1.全球英语课文-现代英语之路 16世纪末,大约有500万到700万人说英语。他们几乎都住在英国。在下一个世纪的晚些时候,来自英国的人进行了征服世界其他地方的航行,正因...

3月29日,谷歌翻译的Android和iOS App更新到5.8版。对于国内用户来说,新版谷歌翻译App终于可以正常使用了。 @Google Blackboard说: 新版谷歌翻译App在英文和韩文之...

科技巨头谷歌在谷歌助手上推出了文章阅读功能,适合安卓5.0及以上版本的用户。用户只需要说“嘿谷歌,看”或者“嘿谷歌,看这个页面”,谷歌助手就会为用户阅读屏幕上的...









上网查查,有病没病! 站着不动也是绝症! 你咳一咳,再上网查查,绝对是肺结核! 我发烧了,上网查一下肯定是埃博拉,半天就凉了! 留个鼻涕,上网查查。是脑膜炎。你的大脑在爆浆! ...

这篇文章将是我们格莱德系列的最后一篇文章。 事实上,在撰写本系列的第一篇文章时,Glide发布了4.0.0的RC版本。当时因为一直在学习Glide 3.7.0版本,而RC版本不稳定,所...





全球贸易平台Global eTrade Services (GeTS)宣布中外运集装箱运输有限公司(中外运集装箱运输有限公司)正式入驻开放、中立、可靠的全球供应链集成平台CALISTATM。...

我们经常在课文中谈论和听到许多表达,但它们实际上是错误的!不信!大家一起看看吧! 用英语怎么说? 这种说法真的是非常典型的中式英语!错误是由句子成分不完整和缺乏主...

谷歌已经成为出口企业海外推广的最重要渠道之一。由于谷歌覆盖了全球104个国家,所以谷歌是买家在受众和覆盖面方面查找信息的使用率最高的网站。 其中Google竞价广...
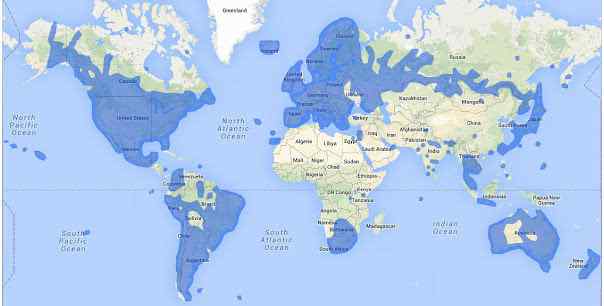
Google推出街景服务八年来,主要功能从地理查询扩展到地理观光。两年前,谷歌街景服务在50个国家登陆,覆盖超过500万英里。从亚马逊热带雨林到庞贝古城遗址,从科罗拉多...
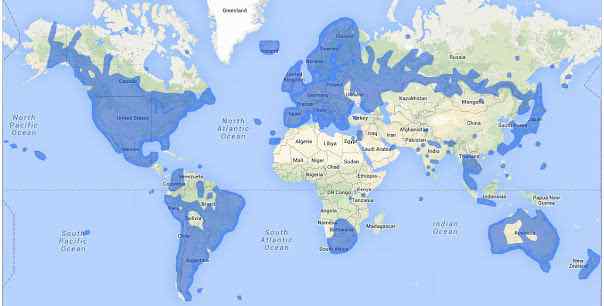
Google推出街景服务八年来,主要功能从地理查询扩展到地理观光。两年前,谷歌街景服务在50个国家登陆,覆盖超过500万英里。从亚马逊热带雨林到庞贝古城遗址,从科罗拉多...
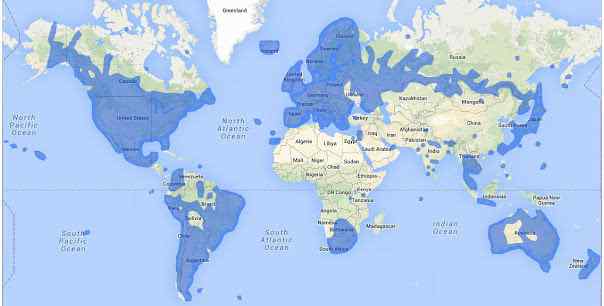
Google推出街景服务八年来,主要功能从地理查询扩展到地理观光。两年前,谷歌街景服务在50个国家登陆,覆盖超过500万英里。从亚马逊热带雨林到庞贝古城遗址,从科罗拉多...

据外媒报道,今天(当地时间9月5日),谷歌在IFA宣布,将为谷歌助手推出一项新功能:环境模式。这种模式将在即将推出的新安卓手机和平板电脑中将其转变为类似于Google Nes...