

《机器人圈》指南:关于深度学习现在在AI领域扮演重要角色。怎样才能学好深度学习?Piotr Migda拥有量子物理学博士学位,是一名数据科学自由职业者。他积极参与天才教育,开发量子游戏,并在deepsense.io上担任数据科学讲师。他在深度学习方面有着非凡的教学经验。让我们从机器人圈开始学习。
人做事情往往是有一定目的的。对于深度学习来说,无论你是开始创业,还是只是想探索(比如检测可疑物体),或者只是机器接管世界前的一个玩笑,都可以在这篇文章中找到你想要的答案。本文的目的不是提供神经网络教学本身的概述,而是指出有用的资源。
不要怕人工神经网络——启动容易!如果你真的想开始学习,你需要的只是真正的基础编程,非常简单的数学知识和几个机器学习概念的知识。接下来我就从这些要求开始逐一讲解。
在我看来,最好的办法是从高级交互模式(另见:高中生量子力学教材和光子量子游戏。所以我建议从Keras的图像识别任务开始,这是一个比较流行的Python神经网络库。当然,如果你想用比Keras更少的代码训练神经网络,唯一可行的选择就是用鸽子。是的,我是认真的:鸽子在识别癌症方面堪比人类科学家!
什么是深度学习?怎么这么爽?
深度学习是使用多层人工神经网络的机器学习技术的名称。人们经常使用人工智能这个术语,但除非你想听起来像科幻小说,否则它只适用于目前被认为“对机器来说太难了”的问题,这是一个快速发展的前沿领域。这是近几年爆炸式发展的一个领域,尤其是在视觉识别任务(包括很多其他任务)方面。参见:
电子前沿基金会对人工智能研究进展的衡量(2017)
与量子计算或核聚变不同,它是一种应用技术,而不是未来的某种可能性。有一个经验法则:
正常人一秒钟能完成的任何操作,现在都可以通过AI自动化来完成。吴恩达在推特上说。
有些人甚至更进一步,把这种说法延伸到科学家身上。谷歌和Facebook等公司如今处于领先地位并不奇怪。事实上,每隔几个月,我都会对超出我预期的事情感到惊讶,比如:
循环神经网络(RNN)在维基百科条目和LaTeX文章中生成虚假莎士比亚风格文章的不合理有效性。
艺术风格转移的神经算法(视频!)
实时人脸捕捉和再现
彩色图像着色
用于现实图像生成的即插即用生成网络
皮肤科医生对皮肤癌的分类和其他医学诊断工具
图像翻译(pix2pix)-从草图到照片
用机器人画猫、狗等动物的草图
看起来像是某种巫术。如果你好奇什么是神经网络,请观看以下系列视频,获得系统介绍:
斯蒂芬·韦尔奇揭示了神经网络
阿拉玛的视觉和互动神经网络基础指南
这些技术都是数据饥渴的。在希格斯数据集上查看逻辑回归、随机森林、深度学习的AUC评分曲线(数据点以百万计):

一般来说,即使有大量的数据,深度学习也比其他技术好,比如随机森林或者增强树。
让我们试一试!
