本文是2018年5月11日在微软亚洲研究院举行的CVPR 2018中文论文展示研讨会第五届“切分、检测”会议的三篇论文的报告。
据AI科技评论,本文是2018年5月11日在微软亚洲研究院举行的CVPR 2018中文论文展示研讨会第五届“分割、检测”三篇论文的报告。
在第一份报告中,西北工业大学的戴教授介绍了他们在目标检测方面的工作。他们工作的新颖之处在于,他们将经济但不精确的传统手工方法应用到深度学习网络中,即将传统手工方法得到的结果视为预测结果+噪声,然后将预测模型和噪声模型训练为监督信号,从而实现了传统方法在深度学习时代的又一次春天。
在第二篇报告中,上塘科技的石建萍博士介绍了上塘科技在自主驾驶相关问题上的研究工作,包括场景理解、对象理解、视频理解和三维场景结构理解。其中,关于对象理解的工作在去年的COCO对象分割和对象识别中分别获得了第一名和第二名。
微软亚洲研究院研究员廖婧介绍了微软亚洲研究院在神经风格转换方面的相关工作,包括理论和应用两方面。在理论上,通过分析不同类型的以往风格转换的优缺点,他们设计了一个综合两种模式的优点并摒弃其缺点的模型。在应用方面,考虑到风格转换应用于VR/AR,如果两个视场之间的风格转换不一致,就会出现ghost,所以他们通过添加约束来解决这个问题。
人工智能技术评论:
CVPR 2018中文论文发表研讨会由微软亚洲研究院、清华大学媒体与网络技术部-微软重点实验室、上唐科技、中国计算机联合会计算机视觉委员会、中国图像与图形学会视觉大数据委员会联合举办。CVPR 2018论文的几十位作者在此论坛分享他们的最新研究和技术观点。研讨会包括6次会议、1次论坛和20多张海报。AI科技评论会为你详细报道。
CVPR 2018将于6月18日至22日在美国盐湖城举行。根据CVPR官方网站,今年的会议提交了3300多篇论文,其中979篇被录取;与去年的783篇论文相比,今年增加了近25%。
有关更多报告,请参考:
会议5:分段、检测
一、传统方法如何在深度学习时代盎然生机?论文:深度未保存显著性检测:多重噪声标记视角
主讲人:戴——西北工业大学教授
论文下载地址:
https://arxiv.org/abs/1803.10910
自2012年深度卷积网络出现并广泛成功引入其他领域以来,许多传统方法已经被抛弃到垃圾场。
因此,同时训练更好的显著性模型和相应的噪声模型。
3.实验结果
这里提到的基线有三条:第一条是使用有噪声的无监督显著性作为监督训练的基础事实;二是用平均无监督显著性作为监督训练的基础事实;第三种是目前的带标签数据的监督训练模型。对比结果如下:

同时,他们还比较了几种好的监督和非监督模型:
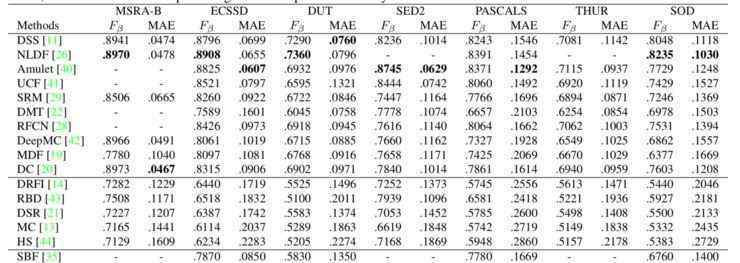
从以上两个结果可以看出,这种方法比大多数无监督模型好得多,与有监督学习相比也不差;最关键的问题是它是一个没有标注数据的端到端模型。
显然,这种新方法可以很容易地扩展到其他领域,包括语义分割。
二、自主驾驶的研究问题
报告标题:自动驾驶的有效场景理解
主讲人:石建萍商汤科技
论文下载地址:
场景理解:语义分段的上下文编码
对象理解:用于实例分割的路径聚合网络
视频理解:低延迟视频语义分割
3D场景结构理解:geonet:密集深度、光流、相机姿态的无监督学习
石建萍介绍了上唐科技2018年在CVPR发表的四篇文章,分别是自动驾驶研究中的场景理解、物体理解、视频理解和三维场景结构理解。
1.场景理解
关于场景的理解,上汤科技在2017年CVPR的一篇就业论文中做了相关的研究,他们在论文中提出了PSPNet模型,并通过金字塔池对场景进行了全局表示。
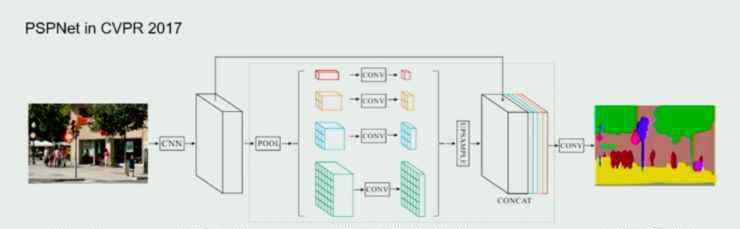
这种方法可以得到更好的场景信息,但金字塔汇集结构是人为设计的;它的计算还是比较重的。针对这两点,他们在今年的这篇文章中做了进一步的优化和加速。基本思路是用更灵活有效的模块代替人工设计的金字塔池。
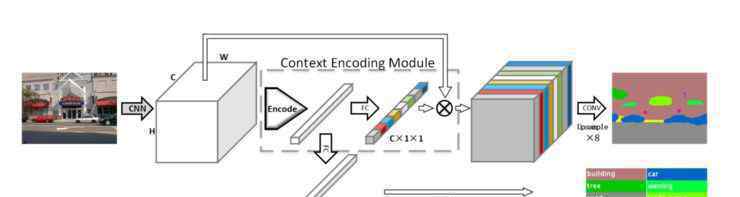
首先,他们把特征编码放入一个类似字典学习的表达式中。当输入图片通过CNN网络时,信息被编码到字典基中,场景的表达被学习到特征中。然后,将学习到的场景特征拉伸到图片的原始维度,从而获得场景的信息。
除了上下文编码模块,石建萍等人在模型中加入了一个损失,即语义编码损失,以此来了解某个类别是否存在于整个世界。添加这样的全局约束后,对那些较小类别的预测会更好。
总的来说,这种方法比去年的方法表现好一点,但石建萍仍然对此感到遗憾,因为她认为去年整个方向没有多大改善,所以有必要看看是否由于其他原因性能不能得到很大改善。
2.物理理解
这篇关于对象理解的文章是他们去年在COCO比赛中的作品,该比赛获得了对象分割第一名和对象检测第二名。

