机器的心脏被释放
不久前,AV视频变脸明星DeepFake走红。这篇文章将教你如何一步一步地改变你的脸。
如果这是你第一次听说DeepFake,一定要点击上面的视频,亲身感受一下尼古拉斯的脸是如何占据世界上每一部电影的。
项目实战
我们在视频中是如何变脸的?
因为视频是一个连续的画面,我们只需要切换每张画面中的人脸,就可以得到一个新的变了脸的视频。那么如何在一个视频中切换画面呢?这就需要我们先找到视频中的人脸,然后切换人脸。我们会发现变脸的问题可以分解成以下几个过程。
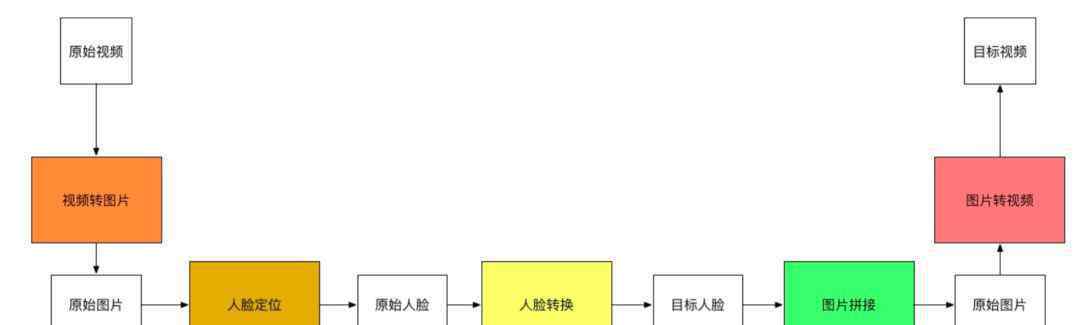
所以后续我们会按照这五个步骤来做。
视频到图像
FFmpeg
FFmpeg提供了一个用于处理音频、视频、字幕和相关源数据的工具库。核心库包括:
libavcodec 提供了处理编码的能力libavformat 实现了流协议、容器类型、基本的 I/O 访问libavutil 包括哈希、解压缩等多样的功能libavfilter 提供了链式修改音频和视频的能力libavdevice 提供了对设备访问的抽象libswresample 实现了混音等能力libswscale 实现了颜色和尺度变换的能力主要向外界提供三种工具:
ffmpeg 用来处理多媒体内容ffplay 是一个极简的播放器ffprobe 是多媒体内容的分析工具所以我们的视频转图片功能可以通过下面的命令来实现。
ffmpeg-I clip name-VF fps = frame rate-qscale:v 2 " imagename % 04d . jpg "/>
(来源:DLIB、OpenCV和Python的面部标志)
这个算法的效果如上所示。它将人脸分为以下几个区域:
眼睛 (左/右)眉毛 (左/右)鼻子嘴下巴基于这些标记,我们不仅可以改变我们的脸,还可以检测我们的脸的特定形状和眨眼状态。例如,我们可以连接这些点来获得更多的特征。

(来源:实时人脸姿态估计)
寻找面部标志是一个预测问题。输入是图片和感兴趣区域,输出是感兴趣区域的关键点。
HOG是怎么找到脸的?这是一个通用的检测算法:
从数据集中找到正样本,并且计算 HOG 描述从数据集中找到负样本,并且计算 HOG 描述基于 HOG 的描述使用分类算法在负样本上在不同的起点和尺度进行分类,并且找到误判的 HOG基于上一步的负样本,对模型进行重新的训练这里有个问题,HOG的描述怎么算?我们可以计算每个点的亮度,然后将每个点表示为指向更暗方向的向量。如下图所示:

(来源:机器学习很好玩!第四部分:深度学习的现代人脸识别)

(来源:机器学习很好玩!第四部分:深度学习的现代人脸识别)
我们为什么要这么做?因为每个点的绝对值都会受到环境的影响,但是相对值是相对稳定的。因此,我们可以通过梯度变化的表达来准备高质量的数据。当然,我们可以进一步聚合相邻点,产生更具代表性的数据。
现在你可以测试了
首先在新的图片上基于不同的起点和尺度寻找可行的区间;基于非极大抑制的方法来减少冗余和重复的,下图就是一个有冗余和去除冗余的情况,这个方法说白了就是找一个最大概率的矩阵去覆盖掉和它过于重合的矩阵,并且不断重复这个过程。
(来源:方向梯度直方图和目标检测)
有了轮廓,我们就能找到面部标志。寻找面部标记的算法是基于论文“用回归树集合进行一百万张面部对齐”。简而言之,它使用标记的训练集来训练回归树的组合进行预测。

(来源:回归树集合的1毫秒面对齐)
在此基础上,可以对这68点进行标注。

(来源:DLIB、OpenCV和Python的面部标志)
基于人脸68个标记的坐标,可以计算出人脸的度数,进而可以挑出拉直的人脸。但是dlib需要全脸识别,会减少我们的样本集和一些特定的样本场景。同时,由于人脸尺寸为64*64像素,所以需要处理清晰度的问题。
另一种方法是利用CNN训练一个人脸识别模型。CNN可以检测更多的学位,但是需要更多的资源,可能会在大文件上失败。
数据准备
我们的目标是将原始人脸转换成目标人脸,所以我们需要收集原始人脸和目标人脸的图片。如果选择名人,可以直接用Google image得到想要的图片。虽然视频中的图片也可以使用,但也可以采集各种数据。当然,我使用我和我妻子的照片,所以我可以直接从我们的照片导出它们。生成人脸数据时,最好仔细检查,避免不合适的人脸或其他东西出现在你的训练集中。
extract.py
Deepfake用来定位人脸的算法如下:
Importcv2 #开源计算机视觉库
Frompathlib importPath #提供面向对象的文件访问
Fromtqdm importtqdm #提供进度条显示功能
Importos #提供与操作系统相关的访问
Importnumpy asnp #提供与科学计算相关的功能
from lib . cliimportdirectory processor,rotate _ image #处理一个目录的文件,然后将它们保存在一个新目录中;旋转图片实际上是在实用程序中
从lib.utils importget_folder #中获取一个文件夹,如果它不存在,则创建它。
来自lib。多线程导入pool _ process #多进程并发计算
来自lib。detect _ blur import is _ blur #判断图片是否模糊
来自插件。pluginloader Importpluginloader #加载相应的算法
分类追踪数据(目录处理器):#从训练集中提取头像
defcreate_parser(self,subparser,command,deion):
self . optional _ arguments = self . get _ optional _ arguments()
self . parser = submisser . add _ parser(
命令,
help= "从图片中提取人脸。",
