梦晨 发自 凹非寺量子位 报道 | 公众号 QbitAI
AlphaGo在围棋界大杀四方时就有人不服:有本事让AI斗地主试试?
试试就试试。
快手团队开发的斗地主AI命名为DouZero,意思是像AlphaZero一样从零开始训练,不需要加入任何人类知识。
只用4个GPU,短短几天的训练时间,就在Botzone排行榜上的344个斗地主AI中排名第一。
而且还有在线试玩(链接在文章最后),手机也能运行。
在线试玩中演示的是三人斗地主,玩家可以选择扮演地主、地主的上家或下家。
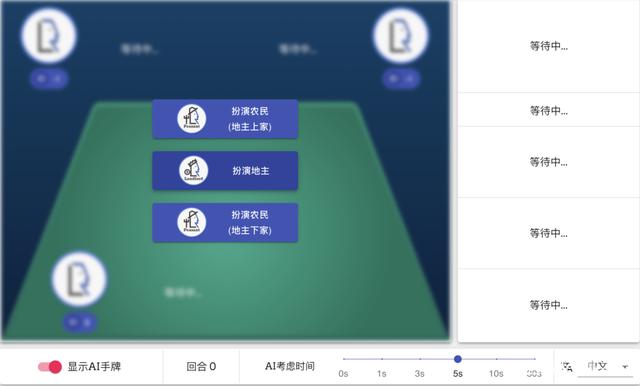
选择当地主来玩玩看,可以打开显示AI手牌功能,更容易观察AI决策过程。另外可以设置AI考虑时间,默认是3秒。
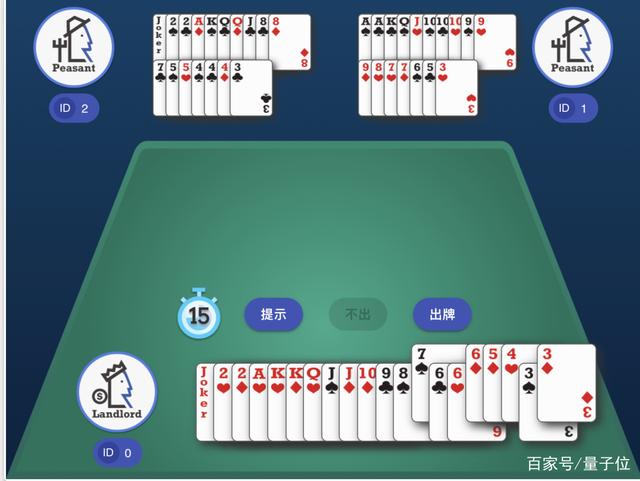
在AI的回合,会显示面临的决策和每种打法的预测胜率。
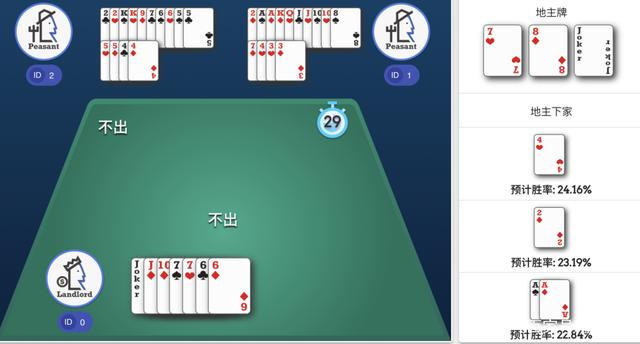
有时可以看到AI并不是简单的选择当前胜率最高的打法,而是有更全局的考虑。
斗地主对AI来说,很难
从博弈论的角度看,斗地主是“不完全信息博弈”。
围棋是所有棋子都摆在棋盘上,对弈双方都能看到的完全信息博弈。
而斗地主每个玩家都看不到其他人的手牌,对于AI来说更有挑战性。