根据石建萍的说法,他们最初的目的是实现更高的目标,所以他们基于两个最好的框架,一个是FPNet,另一个是Mask-RCNN,并做了一系列的改进。
他们设计了如下网络:
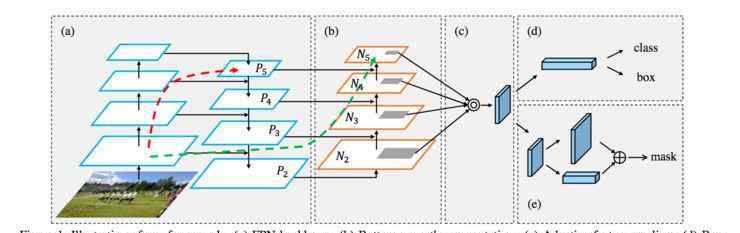
在这个网络中,我们仍然可以看到FPNet和Mask-RCNN的影子。改进如下:对FPNet的主干进行自下而上的增强;在FPNet中,每个尺度的建议是直接从相应的尺度中获得的,但是石建萍发现事实上其他尺度也会对这个尺度的建议有很大的帮助,所以他们加入了自适应特征学习的模块;在Mask-RCNN中,他们加入了全连通融合,可以保留更多的全局信息,进一步提高Mask。
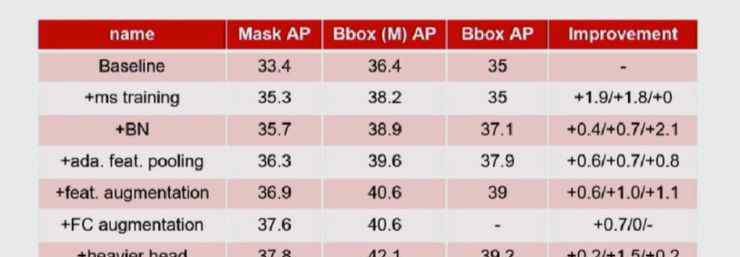
以下是添加每个模块后的性能改进:
3.视频理解
从实际场景中获得的数据大部分是视频数据,但仍然没有能很好利用视频的方案。在本文中,石建萍等人考虑了如何在保持良好性能的同时减少视频理解的延迟。
设计的网络如下图所示:
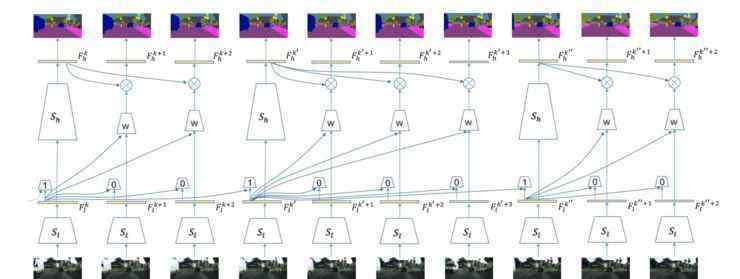
关键思想是给关键帧分配相对较高的计算量,而类似的帧相应地分配较少的计算量。在网络中,另一个关键点是将前一帧的特征转移到下一帧。
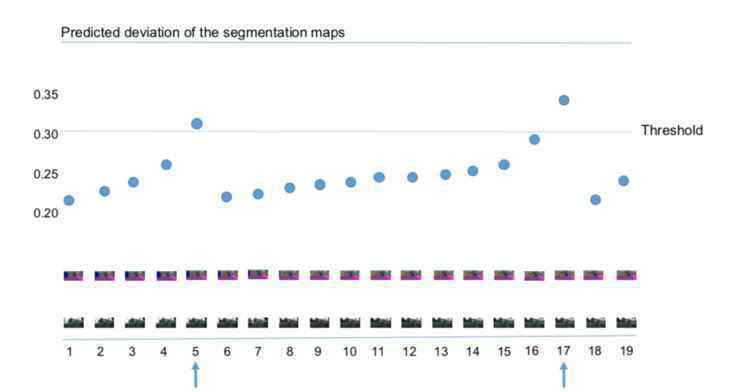
他们为特征设置阈值,以便自动选择关键帧。显然,这里的阈值也决定了计算的准确性;其实如果不是必须的,可以设置稍微高一点的门槛。此外,该方法还可以动态反映视频帧的变化。比如场景变化很快的时候,关键点会很快出现。
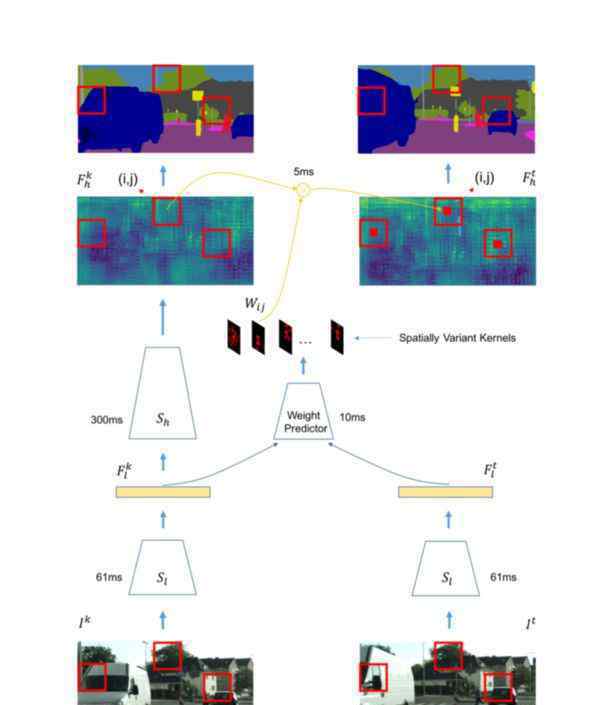
特征传递是通过底层特征学习相应的权重,这些权重与输入相关,可以通过这些权重实现特征的自动传递。还有一点就是他们还设计了一个调度策略,使得整个关键帧的计算可以延迟,即在非关键帧部分可以同时计算关键帧信息;通过这种调度方案,可以有效降低整个网络的时延。
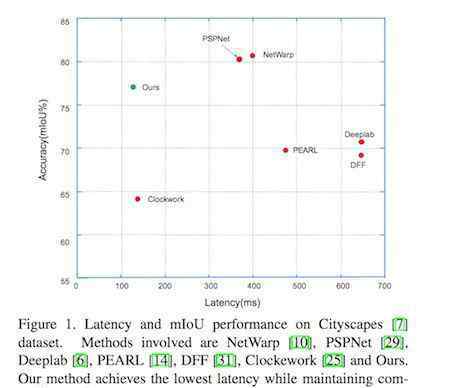
与其他方案相比,在做视频理解的时候,往往需要对每一帧都做很重的计算。本文提出的方案能够在保证较高性能的同时有效降低整个模型的延迟。
4.对三维场景结构的理解