deion=deion,
epilog= "问题和反馈:
https://github.com/deepfakes/faceswap-playground"
)
#省略参数配置
defprocess(自我):
提取器名称=“对齐#”对应于提取对齐
self . extractor = PluginLoader . get _ extractor(extractor _ name)()
processes = self . arguments . processes
尝试:
ifprocesses!= 1: #多进程处理图片
files = list(self.read_directory())
forfilename,faces int qdm(pool _ process(self . process Files,files,processes=processes),total = len(files)):
self.num_faces_detected += 1
self . faces _ detected[OS . path . base name(filename)]= faces
Else: #单进程处理图片
for filename int qdm(self . read _ directory()):
尝试:
image = cv2.imread(文件名)
self . faces _ detected[OS . path . basename(文件名)] = self.handleImage(图像,文件名)
例外情况:
ifself.arguments.verbose:
打印('无法从图像提取:{}。原因:{} '。格式(文件名,e))
及格
最后:
self.write_alignments()
Defprocessfiles (self,filename): #处理单个图片的函数
尝试:
image = cv2.imread(文件名)
returnfilename,self.handleImage(图像,文件名)
例外情况:
ifself.arguments.verbose:
打印('无法从图像提取:{}。原因:{} '。格式(文件名,e))
及格
returnfilename,[]
DefgetRotatedImageFaces(自身,图像,角度):#获取以固定角度旋转的图片的面
旋转图像=旋转图像(图像,角度)
face = self . get _ faces(rotated _ image,rotation=angle)
rotated_faces = [(idx,face) foridx,face infaces]
returnrotated_faces,rotated_image
定义旋转体(自我,图像):#获得一系列旋转的面
''通过rotation_angles旋转图像以尝试找到一张脸'''
forangle inself.rotation_angles:
旋转的面,旋转的图像=自。获取旋转的图像面(图像,角度)
iflen(旋转面)>;0:
ifself.arguments.verbose:
通过旋转图像{}度打印('找到的面')。格式(角度))
破裂
returnrotated_faces,rotated_image
defhandleImage(自身、图像、文件名):
faces = self.get_faces(图像)
process_faces = [(idx,face) foridx,face infaces]
#未找到人脸,尝试旋转图片
if self . rotation _ angles is not none and len(process _ faces)= 0:
process_faces,image = self.imageRotator(image)
rvals = []
foridx,face inprocess_faces:
#标记面部
if self . arguments . debug _ landmarks:
for(x,y)inface . landmarksaxy():
cv2.circle(图像,(x,y),2,(0,0,255),-1)
resized_image,t _ mat = self . extractor . extract(image,face,256,self.arguments.align_eyes)
output _ file = get _ folder(self . output _ dir)/Path(filename)。阻止
#检查图片是否模糊
if self . arguments . blur _ thresh is notnone:
aligned _ landmark = self . extractor . transform _ points(face . landmarksaxy(),t_mat,256,48)
feature _ mask = self . extractor . get _ feature _ mask(aligned _ landmarks/256,256,48)
feature _ mask = cv2 . blur(feature _ mask,(10,10))
isolated _ face = cv2 . multiply(feature _ mask,resized_image.astype(float))。astype(np.uint8)
模糊,focus _ measure = is _ fuzzy(isolated _ face,self.arguments.blur_thresh)
# print(“{}焦点度量:{ }”。格式(路径(文件名)。stem,focus_measure))
# cv2.imshow("孤立脸",孤立脸)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
如果模糊:
print(“{}”的焦点度量{ }低于模糊阈值,移至“模糊”。格式(路径(文件名)。stem,focus_measure))
output_file = get_folder(路径(self . output _ dir)/Path(" further "))/Path(文件名)。阻止
通过cv2.imwrite ('{} _ {} {} '生成新图片。格式(str (output _ file)、str (idx)、路径(文件名)。后缀),调整大小_图像)#
f = {
“r”:face . r,
“x”:face . x,
“w”:face . w,
“y”:脸. y,
“h”:脸. h,
【landmarksXY】:face . landmarksXY()
}
rvals.append(f)
returnrvals
注意,基于特征标签的算法对于倾斜面是无效的,也可以引入CNN。
面部转换
人脸变换的基本原理是什么?假设你连续盯着一个人的视频看100个小时,然后给你看另一个人的照片,然后让你凭记忆画出刚才的照片,你一定会像第一个人一样画出来。
我们使用的模型是自动编码器。有趣的是,这个模型所做的是在原始图像的基础上重新生成原始图像。Autoencoder的编码器压缩图片,解码器还原图片。一个例子如下:
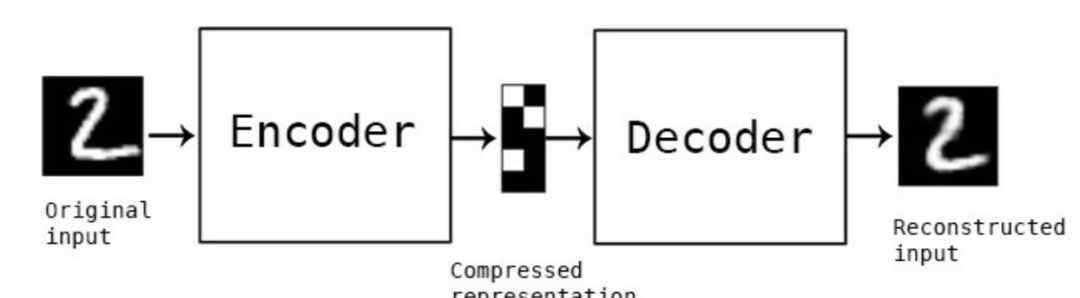
(资料来源:在喀拉斯建立自动编码器)
在此基础上,即使我们输入另一个人脸,也会被Autoencoder编码成与原人脸相似的人脸。
为了提高我们的最终效果,我们还需要学习与人脸共性和人脸特征相关的属性。因此,我们对所有人脸使用统一的编码器。这个编码器的目的是学习人脸的共性;然后,我们对每张脸都有一个单独的解码器。这个解码器是学习脸的个性。这样,当你用B的脸通过编码器,然后用A的解码器,你会得到一个和B的表情一致但A的脸。
该过程由以下公式表示:
' X' =解码器(编码器(洗牌(X)))
损失= L1损失(X'-X)
A' = Decoder_A(编码器(Shuffle(A)))
损失_ A =损失(A'-A)
' B' = Decoder_B(编码器(Shuffle(B)))
损失_ B =损失(B'-B)
具体来说,在训练过程中,我们输入A的图片,通过编码器和解码器还原A的脸;然后我们输入B的图片,通过相同的编码器但是不同的解码器还原B的脸。重复这个过程,直到损失降到一个阈值。在模型的训练过程中,我建议把损失降到0.02,这样效果会更好。
这里用的是比较标准的建模方法。值得注意的是,作者通过添加PixelShuffler()的功能来扭曲图像,增加了学习的难度,使模型达到了最终的效果。仔细想想这背后的原因。如果你一直做简单的问题,你就不能解决困难的问题。不过我只需要在题目上做一些变动,就足以让你成功了。
因为在建模中用原始图像A的失真来还原A,在应用中用B来还原A,所以失真的方式会对最终结果产生很大的影响。因此,如何选择更好的失真公式也是一个重要的问题。
我们的图片合并的时候会出现一个难题,如何保证效果,防止图片晃动。因此,我们需要引入相关算法来处理这些情况。所以我们可以知道,一个看似直接的人脸转换算法,在实际操作中需要考虑各种特殊情况,这才是真正的接地气。
train.py
以下是用于训练的算法逻辑:
Importcv2 #开源计算机视觉库
Importnumpy #提供与科学计算相关的功能
Importtime #提供与时间相关的功能
Importthreading #提供多线程相关功能
来自lib。utils import get _ image _ paths,get _ folder #获取目录中的图片;获取一个文件夹,如果它不存在,就创建它
fromlib.cli importFullPaths,argparse,os,sys
来自插件。pluginloader Importpluginloader #加载相应的算法
tf =无
set_session =无
Defimport_tensorflow_keras():#需要时加载tensorflow和keras模块
'''仅当需要时才导入张量流和keras集_会话模块'''
globaltf
globalset_session
iftf isNoneorset _ session isNone:
importtensorflow
Importkeras。后端. tensorflow _后端# keras依赖底层tensorflow来实现特定的操作
tf =张量流
set_session = keras .后端. tensorflow _后端. set_session
分类训练处理器(对象):#训练器
参数=无
Def _ _ init _ _ (self,subparser,command,deion =' default'): #初始化教练
self . argument _ list = self . get _ argument _ list()
self . optional _ arguments = self . get _ optional _ arguments()
self.parse_arguments(deion,subparser,command)
自锁=穿线。锁定()
defprocess_arguments(self,arguments):
self.arguments =参数
打印(“型号A目录:{}”。格式(self.arguments.input_A))
打印(“型号B目录:{}”。格式(self.arguments.input_B))
打印(“培训数据目录:{}”。格式(self.arguments.model_dir))
