的过程
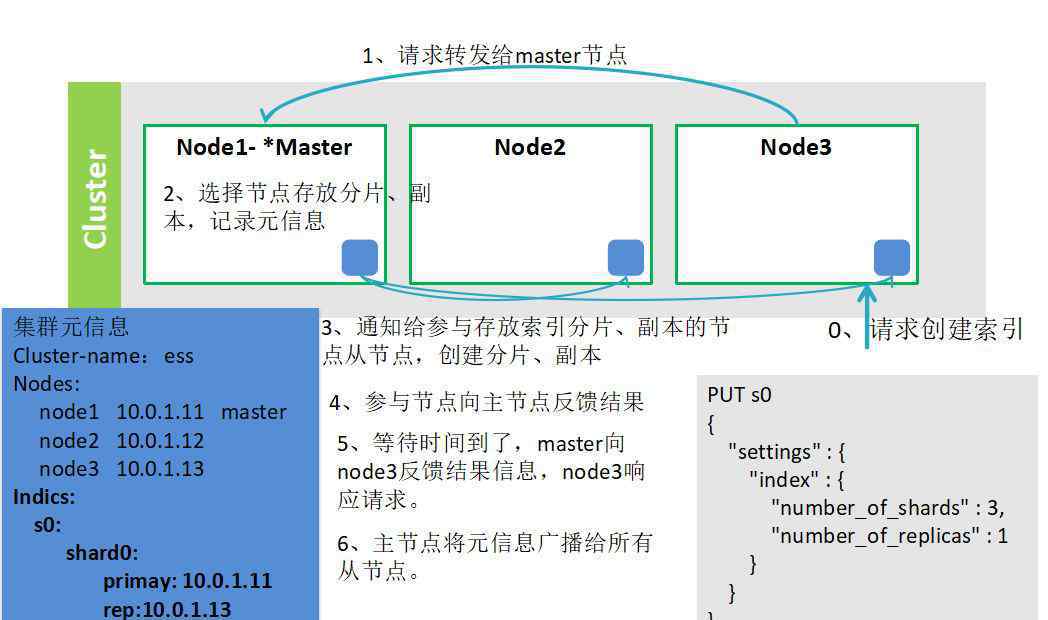
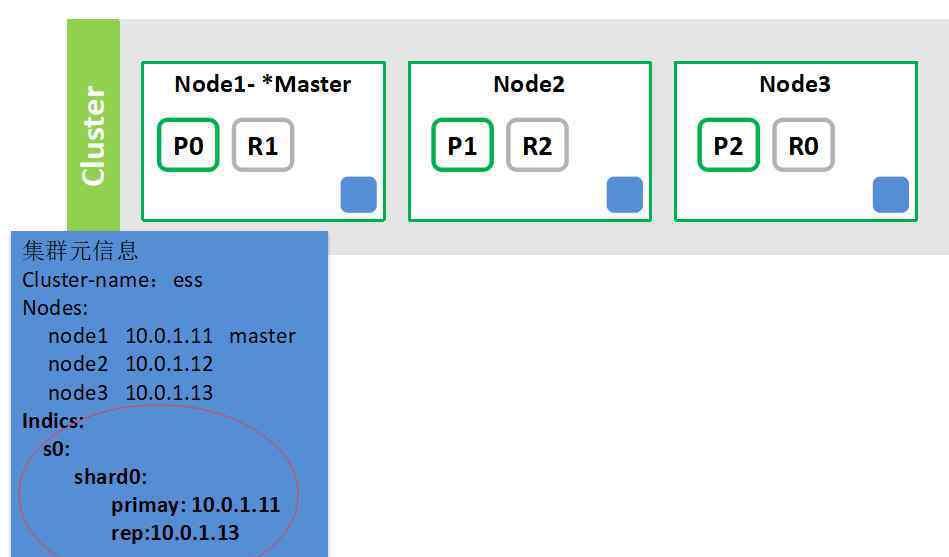
3.带索引的簇
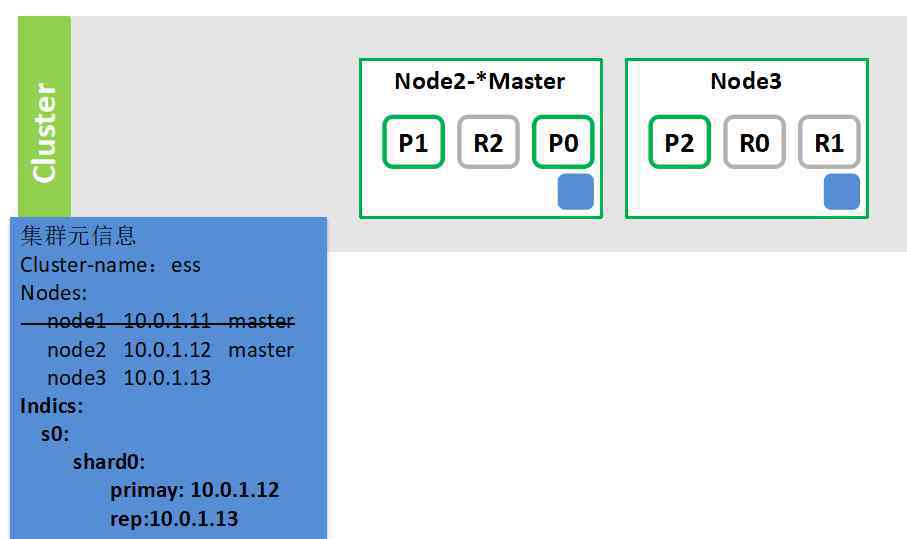
4.如果群集中的某个节点出现故障,将重新选择主节点。
5.为群集中的文档编制索引
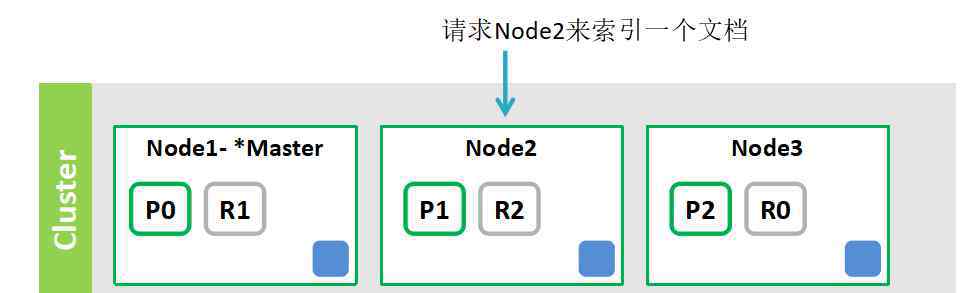
要索引文档:
1.节点2计算文档的路由值,以获得存储文档的片段(假设所选路由是片段0)。
2.将文档转发到片段0的主片段节点node 1(P0)。
3.node1对文档进行索引,并将文档同步索引到copy (R0)节点node3。
4.节点1将结果反馈给节点2
5.节点2响应
6.文件是如何传送的
文档应该保存在哪个切片上?
决定文档存储在哪个切片上是文档传送。在专家系统中,每个文档的存储切片通过以下计算获得:
shard= hash(routing) % number_of_primary_shards参数描述:
路由是用于哈希计算的路由值,默认值是文档id值。我们可以在索引文档时通过路由参数指定其他路由值
Number_of_primary_shards:创建索引时指定的主碎片数
POST twitter/_doc?routing=kimchy{"user": "kimchy","post_date": "2009-11-15T14:12:12","message": "trying out Elasticsearch"}路由参数(可以是多值的)可以用于索引、删除、更新和查询,以指定操作的切片。
创建索引时强制执行给定的路由值:
PUT my_index2{"mappings": {"_doc": {"_routing "/>搜索步骤:搜索索引s01.node2解析查询。
2.节点2向索引s0的分区/副本(R1、R2、R0)节点发送查询
3.每个节点执行查询并将结果发送到节点2
4.节点2合并结果并做出响应。
8.主节点的工作是什么?
1.存储集群的元信息,例如集群的名称和集群中的节点
2.转发创建索引和索引文档的请求
3.与其他节点通信,告诉其他节点有新节点加入等。
来源:https://www.cnblogs.com/leeSmall/p/9195782.html
在线数据和云小程序“DBASK”问答,可以随时解惑。欢迎了解和关注。

在线问答
立即回复
1.《elasticsearch入门教程 ElasticSearch最全详细使用教程:入门、索引管理、映射详解、索引别名、分词器、文档管理、路由、搜索详解》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《elasticsearch入门教程 ElasticSearch最全详细使用教程:入门、索引管理、映射详解、索引别名、分词器、文档管理、路由、搜索详解》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/caijing/1076847.html