以往关于理解三维场景结构的研究包括深度估计、光流估计和摄像机运动估计,但它们的每一部分都是一个独立的网络。因此,石建萍等人考虑是否有可能建立一个基于CNN的方案和几何约束的统一框架,同时得到更好的结果。
网络模型的结构如下图所示:

整个模型是一个无监督的网络,可以在没有任何外部信息的情况下训练深度、光流和摄像机运动。首先通过深度网络预测深度,得到深度图。另外,PoseNet用于预测相机运动;通过前后框架之间的信息。然后,将深度图和摄像机运动结合成刚性流,通过刚性流和最终流完成监督学习。
另一方面,考虑到会有一些刚性结构);在场景中;还有人,车等等。会因运动而改变。所以他们把两部分分开。前者可以通过相机运动轻松处理。对于对象运动,我们需要添加一个额外的约束。
整个目标函数如下,包括上述所有过程的损失:
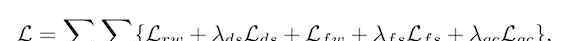
最后,我们可以看到,这种无监督的方法比以前的方法可以获得更可靠的深度和流量结果,并且还发现移动对象的效果更好。代码下载链接:http://github.com/yzcjtr/GeoNet
第三,从深度和广度上引入神经风格转换
报告标题:神经类型转移的扩展
主讲人:廖婧-微软亚洲研究院
论文下载:
1.具有深度特征重组的任意风格转换
2.立体神经风格转移
廖婧介绍了她的团队在CVPR 2018年出版的关于神经风格转移的两个可扩展的作品。一种是深度方向上的延伸,即从理论上对以往的NST进行分类总结,提出一种整合各方优势的方法。另一个是在广度方向的扩展,即NST在VR和AR领域的应用。他们提出了一个限制左右眼风格不一致的网络模型。
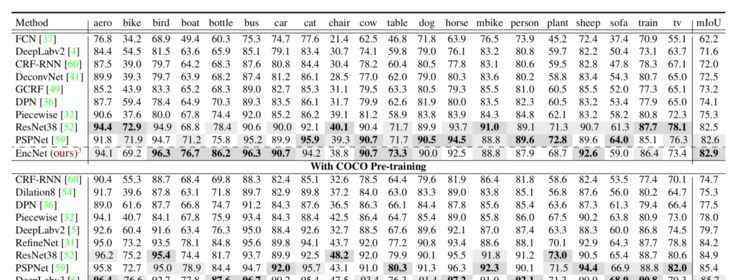
1.更深:分类和扩展
风格转换已成为目前的研究热点。神经风格转换是指当给定两幅图片时,一幅是风格图像,另一幅是内容图像,然后通过预先训练的神经网络将前者的风格转换为后者。这种方法通常依靠预先训练好的CNN,能很好的分解图像,在高层表现图像的内容,在低层表现图像的风格。
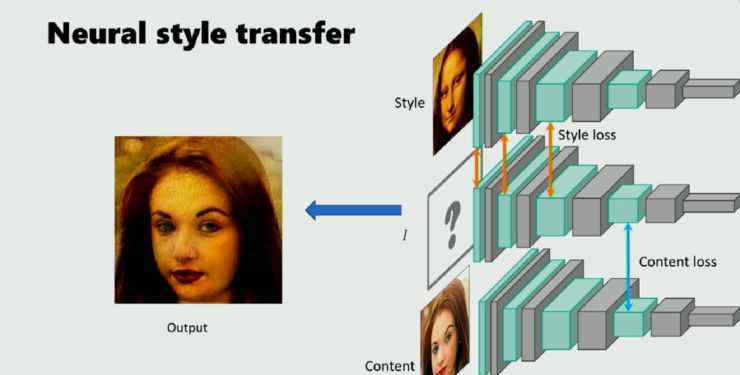
因此,希望这个图像的深层特征与高层次的内容图像和低层次的样式图像相似。这是神经风格转移的一般思路。
目前所有的神经风格转换都定义了两个损失函数,即内容损失和风格损失。这些神经风格变换模型的内容损失通常采用特征映射之间的L^2损失函数;但是不同的车型风格损失是不一样的。
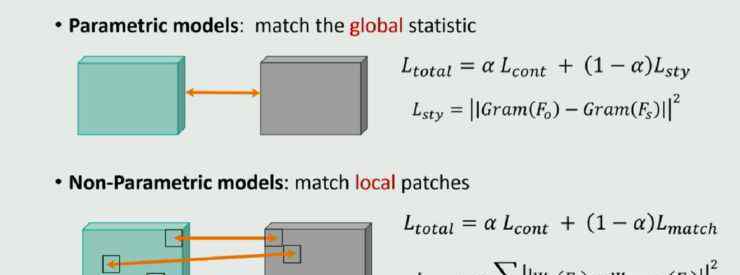
根据风格损失的不同,这些模型大致可以分为两类:一类是参数模型,要求生成的图片的特征图与待学习的风格图像的特征图在整体上具有统计相似性;另一种是非参数模型,希望最终生成的图片的特征图的局部面片全部来自于风格图像。所以可以说,前者定义了全局的相似性,后者定义了局部的相似性。
两种模式各有利弊。