self.process()
#省略参数配置
@staticmethod
Defget_optional_arguments():#创建一个数组来保存参数
''将参数放在列表中,以便可以从argparse和gui访问它们'''
#为自定义参数覆盖此选项
参数列表= []
返回文档列表(_ l)
defparse_arguments(self,deion,subparser,command):
parser = subparser.add _ parser(
命令,
help= "这个命令为A和b两个面训练模型。
deion=deion,
epilog= "问题和反馈:
https://github.com/deepfakes/faceswap-playground")
foroption inself.argument_list:
args = option['opts']
kwargs = { key:option[key]forkey in operation . keys()if key!= 'opts'}
parser.add_argument(*args,**kwargs)
parser = self . add _ optional _ arguments(parser)
parser . set _ defaults(func = self . process _ arguments)
def addd _ optional _ arguments(self,parser):
for option in self . optional _ arguments:
args = option['opts']
kwargs = { key:option[key]forkey in operation . keys()if key!= 'opts'}
parser.add_argument(*args,**kwargs)
返回分析器
定义过程(自我):#具体执行
自我停止=假
self.save_now = False
Thr =线程。线程(target = self。processthread,args =(),kwargs = {}) #线程执行
thr.start()
ifself.arguments.preview:
打印(“使用实时预览”)
同时:
尝试:
withself.lock:
forname,image in self . preview _ buffer . items():
cv2.imshow(名称,图像)
key = cv2.waitKey(1000)
if key = = order(' n ')orkey = = order(' r '):
破裂
if key = = order(' s '):
自我。现在保存=真
例外键盘中断:
破裂
else:
尝试:
input() # TODO如何捕捉特定的键而不是Enter?
#没有好的多平台解决方案:https://stack overflow . com/questions/3523174/raw-input-in-python-with-press-enter
例外键盘中断:
及格
打印(“要求退出!教练将完成当前周期,保存模型并退出(根据您的训练速度,可能需要几秒钟)。如果你现在想干掉它,按Ctrl + c”)
自我停止=真
thr.join() #等待线程结束
defprocessThread(自):
尝试:
ifself.arguments.allow_growth:
self.set_tf_allow_growth()
打印('正在加载数据,这可能需要一段时间...')#加载数据
#这样您就可以为trainer输入不区分大小写的值
培训师= self.arguments .培训师
trainer = " LowMem " if trainer . lower()= = " LowMem " else trainer
Model = pluginloader。get _ model(trainer)(get _ folder(self。arguments.model _ dir),self。arguments.gpus) #读取模型
模型加载(交换=假)
images _ a = get _ image _ path(self。arguments.input _ a) #图片a
images _ b = get _ image _ path(self。arguments.input _ b) #图片b
trainer = pluginloader . get _ trainer(trainer)#创建一个教练
培训师=培训师(模型,images _ a,images _ b,self。arguments.batch _ size,self。arguments.perceptual _ loss) #设置教练参数
打印('开始。按“回车”停止训练并保存模型)
前传范围(0,self . arguments . epoch):
save _ iteration = epoch % self . arguments . save _ interval = = 0
火车。train _ one _ step (epoch,self。显示if (save _ iteration或self。立即保存)其他无)#
ifsave_iteration:
model.save_weights()
ifself.stop:
破裂
ifself.save_now:
model.save_weights()
self.save_now = False
model.save_weights()
退出(0)
例外键盘中断:
尝试:
model.save_weights()
例外键盘中断:
打印('保存模型重量已被取消!')