我需要一些天网来运行吗?当然不是——像其他软件一样,你甚至可以在浏览器中完成:
TensorFlow游乐场用于点分离,并具有可视界面
ConvNetJS用于数字和图像识别
Keras.js演示—在浏览器中可视化和使用真实网络(例如,ResNet-50)
或者,如果你想在Python中使用Keras,请参考这个最小的例子——只是为了确保你可以在自己的电脑上使用。
Python与机器学习
我提到了基本的Python和机器学习作为需求。这些都包含在Python中的数据科学、统计学和机器学习的介绍中。
对于Python来说,如果你已经有了Anaconda发行版(覆盖了大部分数据科学软件包),你需要做的就是安装TensorFlow和Keras。
说到机器学习,在开始学习深度学习之前,不需要学习很多技能。然而,如果一个给定的问题可以用更简单的方法解决,这将是一个很好的做法。例如,随机森林通常可以被视为开锁工具,这在许多问题上是现成的。你需要知道的是我们为什么要训练然后测试分类器(验证其预测能力)。为了得到它的要点,从这个漂亮的基于树的动画开始:
Stephanie Yee和Tony Chu的《机器学习的视觉介绍》
另外,了解logistic回归也是一个不错的选择,这是几乎任何神经网络分类的基础。
数学
深度学习(即多层次的神经网络)主要使用非常简单的数学运算。这里有几个例子,你几乎可以在任何网络上找到(看看这个列表,请不要害怕):
向量、矩阵、多维数组
加法,乘法
盘绕提取和处理本地模式
激活功能:sigmoid、tanh或relu添加非线性
Softmax将向量转换为概率
对数损失(交叉熵)聪明地惩罚错误的猜测(也见库尔巴克-莱布勒散度解释)
梯度和链式规则(反向传播)用于优化网络参数
随机梯度下降及其变体(如动量)。
如果你的专业背景是数学、统计、物理或者信号处理——很有可能你已经知道足够的知识可以开始学习了!
如果你最后一次接触数学是在高中,别担心。其实数学很简单,数字识别的卷积神经网络可以在电子表格中实现(不用宏)。请参考:带ExcelNet的深度电子表格。这只是一个原则性的解决方案——不仅效率低下,而且缺乏最关键的部分——培训新网络的能力。
向量运算的基础不仅对于深度学习很重要,对于很多其他的机器学习技术也很重要(比如我写的word2vec中)。要理解它,我建议从以下其中一个开始:
J·斯特罗姆、k·斯特罗姆和t·阿克宁-穆勒的沉浸式线性代数——一本具有完全交互式图形的线性代数书
应用数学和机器学习基础:深度学习书籍中的线性代数
布兰登·福瑟深度学习线性代数作弊表
既然书中很多地方都引用了NumPy,那么学习它的基础知识一定很有用:
尼古拉斯·罗杰尔《从Python到Numpy》
科学课:数字数组对象
同时,回忆一下其中包含的道理,就像数学家想的那样。从神奇的工作代码开始,绝对可以像乐高积木一样处理神经网络层。
结构
有几个深度学习库很受欢迎,包括TensorFlow,茶诺,Torch,Caffe。他们各有一个Python接口(当然现在Torch里也有pyTorch)。
那么,我们应该选择哪一个呢?第一,和往常一样,忘记所有细微的性能基准,因为过早的优化才是万恶之源。最重要的是从一个容易写(读)的开始,一个有很多在线资源的,一个可以安装在你电脑上没有太多bug的。
记住,核心框架是一个支持GPU的多维数组表达式编译器。当前的神经网络可以表示如下。但是,如果只是想用神经网络,通过最小功率规则,我建议从神经网络框架入手。例如...