参数化模型可以很好的学习风格的整体特征;但是localtexture的结构很难保证,会忽略空之间的一些布局。比如上图帆船的红色映射到海水。

另一方面,非参数模型可以很好地保证局部的结构,但很可能无法保证整体的模仿。另外,由于局部法没有限制如何使用补丁,可能会导致一两个补丁的大量出现,最终产生一个洗白神器。
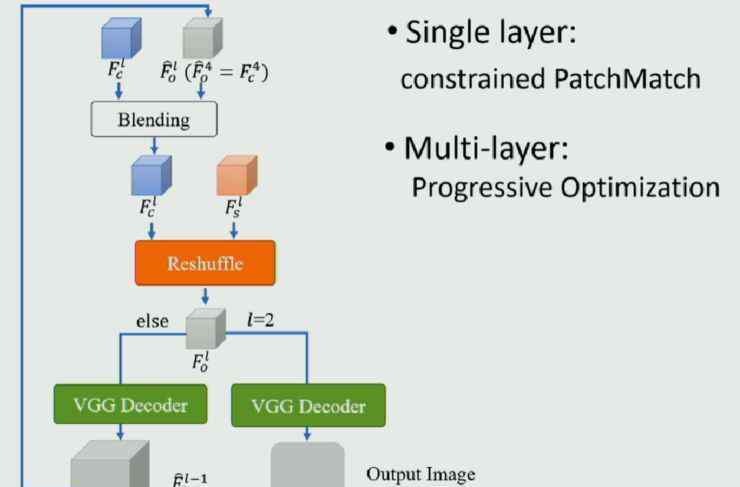
那么一个很自然的思考就是,你能不能想出一个办法,把两者的优点结合起来,同时避免各自的缺点?廖婧的团队提出了这样一种新颖的方法,他们称之为洗牌。