退出(0)
例外情况:
raisee
出口(1)
defset_tf_allow_growth(自我):
import_tensorflow_keras()
config = tf。ConfigProto()
允许增长=真
config . GPU _ options . visible _ device _ list = " 0 "
set_session(tf。会话(配置=配置))
preview_buffer = {}
Defshow(self,image,name=''):#提供预览
尝试:
ifself.arguments.redirect_gui:
path = OS . path . real path(OS . path . dirname(sys . argv[0])
img = '。' gui_preview.png '
imgfile = os.path.join(path,img)
cv2.imwrite(imgfile, image)cv2.imwrite(imgfile,image)
elifself.arguments.preview:
withself.lock:
self . preview _ buffer[name]= image
elifself.arguments.write_image:
cv2.imwrite('_sample_{}。jpg '。格式(名称、图像)
例外情况:
打印(“无法预览样本”)
raisee
培训师. py
下面实现了一个具体的训练:
importtime
importnumpy
from lib . training _ data importtrainingdata generator,stack_images
classTrainer():
Random_transform_args = {#初始化参数
rotation_range': 10,
zoom_range': 0.05,
shift_range': 0.05,
random_flip': 0.4,
}
def__init__(自,模型,fn_A,fn_B,批处理大小,*参数):
self.batch_size = batch_size
self.model =模型
发电机=训练数据发电机(自。random _ transform _ args,160) #读取所需数据
self . images _ A = generator . minibatchab(fn _ A,self.batch_size)
self . images _ B = generator . minibatchab(fn _ B,self.batch_size)
Def train _ one _ step (self,ITER,观众):# train one step
纪元,扭曲_A,目标_A =下一个
纪元,扭曲_B,目标_B =下一个
Loss _ a = self。模特。autoencoder _ a.train _ on _ batch(翘曲_ a,target _ a) #计算损失
loss _ B = self . model . auto encoder _ B . train _ on _ batch(warped _ B,target_B)
打印(“[{0}] [#{1:05d}] loss_A: {2:.5f},loss_B: {3:.5f}”。格式(time . str time(" % H:% M:% S "),iter,loss_A,loss_B),
end='r ')
ifviewer不是无:
查看器(self . show _ sample(target _ A[0:14],target_B[0:14]),“培训”/>
来源:朋友圈视频人物变脸是怎么炼成的?
我们可以看到,经过四个卷积层、扩展层和全连接层,我们开始了整个高档模型。在我们高档的中间,我们进行了编码器和解码器
去切割,从而保证共性与个性的分离。
convert.py
在训练的基础上,现在可以转换图片了。
importcv2
进口
importos
frompathlib导入路径
从qdm导入
fromlib.cli导入目录处理器,完整路径
from lib . utils importBackgroundGenerator,get_folder,get _ image _ paths,rotate_image
fromplugins。插件加载器导入插件加载器
类别转换图像(目录处理器):
文件名= ' '
defcreate_parser(self,subparser,command,deion):
self . optional _ arguments = self . get _ optional _ arguments()
self . parser = submisser . add _ parser(
命令,
help= "将源图像转换为新图像,并交换脸部。",
deion=deion,
epilog= "问题和反馈:
https://github.com/deepfakes/faceswap-playground"
)
#省略参数配置
定义过程(自):#转换和拼接模型
#原创& amp低内存型号配有调整或屏蔽转换器
#注意:GAN预测输出一个遮罩+一个图像,而其他预测只输出一个图像
model _ name = self . arguments . trainer
conv _ name = self . arguments . converter
self.input_aligned_dir =无
model = pluginloader . get _ model(model _ name)(get _ folder(self . arguments . model _ dir),self.arguments.gpus)
if not model . load(self . arguments . swap _ model):
打印('找不到型号!必须提供有效的模型才能继续!)
出口(1)
input _ aligned _ dir = Path(self . arguments . input _ dir)/Path(' aligned ')
if self . arguments . input _ aligned _ dir is notnone:
input _ aligned _ dir = self . arguments . input _ aligned _ dir
尝试:
self . input _ aligned _ dir =[Path(Path)for Path inget _ image _ Path(input _ aligned _ dir)]
iflen(self . input _ aligned _ dir)= 0:
打印('对齐目录为空,不会转换任何面!')
Eli flen(self . input _ aligned _ dir)& lt;= len(self.input_dir)/3:
打印('对齐目录包含的图像数量远远少于输入,您确定这是正确的目录吗?')
除了:
打印('找不到对齐的目录。将转换路线文件中列出的所有面。)
converter = pluginloader . get _ converter(conv _ name)(model . converter(False),
培训师=self.arguments .培训师,
blur _ size = self . arguments . blur _ size,
无缝_克隆=self.arguments .无缝_克隆,
锐化_图像=self.arguments .锐化_图像,
mask _ type = self . arguments . mask _ type,
糜烂_内核_大小=self.arguments .糜烂_内核_大小,
match _直方图= self . arguments . match _直方图,
small _ mask = self . arguments . small _ mask,
avg _ color _ adjust = self . arguments . avg _ color _ adjust
)
batch = background generator(self . prepare _ images(),1)
#框架范围素材...