Keras
如果你喜欢Python哲学(简洁,可读,首选方法),Keras就是为你量身定做的。它是一个先进的神经网络库,使用张量流或Anano作为后端。另外,如果你想有一个宣传屏,可能会有一个偏(或者说过分贴合)的排名:
深度学习框架状态(来自GitHub指标),2017年4月。——弗朗索瓦·乔克(Keras的创造者)

如果想咨询不同来源,基于arXiv文件而不是GitHub的活动,请参考Andrej Karpathy的机器学习动态。人气很重要,也就是说如果要搜索一个网络架构,搜索它(比如UNet Keras)可能会返回一个例子。那么应该从哪里开始学习呢?关于Keras的文档很好,它的博客是很有价值的资源。关于在Jupyter笔记本中使用Keras深度学习的完整交互介绍,真的推荐你去看看:
Valerio Maggio写的基于Keras和TensorFlow的深度学习
如果您想要更短的,请尝试以下方法之一:
埃里克·雷佩尔的书的一部分,使用喀拉斯和猫来可视化卷积神经网络
贝塔罗维奇作品《完全初学者的深度学习:基于Keras的卷积神经网络》
使用Python中复杂神经网络的手写数字识别
Keras有几个附件,对学习它特别有用。我为顺序模型创建了ASCII摘要来显示网络中的数据流(与
model.summary()
更好)。它显示层数、数据维度(x、y、通道)和空闲参数数量(待优化)。例如,对于用于数字识别的网络,它可能如下所示:
操作数据尺寸重量(N)重量(%)输入# # # # 32 32 3 Conv2D |/-896 0.1% relu # # # # 32 32 32 Conv2D |/-9248 0.7% relu # # # # # 30 32 max pool 2D Y max-0 0.0% # # # # # 15 15 32 drop | | |-0.0% # # # 15 15 32 Conv2D |/-18496 1.5% relu # # # # # # |/-36928 3.0% relu # # # # 13 13 64 maxpool 2d Y max-0 0.0% # # # # 6 6 64 drop | |-0 0.0% # # # # 6 64扁平化| | | | | | | | |-0 0.0% # # # # # 2304密集XXXXX-1180160 94.3% relu # # # # # 512 drop | | |-0.0% # # # # # 512密集XXXXX - 5130
你可能也有兴趣用keras-tqdm的更好的进度条,用颤探索每一层的激活功能,用keras-vis检测注意力映射或者把keras模型转换成Java,在Keras.js浏览器中运行。说语言,还有一个R接口给Keras。
张量流
如果不是Keras,那么我建议从单个TensorFlow开始。这是一个更低级更啰嗦的工具,但是可以直接优化各种多维数组(和张量)运算。以下是一些不错的资源:
官方的TensorFlow教程很不错
马丁·诺尔作品中的张量流和深度学习。
艾默里克·达米安的TensorFlow教程和初学者示例(使用Python 2.7)
内森·林茨使用谷歌张量流框架的简单教程
无论如何,TensorBoard都可以轻松跟踪培训过程。也可以通过回调和Keras一起使用。
其他的
antano和TensorFlow差不多,但是有点老,比较难上手。例如,您需要手动编写对变量的更新。典型的神经网络图层不包括在内,所以常用的是Lasagne之类的库。如果你想找个地方开始,我喜欢下面的介绍:
马雷克·赖作品的入门教程
同时,如果你在Torch或者PyTorch中看到一些好的代码,不要害怕安装运行!
数据集
每一个机器学习问题都需要数据。你不能只告诉它“检查这张照片里有没有猫”就指望电脑告诉你答案。你需要展示很多猫的例子和没有猫的图片,(希望)它会学会把它们推广到其他情况。所以,你需要一些数据来开始。这不是机器学习或者深度学习的缺点——这是任何学习的基本属性!
在潜入未知水域之前,先看看一些流行的数据集。其中最关键的部分就是很受欢迎。这意味着你可以找到很多例子。并保证这些问题可以通过神经网络解决。
手写数字识别
许多好的想法在MNIST是行不通的(比如批量规格)。相反,许多不好的想法可能会在MNIST身上奏效,而不会被转移到真正的[计算机视觉]上。
弗朗索瓦·乔莱特的推特
但是,我建议从keras.datasets中包含的MNIST数字识别数据集(60k灰度28x28图像)开始,你不需要掌握它,只是为了得到它的工作原理(或者在本地机器上测试keras的基础知识)。
不是清单
其实我曾经指出过,AI工作者面临的最大挑战就是回答这个问题:什么是“A”和“我”?