这种方法的核心思想史:重新排列风格图像的深层特征,即每个像素出现一次,但出现的位置与原始图像不同。这种重排的结果首先符合局部styleloss另一方面,目前全局损失主要采用对所有像素求和的gram矩阵法。这种方法不关心像素是如何分布的,所以即使像素的分布受到干扰,也不会影响全局丢失的结果。因此,这种刷新方法不仅符合在gram矩阵上定义的全局样式,还符合在patch上定义的局部样式。在论文中,他们对这个结果做了数学分析,这里就不展开了。
但是这种方法有一个严格的要求,就是每个像素只能出现一次。有时这种要求会有问题,如下图所示:

内容形象有两人四眼,风格形象只有一人两眼。如果只允许贴片使用一次,眼罩是不够的。因此,在实际操作中,廖婧等人定义了一个相对软的参数,用来控制所使用的补丁数量。当参数较大时,约束性较强,模型更接近全局法;相反,更接近于非参数局部的结果。通过设置参数,可以动态调整结果的偏差,自适应融合两侧特征。
模型框架如下图所示:
样式转换后的对比图如下:

从结果可以看出,这种刷新方法比参数化方法更能保留局部纹理,比非参数化方法更能再现Style的整体特征。
2.更广:VR/AR/AR眼睛款式一样
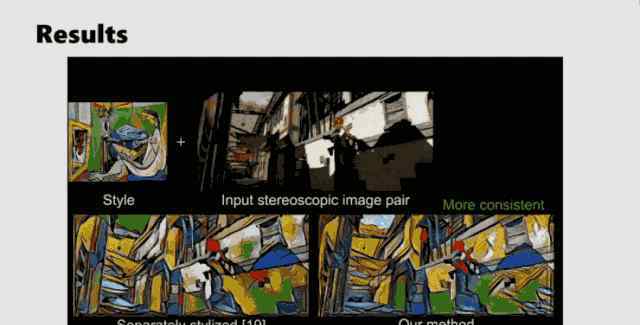
现在VR和AR都很流行,微软也生产了相关产品Hololens。在对VR/AR应用风格转换时,首先会出现一个问题,就是VR/AR设备有左眼视图和右眼视图。如果两个视图的图像分别转换,即两者的转换没有相关性,那么左右眼看到的转换后的风格图像就会不一致,拍摄VR/AR时会出现各种鬼影,让用户无法很好的感受到3D风格结构。

解决这个问题的关键是在风格转换的过程中加入左右眼的约束,称为视差约束。
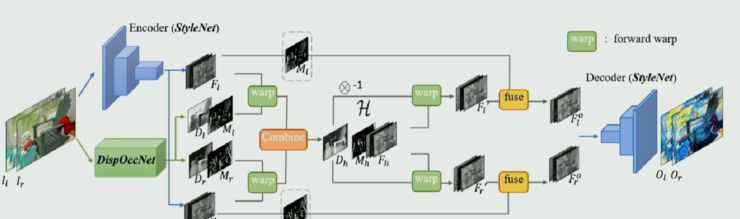
廖婧的团队定义了一个新的网络,大致分为三个部分。

第一种是图像风格转换网络,只要能分为编码器和解码器,可以是市面上任何一种图像风格转换网络。

其次,它是一个视差遮挡网络,以左右眼的图像作为输入,输出两帧图像之间的视差及其置信度。
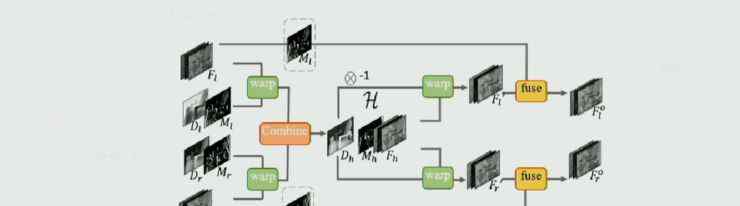
在中间部分,根据视差进行特征增强,这意味着左眼和右眼向中间对称扭曲,然后在中间域进行增强,得到可信的结果,然后分别投影到左眼和右眼。
添加约束后的效果显示在动画中:
此时,
和
但是!
审批后工作人员会通过微信联系你并出票)
同时,
1.《broader CVPR 2018 中国论文分享会之「分割与检测」》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《broader CVPR 2018 中国论文分享会之「分割与检测」》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/yule/1701210.html