自框架_范围=无
#分割出帧范围并解析出“最小值”和“最大值”
minmax = {
“最小”:0,#从不小于0的任何帧
“最大”:浮点(“inf”)
}
ifself.arguments.frame_ranges:
self . frame _ ranges =[tuple(map(lambdaq:minmax[q]ifq in max . keys()else int(q),v . split("-"))for v in self . arguments . frame _ ranges]
#最后一个数字regex。我知道regex是hacky,但是它的可靠性很差(tm)。
self . imageidxre = re . compile(r '(d+)(?!。*d)')
foritem inbatch.iterator():
self.convert(转换器,项目)
defcheck_skipframe(self,filename):
尝试:
idx = int(self . imageidxre . findall(文件名)[0])
returnnotany(map(lambda b:b[0]& lt;=idx<。=b[1],self.frame_ranges))
除了:
returnFalse
defcheck_skipface(self,filename,face_idx):
aligned_face_name = '{}_{}{} '。格式(路径(文件名)。词干,face_idx,路径(文件名)。后缀)
对齐_面_文件=路径(自参数.输入_对齐_目录)/路径(对齐_面_名称)
#待办事项:删除文件名向后兼容性的临时修复
bk _ compat _ aligned _ face _ name = ' { } { } { } '。格式(路径(文件名)。词干,face_idx,路径(文件名)。后缀)
bk _ compat _ aligned _ face _ file = Path(self . arguments . input _ aligned _ dir)/Path(bk _ compat _ aligned _ face _ name)
returnaligned _ face _ file not senself . input _ aligned _ dir和k _ compat _ aligned _ face _ file not senself . input _ aligned _ dir
defconvert(自身、转换器、项目):
尝试:
(文件名、图像、面孔)=项目
skip = self.check_skipframe(文件名)
if self . arguments . discard _ frames and kip:
返回
ifnotskip: #正常处理框架
foridx,face infaces:
if self . input _ aligned _ dir isnotnoneandself . check _ skip face(文件名,idx):
打印(框架{}的面{}已删除,跳过)。格式(idx,os.path.basename(filename)))
继续
#在映射面之前,检查图像旋转和旋转
ifface.r!= 0:
高度,宽度= image.shape[:2]
image = rotate_image(image,face.r)
image = converter . patch _ image(image,face,64if " 128 " not senself . arguments . trainer else 128)
# TODO:64和128之间的这个切换目前是一个黑客。对于大小,我们应该有一个单独的cli选项
image = rotate_image(image,face.r * -1,rotated_width=width,rotated_height=height)
else:
image = converter . patch _ image(image,face,64if " 128 " not senself . arguments . trainer else 128)
# TODO:64和128之间的这个切换目前是一个黑客。对于大小,我们应该有一个单独的cli选项
output _ file = get _ folder(self . output _ dir)/Path(filename)。姓名
cv2.imwrite(str(output_file),image)
例外情况:
打印('转换图像失败:{}。原因:{} '。格式(文件名,e))
defprepare_images(自):
self.read_alignments()
is _ has _ alignments = self . has _ alignments()
for filename int qdm(self . read _ directory()):
image = cv2.imread(文件名)
ifis _ have _ alignments:
ifself.have_face(文件名):
faces = self.get _ faces _ alignments(文件名,图像)
else:
tqdm . write({找不到}的对齐方式,跳过)。格式(os.path.basename(filename)))
继续
else:
faces = self.get_faces(图像)
yieldfilename,image,faces
当然,我们也可以用GAN算法进行优化,那么我们来看看使用GAN的模型。
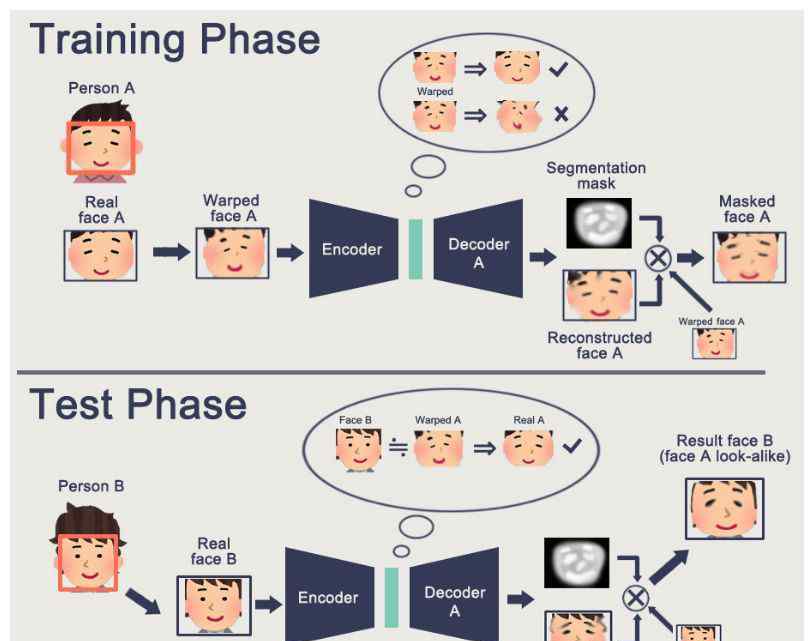
(资料来源:邵安路/faceswap-GAN)
如上图所示,我们首先推导出A的人脸,然后对其进行变换,再经过编码和解码,生成重构的人脸和Mask。以下是我们的学习目标。