在棋牌类游戏中,虽然斗地主的信息集的大小和数量不如麻将,但行动空间有10^4,与德州扑克相当,而大多数强化学习模型只能处理很小的行动空间。
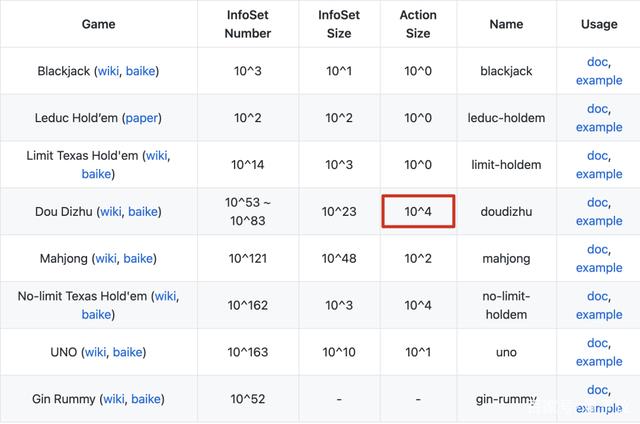
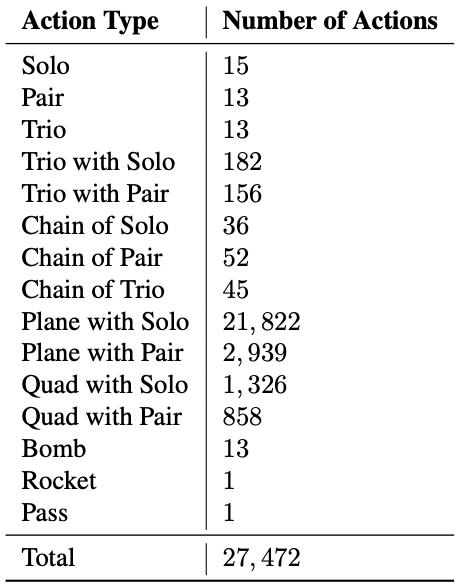
斗地主的所有牌型总共有27472种可能。
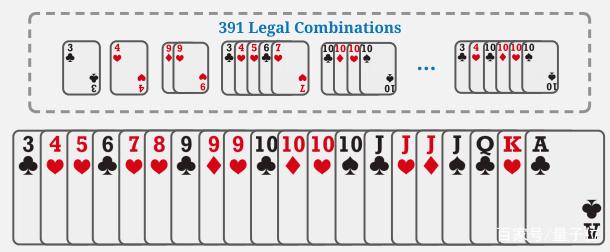
像下图的手牌就有391种打法。
且斗地主的行动不容易被抽象化,使搜索的计算成本很高,像Deep Q-Learning和A3C等强化学习模型都只有不到20%的胜率。
另外作为不对称游戏,几个农民要在沟通手段有限的情况下合作并与地主对抗。
像扑克游戏中最流行的“反事实后悔最小化”(Counterfactual Regret Minimization)算法,就不擅长对这种竞争和合作建模。

全局、农民和地主网络并行学习
首先将手牌状态编码成4x15的独热(one-hot)矩阵,也就是15种牌每种最多能拿到4张。
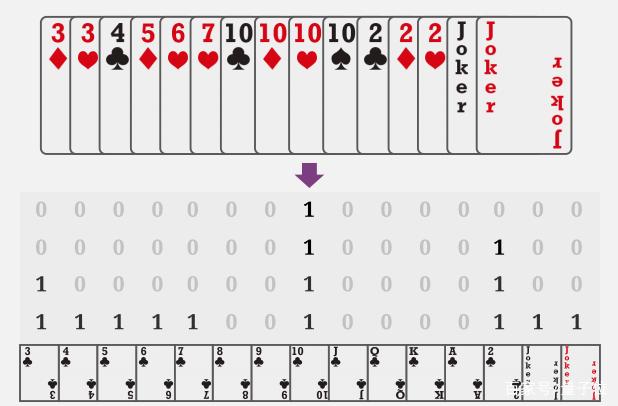
DouZero是在Deep Q-Learning的基础上进行改进。
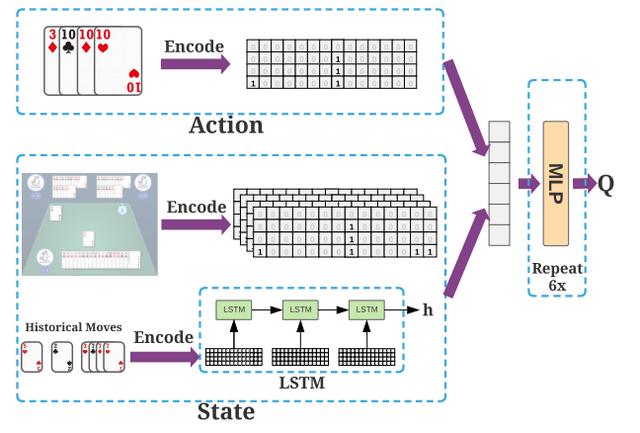
使用LSTM(长短期记忆神经网络)编码历史出牌,独热矩阵编码预测的牌局和当前手牌,最终用6层,隐藏层维度为512的MLP(多层感知机)算出Q值,得出打法。
除了“学习者”全局网络以外,还用3个“角色”网络分别作为地主、地主的上家和下家进行并行学习。全局和本地网络之间通过共享缓冲区定期通信。
 △学习者和角色的算法
△学习者和角色的算法DouZero在48个内核和4个1080Ti的一台服务器上训练10天击败了之前的冠军,成为最强斗地主AI。
下一步,加强AI间的协作
对于之后的工作,DouZero团队提出了几个方向:
一是尝试用ResNet等CNN网络来代替LSTM。
以及在强化学习中尝试Off-Policy学习,将目标策略和行为策略分开以提高训练效率。
最后还要明确的对农民间合作进行建模。好家伙,以后AI也会给队友倒卡布奇诺了。

柯洁在围棋被AlphaGO击败以后,2019年参加了斗地主锦标赛获得了冠军。
不知道会不会有AI“追杀”过来继续挑战他。
在线试玩:https://www.douzero.org
GitHub项目地址:https://github.com/kwai/DouZero
论文地址:https://arxiv.org/pdf/2106.06135.pdf
参考链接:[1]https://www.sohu.com/a/285835432_498635
1.《量子位_AI杀入斗地主 快手DouZero对标AlphaZero 干掉344个AI获第一》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《量子位_AI杀入斗地主 快手DouZero对标AlphaZero 干掉344个AI获第一》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/gl/1843536.html