——道格拉斯·霍夫斯塔德(1995)
一个比较有趣的数据集,对于经典的机器学习算法来说比较难,就是notMNIST(字母A-j来自奇怪的字体)。如果你想从它开始,这里是我的代码,不是Keras中的MNIST加载和逻辑回归。
研究中心
如果对图像识别感兴趣,有CIFAR数据集和32x32照片数据集(也可以在keras.datasets中找到)。它有两个版本:10个简单的课程(包括猫、狗、青蛙和飞机)和100个更困难和微妙的课程(包括海狸、海豚、水獭、海豹和鲸鱼)。我强烈建议从CIFAR-10开始,一个简单的版本。小心,更复杂的网络可能要花相当长的时间(我7岁的时候在Macbook Pro的CPU上运行了12个小时)。
更多的
深度学习需要大量数据。如果您想从头开始训练网络,即使是在低分辨率(32x32)下,您也可能需要多达10k个图像。尤其是数据很少的情况下,并不能保证网络会学到什么。那么如何解决这个问题呢?
使用非常低的分辨率(如果你的眼睛可以看到,你不需要使用更高的分辨率)
获取大量数据(对于256x256这样的图像,可能有数百万个实例)
再培训已经看到了很多网络
生成更多数据(包括旋转、移动和变形)
通常,它是所有提到的东西的组合。
站在巨人的肩上
创建一个新的神经网络与烹饪有很多共同之处——典型的配料(层)和食谱(流行的网络架构)。最重要的烹饪比赛是ImageNet视觉识别挑战赛,它从50万张照片数据集中识别出数百个类别。看看这些神经网络架构,通常使用224x224x3输入(Eugenio Culurciello的图表):
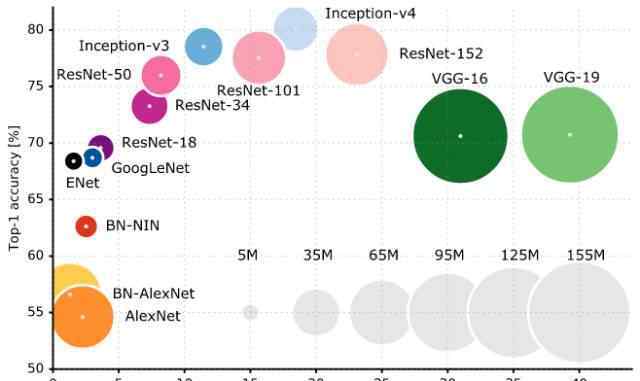
圆的大小代表参数的个数(很多!)。但是没有提到SqueezeNet,这种架构大大减少了参数的数量(比如50倍)。
几个关键的图像分类网络可以很容易地从keras.applications模块加载:Xception,VGG16,VGG19,ResNet50,InceptionV3。其他的不是即插即用的,但是在网上还是很容易找到的——没错,Keras有SqueezeNet。这些网络有两个目的:
它们提供了有用的构件和架构
当使用具有预训练权重的架构时,它们是再训练(所谓的转移学习)的最佳候选
图像的其他重要网络架构:
用于生物医学图像分割的卷积网络
基于Keras的视网膜血管分割和卷积神经网络
Keras用于为Kaggle的超声神经细分比赛提供深入的学习指导
艺术风格的神经算法
在Keras中执行神经风格转移和神经涂鸦——Somshubra Majumdar
美国有线电视新闻网在图像分割中的简史——从“伪美国有线电视新闻网”到“屏蔽美国有线电视新闻网”—— DH Ruv Parthasarathy
另一组意见:
神经网络动物园
如何训练你的深层神经网络——多少层,参数等。
基础
对于非常小的问题(比如MNIST,notMNIST),你可以使用个人电脑——即使是笔记本电脑,计算也是在CPU上进行的。
对于小问题(比如CIFAR,不讲道理的RNN),你还是可以用PC的,但是需要更多的耐心和取舍。
对于中大型问题,基本上唯一的办法就是用一台图形处理器(GPU)功能强大的机器。例如,我们花了2天时间培训一个卫星图像处理模型,以便在Kaggle进行竞争。请参考:
基于图像分割的卫星图像深度学习
在一个强大的CPU上,需要几个星期,请看:
贾斯廷·约翰逊流行的卷积神经网络模型的基准
使用功能强大的GPU最简单最便宜的方法就是每小时租一台远程机。可以用亚马逊(不仅仅是书店!),这里有一些指导方针:
Keras和GPU——在亚马逊EC2上——一步一步的指南,由我的学生Mateusz Sieniawski完成
在AWS上的GPU上运行Jupyter笔记本电脑:弗朗索瓦·乔莱特入门指南
深造
我鼓励你与代码互动。例如,notMNIST或CIFAR-10可以是一个很好的起点。有时候,最好的开始方式是从别人的代码运行,然后看看参数修改后会发生什么。
为了学会操作,这一个是杰作:
CS231n:安德烈·卡帕斯写的卷积神经网络的视觉识别和语音视频
对于书籍,有一个很好的例子,从介绍数学和机器学习的学习环境开始(甚至用我最喜欢的方式覆盖对数损失和熵)!)