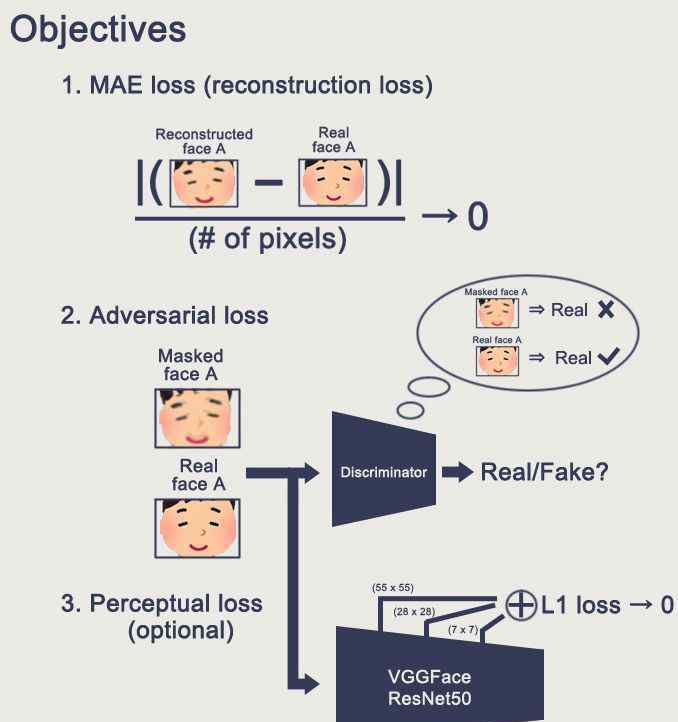
(资料来源:邵安路/faceswap-GAN)
从图片到视频
根据我们对FFmpeg的解释,我们可以使用以下命令将一批图片组合成一个视频:
ffmpeg-f image2-I imagename % 04d . jpg-vcodec libx 264-CRF 15-pix _ fmt YUV 420 p output _ filename . MP4
如果希望新生成的视频有声音,可以将音频视频中的声音拼接到最终的目标视频。
云平台部署
我们可以在谷歌云部署云平台。详情请看视频秀。我将在这里展示几个关键步骤:
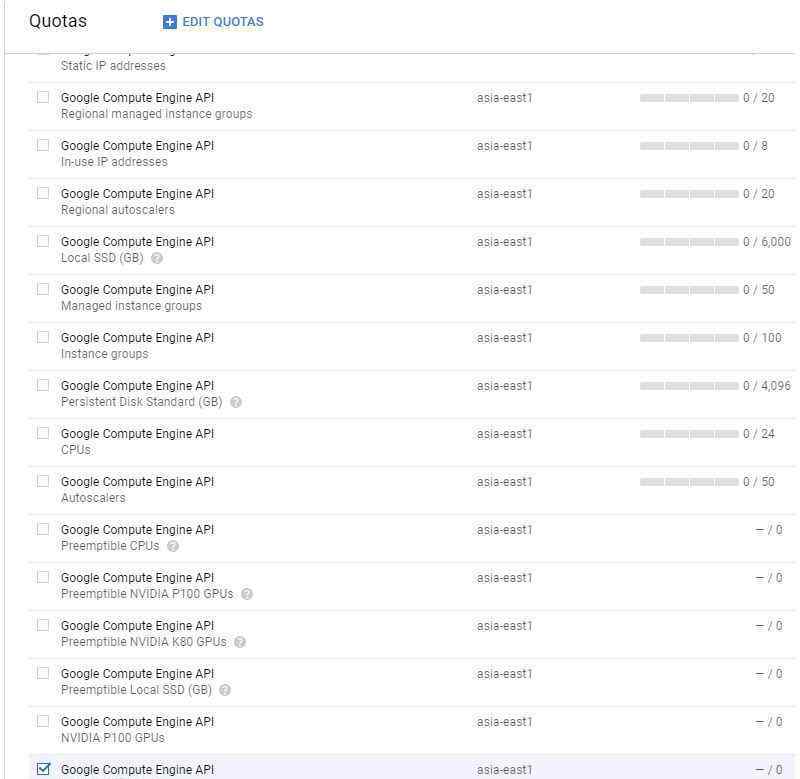
(来源:如何用谷歌云GPU服务创建深度假货)
(来源:如何用谷歌云GPU服务创建深度假货)
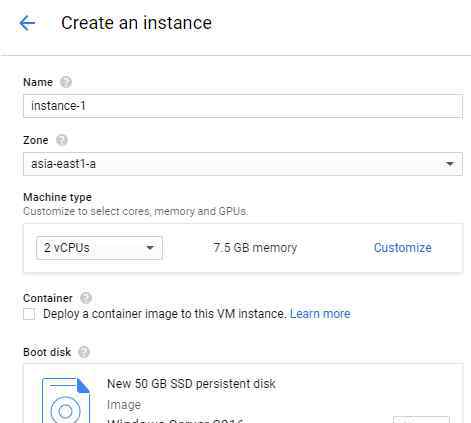
(来源:如何用谷歌云GPU服务创建深度假货)
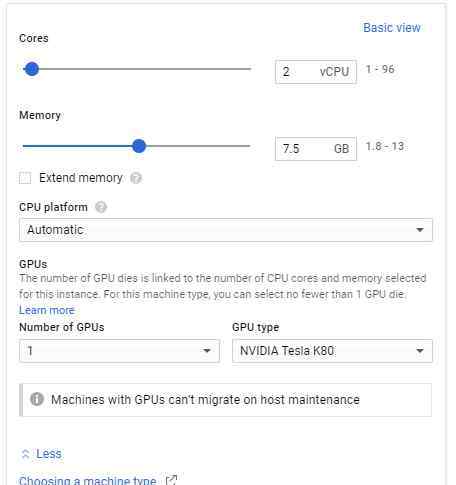
(来源:如何用谷歌云GPU服务创建深度假货)
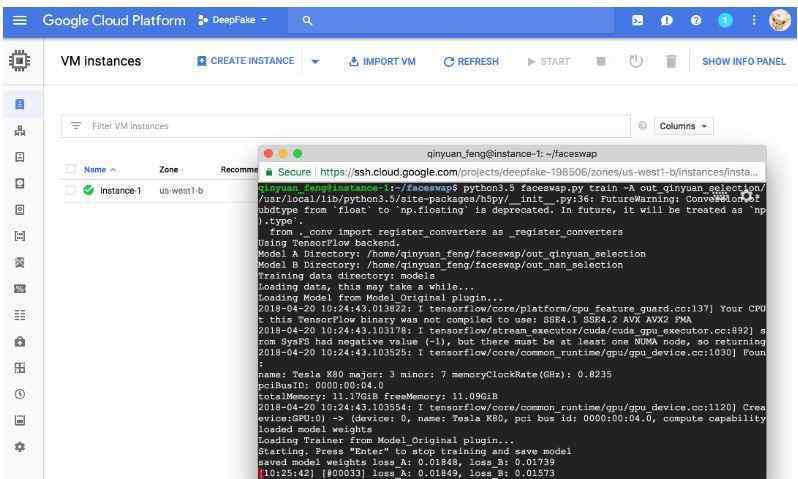
最后是我在Google Cloud上培训的截图。
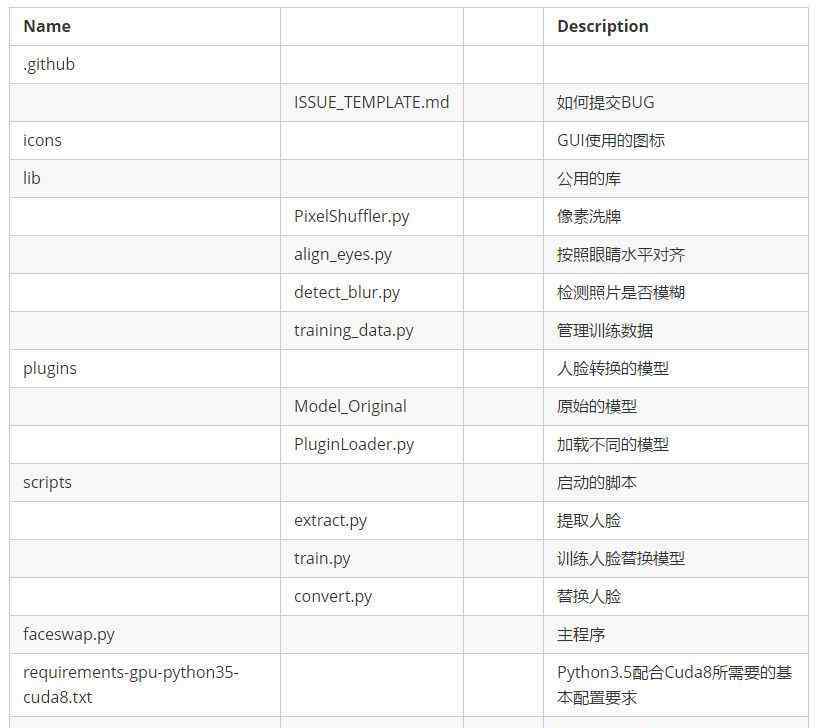
项目架构
最后,让我们从一个较高的层次来理解整个DeepFake项目的架构。
社会影响
我们已经谈过Deepfake的原理,那么它真正的社会价值是什么?我们可以和任何人一起拍电影,然后成为我们想要的任何人。我们可以创造出更逼真的虚拟人物。穿衣购物可以更逼真的模拟。
摘要
我们使用了以下技术堆栈、框架和平台:
Dlib:基于 C++的机器学习算法库 OpenCV:计算机视觉算法库 Keras:在底层机器学习框架之上的高级 API 架构 TensorFlow:Google 开源的机器学习算法框架 CUDA:Nvidia 提供的针对 GPU 加速的开发环境Google Cloud Platform:Google 提供的云计算服务平台 Virtualenv:创建独立的 Python 环境 FFmpeg:多媒体音视频处理开源库现在就来上手,把你心爱的另一半的人脸搬上好莱坞吧。这篇文章是为机器的心脏而发表的。请联系本微信官方账号进行授权。
1.《换脸视频 教程 | 如何使用DeepFake实现视频换脸》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《换脸视频 教程 | 如何使用DeepFake实现视频换脸》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/guoji/1378980.html