《深度学习》,麻省理工学院出版社出版,伊恩·古德费勒、约舒·本吉奥和亚伦·库维尔编辑。
或者,可以使用(可能有利于互动素材的介绍,但我觉得风格有点长):
神经网络和深度学习
其他材料
有很多深度学习应用(不只是图像识别!)。我收集了一些入门资料,涵盖了他们的方方面面(请注意:他们有各种各样的困难)。不要试图把它们都读完——我把它们列为灵感,而不是恐吓!
可读性:
循环神经网络的不合理有效性——安德烈·卡普西
卷积神经网络如何看待世界——Keras博客
当看到善良时,自愿神经网络会看什么——克拉辉博客(NSFW)
——Harish Nrayanan,艺术风格传递的卷积神经网络
梦、医学和康复——我的幻灯片(NSFW),我正在考虑把它变成一个基于常识错误VS人类学习的更长的机器后学习。
技术:
《是的,你应该明白反向传播》——安德烈·卡帕西
基于喀拉斯——普拉卡什·瓦纳帕利的迁移学习
“用50行代码生成对抗网络”(pytorch)
《最小和干净的强化学习示例》
梯度下降优化算法综述——塞巴斯蒂安·路德
风格转换的最佳选择——斯拉夫·伊万诺夫
“在喀拉斯建立自动编码器”——弗朗索瓦·乔莱特
理解长期和短期记忆网络模型(LSTM)-克里斯·奥拉
《RNN与》。《LSTMs》——罗汉·卡普
牛津深度自然语言处理2017课程
资源列表
如何开始学习深度学习-OFIR出版社
深度学习指南—— YN 2
最受欢迎的:
R/MachineLearning Reddit频道涵盖了大部分最新内容
stellet . pub——一个交互式的、可视化的、开放的机器学习研究期刊,附有解释性文章
我的链接在pinboard.in/u:pmigdal/t:deep-learning-although,只能保存,不能自动推荐
@fastml_extra Twitter频道
git XIV-提供文件和代码
不要害怕看学术论文。有些文章写得很好,见解很深刻(如果你有Kindle或者其他电子书阅读器,我推荐Dontprint)。
数据(通常具有挑战性)
Kaggle
根据单导联心电图记录进行房颤分类:2017年心理挑战中的生理网络/计算
2017年动物竞赛(675,000张图片,5000种),参见蘑菇人工智能
希望这篇文章能让你对深度学习有更深的理解。
1.《ker 基于Keras的Deep Learning学习入门指南》援引自互联网,旨在传递更多网络信息知识,仅代表作者本人观点,与本网站无关,侵删请联系页脚下方联系方式。
2.《ker 基于Keras的Deep Learning学习入门指南》仅供读者参考,本网站未对该内容进行证实,对其原创性、真实性、完整性、及时性不作任何保证。
3.文章转载时请保留本站内容来源地址,https://www.lu-xu.com/shehui/1254822.html




